






di腾讯几天前发布混元图像 2.0 模型,创新性地实现了“边说话边出图”、“边打字边出图”的功能,为我们带来了前所未有的交互新体验,那么它的实际能力表现又如何了?现在就为大家实测一波。
目录:
1.腾讯混元图像 2.0 模型介绍
2.腾讯混元图像 2.0 模型开箱评测
2.1 评测核心结论
2.2 实时文生图评测
2.3 实时绘画板评测
1. 腾讯混元图像 2.0 模型介绍
以往的模型生图需要输入完整的 prompt,继而等待图像生成,在等待过程中,如果突然有了新的想法,也只能等图像生成完之后才能看到是不是想要的图片效果。
现在这个难题有了解决方案,腾讯发布混元图像 2.0 模型突破性实现毫秒级实时响应,支持边描述边生成的动态交互。用户输入、修改prompt时,模型实时完成图像重绘,告别传统生成等待耗时。
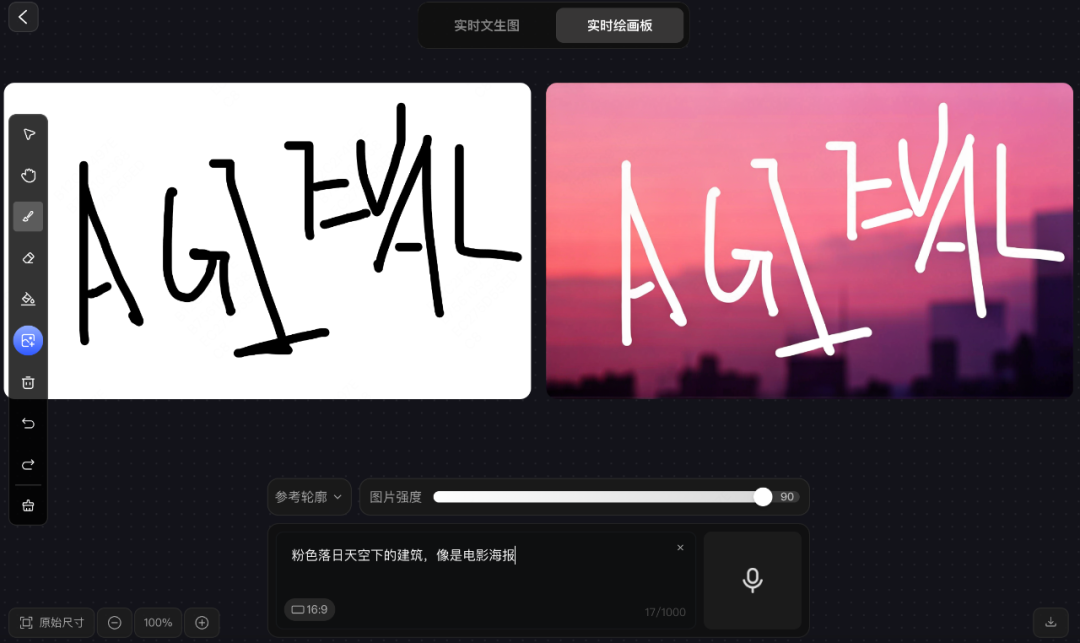
混元图像2.0新增“实时绘画板”功能 。用户手绘元素轮廓 + 文字注释,模型就能即时生成高精度效果图,让创意灵感快速落地为具象画面,让模型生图从“输入提示词-等待模型生成”的线性节奏,变成了输入与输出同步发生的实时交互。
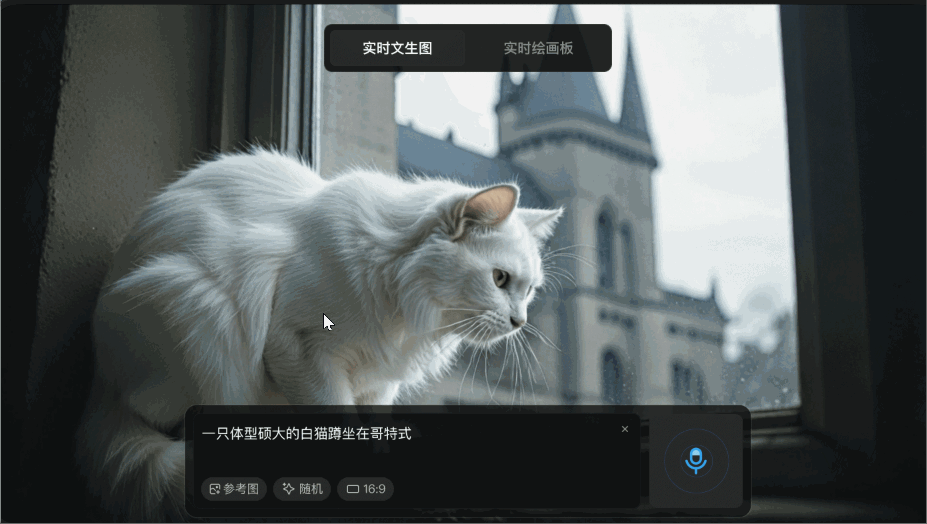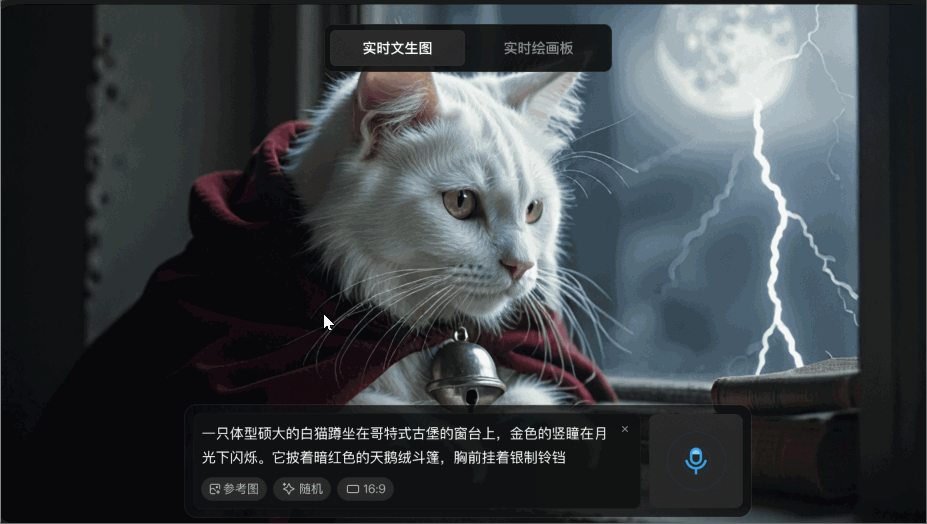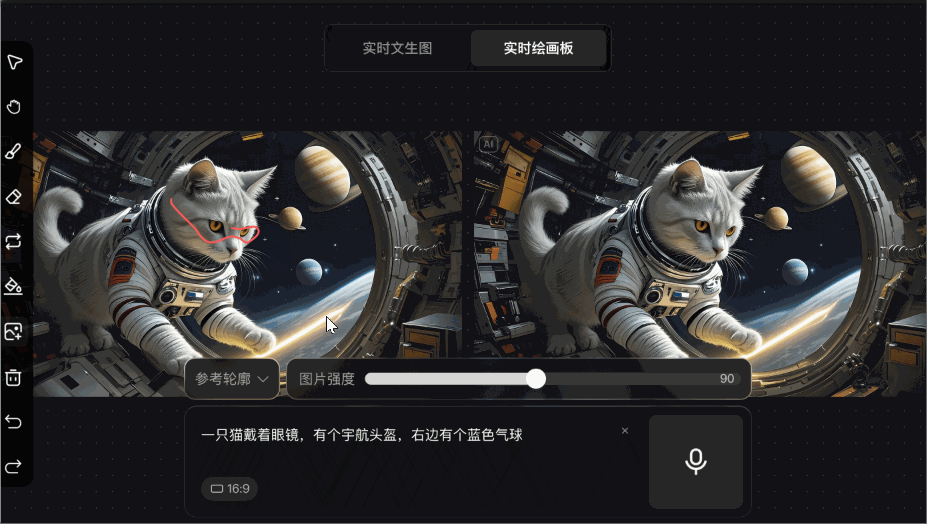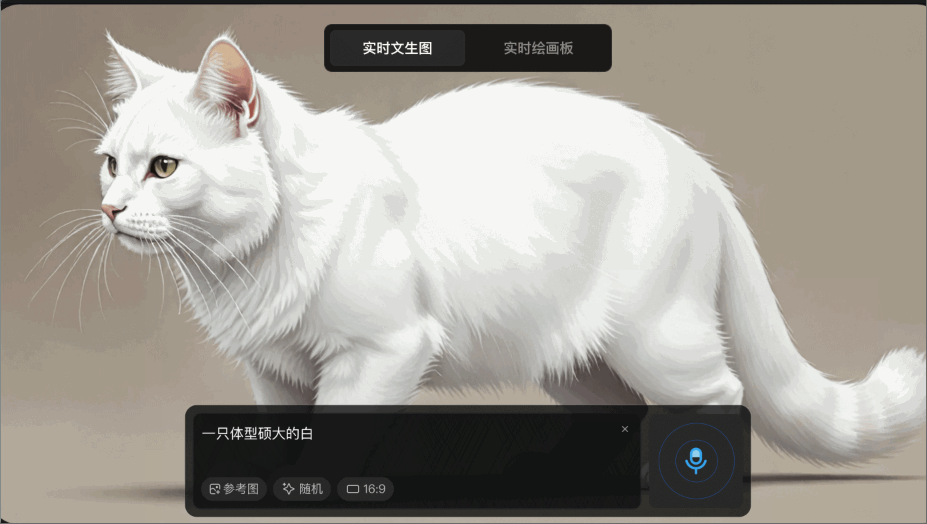
腾讯混元图像 2.0 模型三大亮点
1.效率与质感并行:腾讯混元图像 2.0 模型实现了毫秒级的创作速度和超写实画质,号称是首个商业化毫秒级响应文生图模型,并对图像质感做了系统性重构,可达到高写实效果,可用性高。
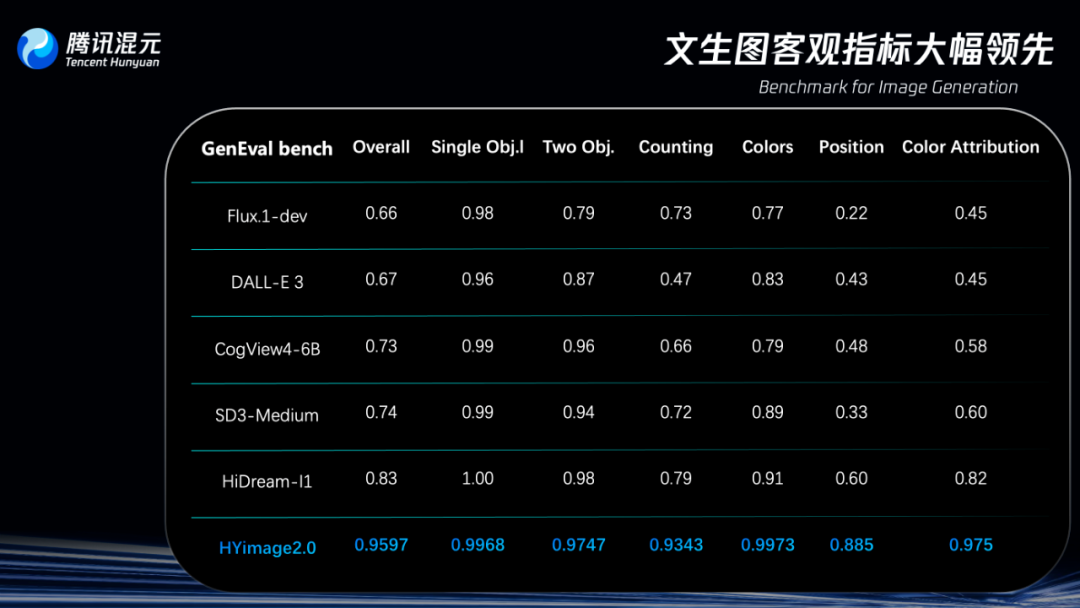
2.多语义理解能力:腾讯混元图像 2.0 模型引入多模态大语言模型(MLLM)作为文本编码器,配合自研的结构化 caption 系统,语义响应速度遥遥领先,在GenEval评测集上,腾讯号称以0.9597超过了所有文生图模型。不仅能理解你在说什么,更能快速推测出你希望画面「怎么表达」。
3.多重使用方式:对于普通创作者而言,只需文字输入或语音说出提示词,无论是做社交配图、教学插图,还是记录灵感片段,模型都能实时生成图像。
对于有设计基础的用户,可以实时画布、多层编辑。用户在左侧绘制线稿,右侧同步生成光影、材质等细节;还支持图层叠加与局部调整,帮助用户从草图到成图「一气呵成」,有效突破传统绘图软件中「绘制-等待-修改」的流程。
模型体验入口:https://hunyuan.tencent.com/
2.模型开箱评测
那么 ,腾讯混元图像 2.0 模型在实测表现中又如何呢?
首先来看本次开箱评测的核心结论。
2.1 评测核心结论
AGI-Eval 大模型评测社区第一时间做了模型评测,评测结论如下:
腾讯混元图像 2.0 模型在实时生成速度和交互模式上实现了一定突破,尤其适合快速获取基础视觉素材或日常娱乐图像。然而,模型输出效果在细节精度、语义理解和真实感方面仍存在一定局限,比如生图存在明显AI感,暂不适合专业性要求较高的办公或设计场景。建议用户根据实际需求权衡使用,优先用于概念生成和创意探索,并结合人工后期处理提升最终图像效果。
2.2 实时文生图评测
那么首先来看实时文生图功能,我们将从无参考图和有参考图两个方向进行评测。
2.2.1 无参考图类型
prompt1:春天,温暖的室内,一只布偶猫蹲在窗户旁看外面的阳光,凝视着窗户外洒落的阳光
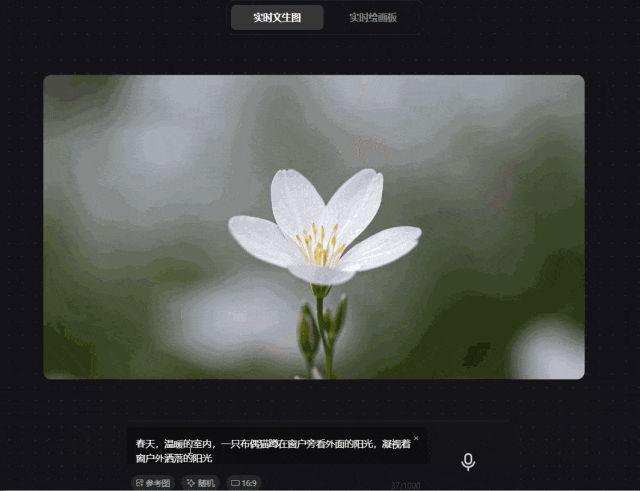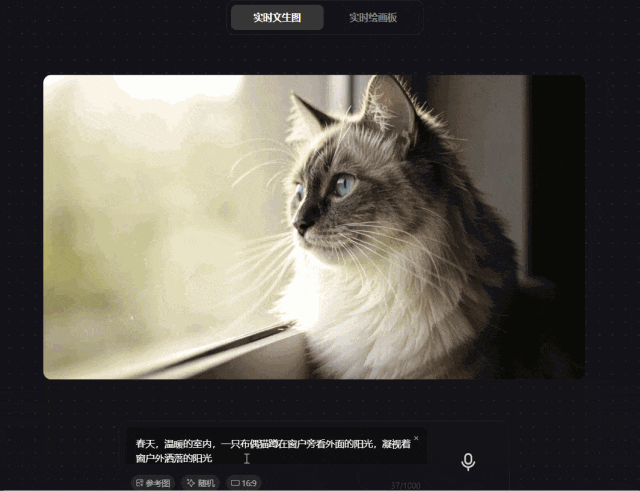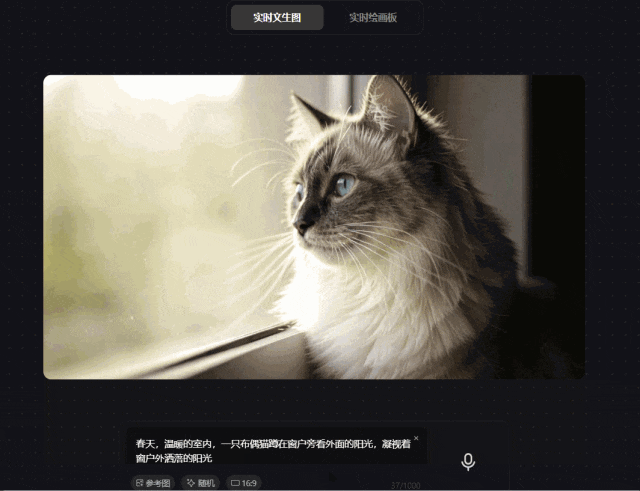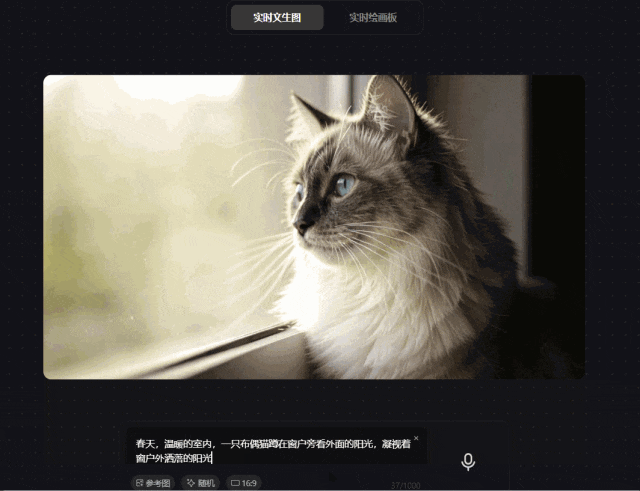
经实测发现,腾讯混元图像 2.0 模型确实可以根据prompt的修改实时生成图像,并且达到毫秒级速度响应。从图中可以看出一只布偶猫在望着窗外,猫种特征明显,动作及窗外置景基本符合prompt的描述。
为了测试腾讯混元图像 2.0 模型的能力边界,我们拓展下 prompt,看生成的画面能否更加丰富。
prompt:春天,温暖的室内,一只布偶猫蹲在窗户旁看外面的阳光,凝视着窗户外洒落的阳光,接着又有一只无毛猫跳了上来,它们俩没有对视,挨着一起,看窗户外一只蓝色蝴蝶,在它们身后,是室内的茶几、茶杯、电视和沙发
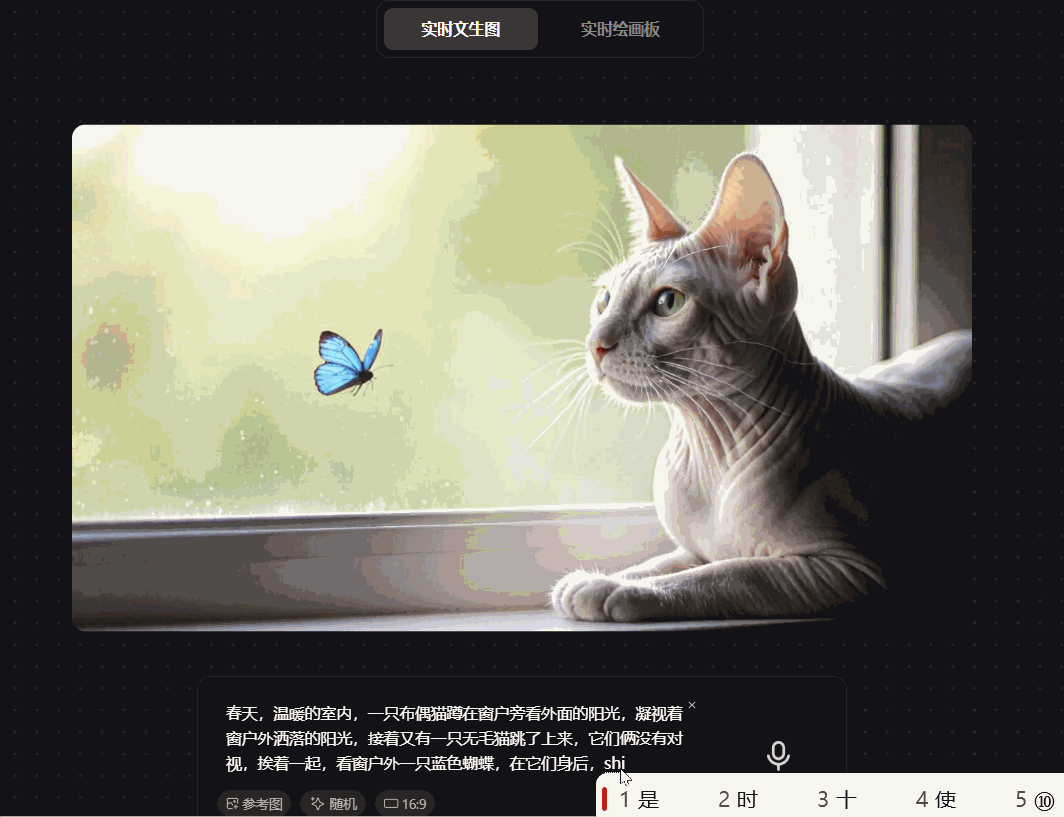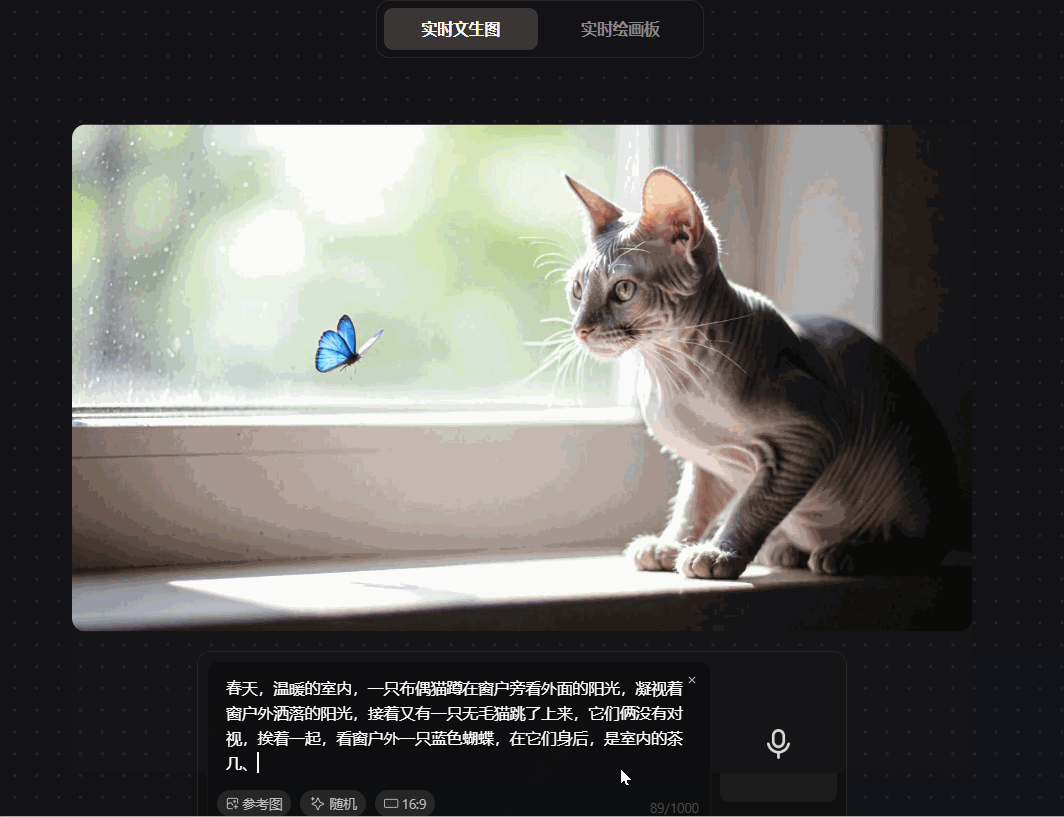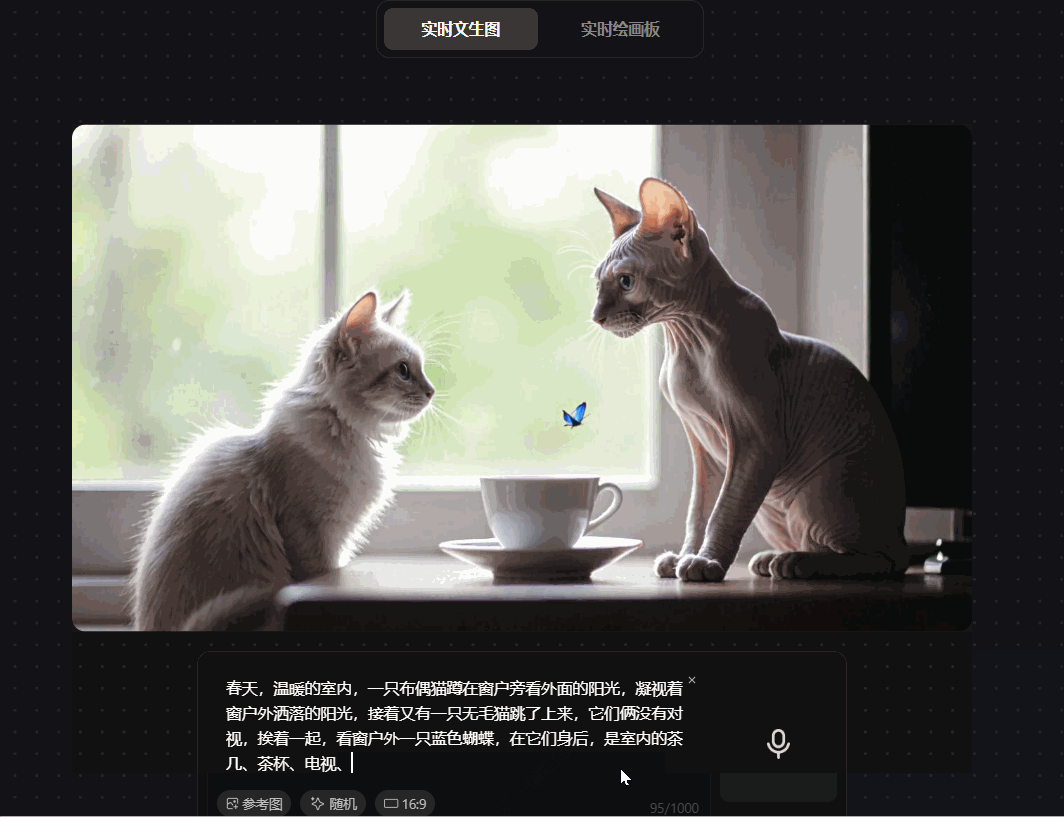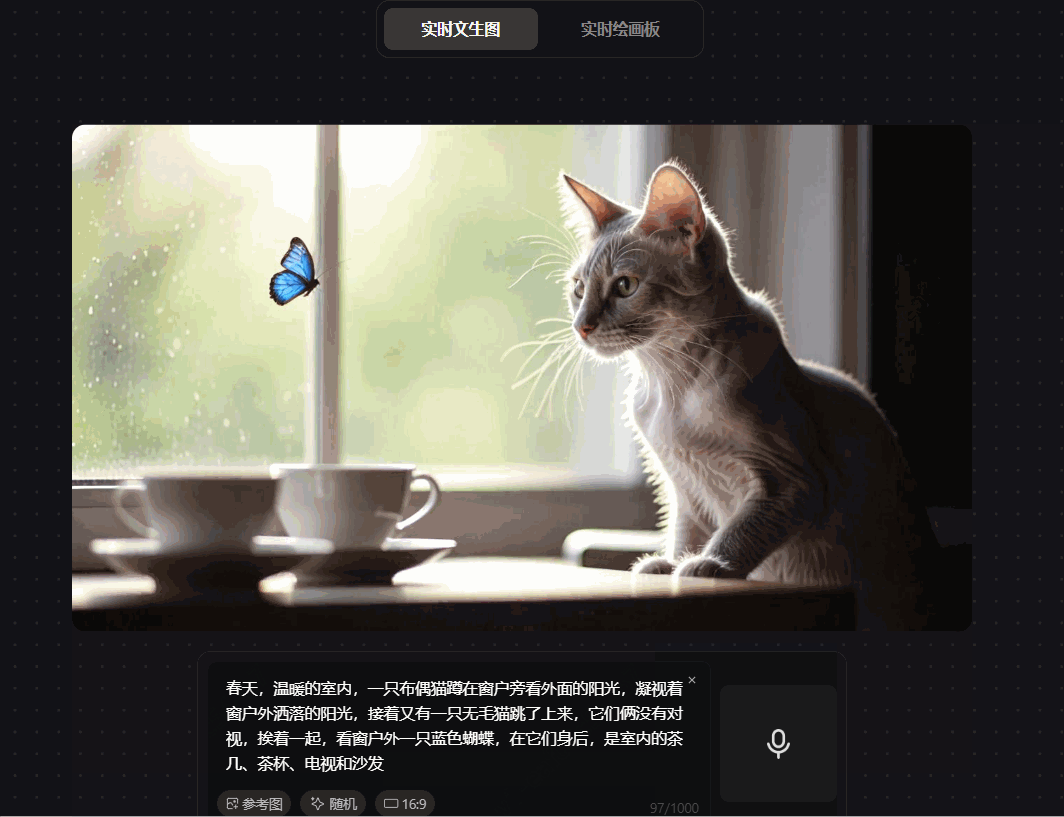
可见,腾讯混元图像 2.0 模型在测试中出现生成图片跟指令不符的情况,画面闪烁不定,输入指令明确为“它俩没有对视”,而画面闪过的两只猫在互相对视;prompt明确是“窗外的蝴蝶”,而画面中的蝴蝶是室内的,图像层次不清晰;并且画面元素缺失,“室内的茶几、电视和沙发”的prompt被吞掉,模型的指令遵循不佳。
从这个测试结果来看,腾讯混元图像 2.0 模型的实时文生图能够基本满足画面生成需求,但其存在较多指令遵循问题,生成的画面也存在较多的细节问题。
prompt 2 :一个餐桌,上面有一口冒着泡泡的田字格火锅,火锅里有很多辣椒,俯视来看,锅的周围摆满了蔬菜和牛肉羊肉毛肚
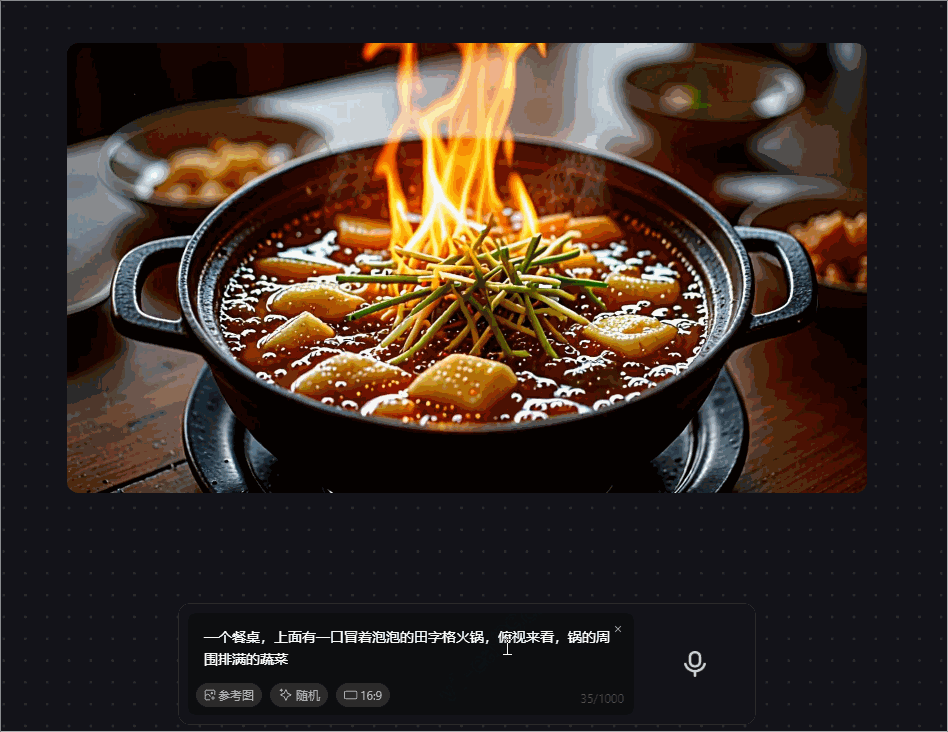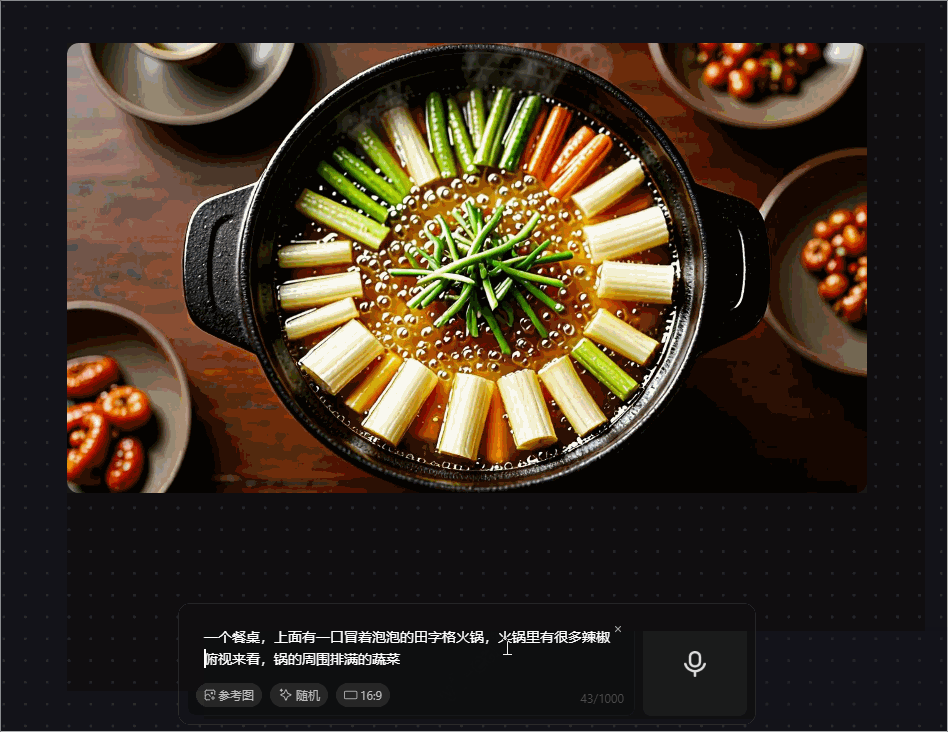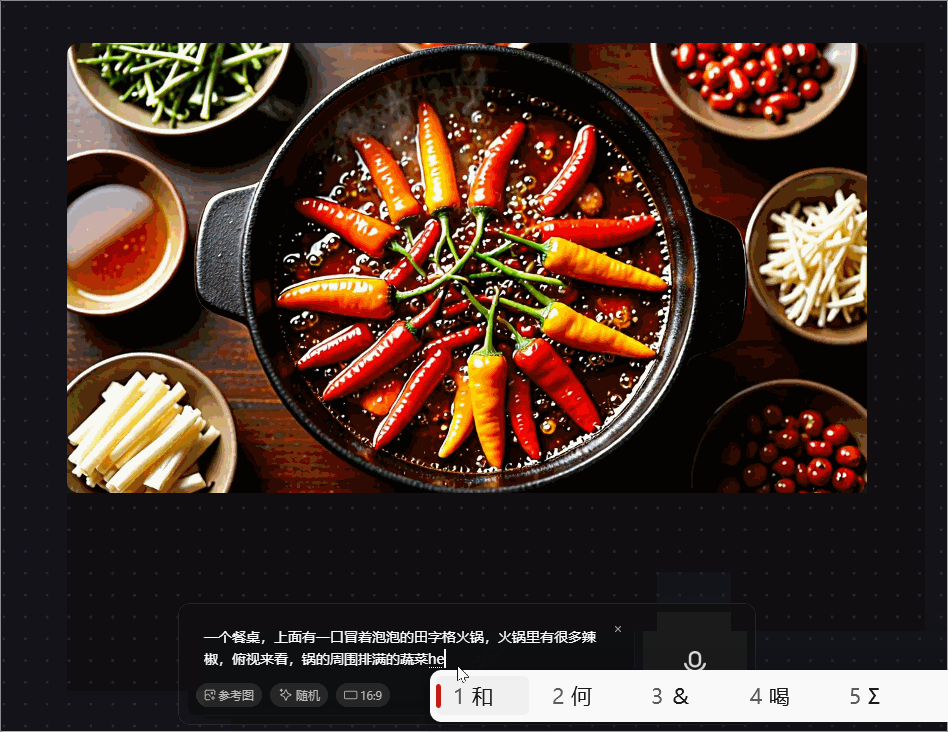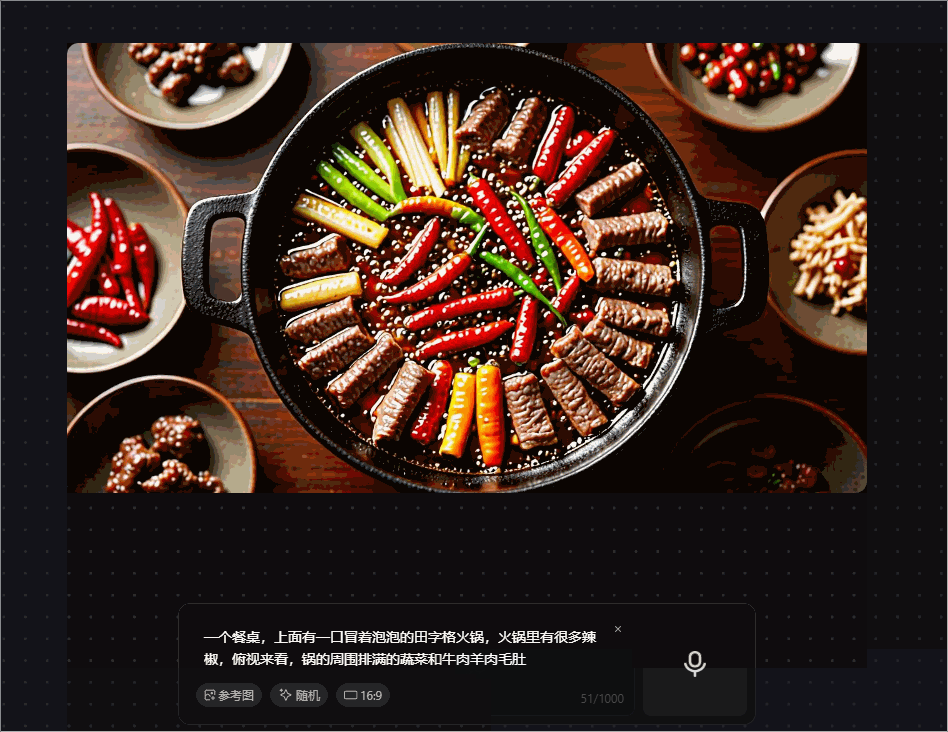
腾讯混元图像 2.0 模型生成的这张火锅图,开始锅里还在冒火,火锅里的辣椒居然可以那么大,与现实场景中的不同,对火锅周围的蔬菜和肉类的生成也不精准,分类模糊,“田字格火锅”的形状也没有呈现出来。
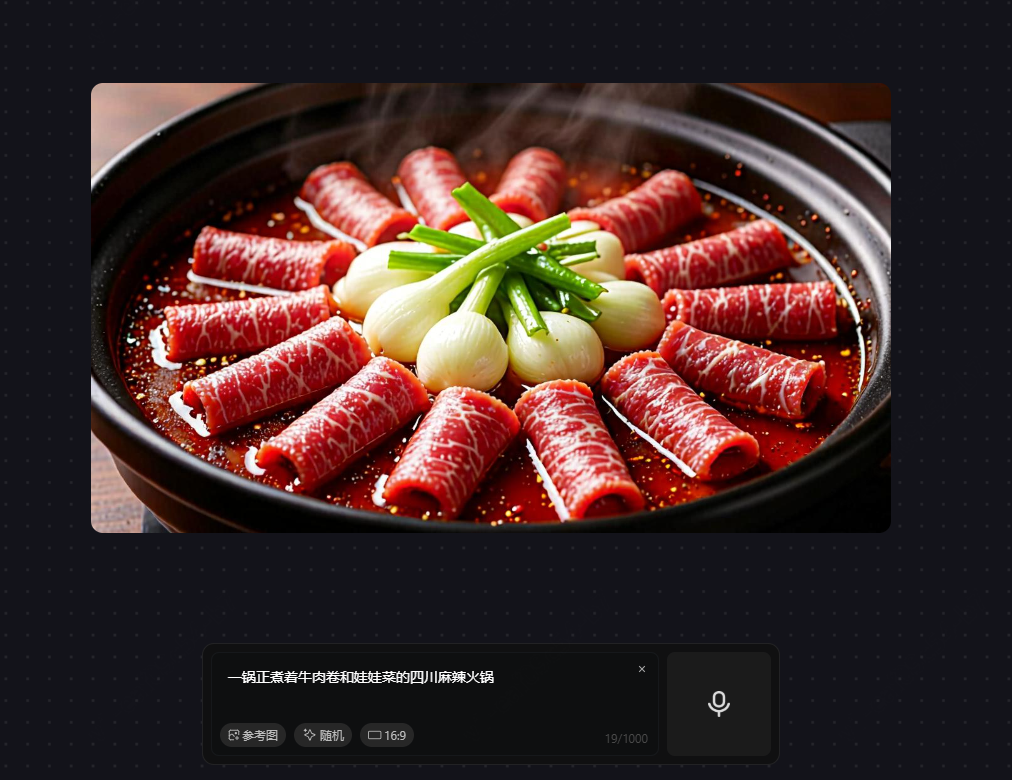
我们特意缩短 prompt,然而模型生成的图像在细节上无法很好地满足需求,甚至存在图文不符的情况,比如要求生成的是娃娃菜,图像生成的是几头蒜,AI味过重。
prompt 3:一辆锈迹斑斑的红色皮卡车,配有白色轮圈
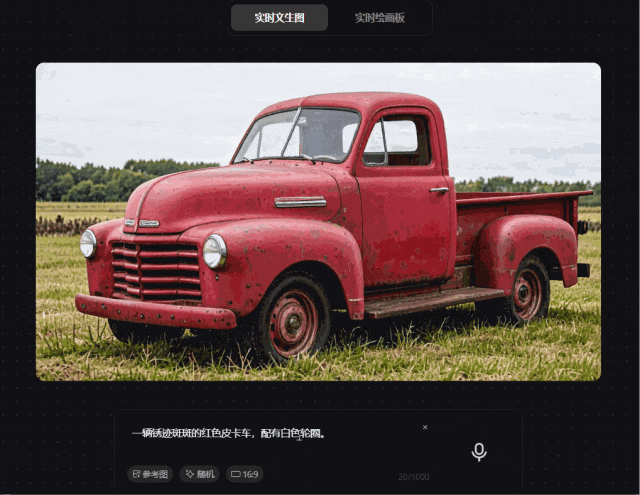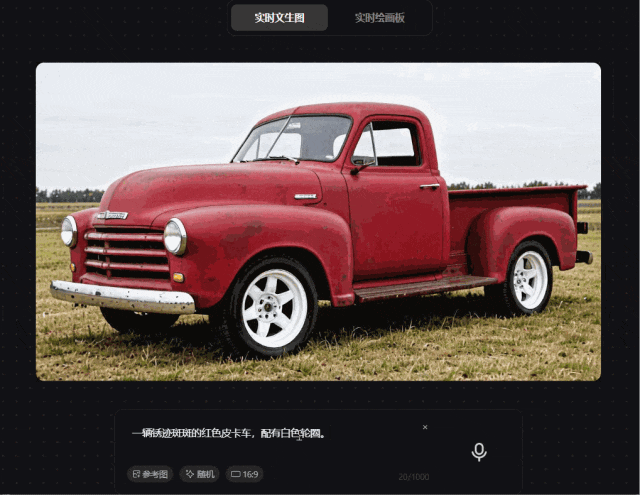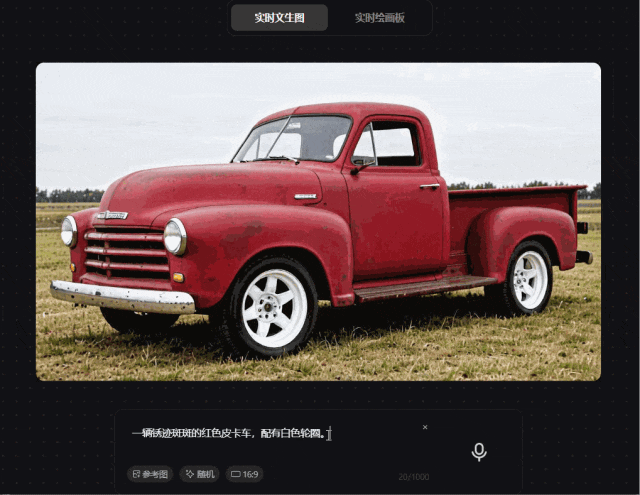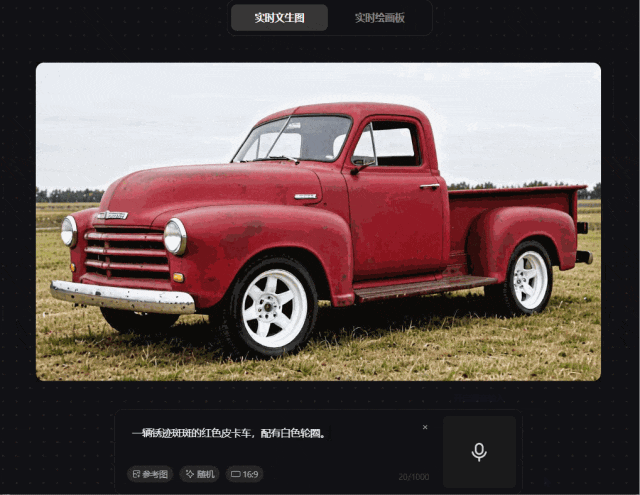
我们为其准备了一个简单的prompt,混元图像 2.0 模型可以快速精准满足需求,质感相对来说较真实。
prompt 4:苹果品牌的logo是一个被咬了一口的苹果,用同样的规律生成一张"香蕉品牌"的logo

腾讯混元图像 2.0 模型生成的这张"香蕉品牌"的 logo 图,在输入完前半句 prompt 时可以满足需求,但明显在语义理解和逻辑推理上存在不足,生成了一张组合图,与我们想要的效果图完全不符。
prompt 5:以行星为主题,按照真实的位置分布和大小比例画出太阳系的八个大行星
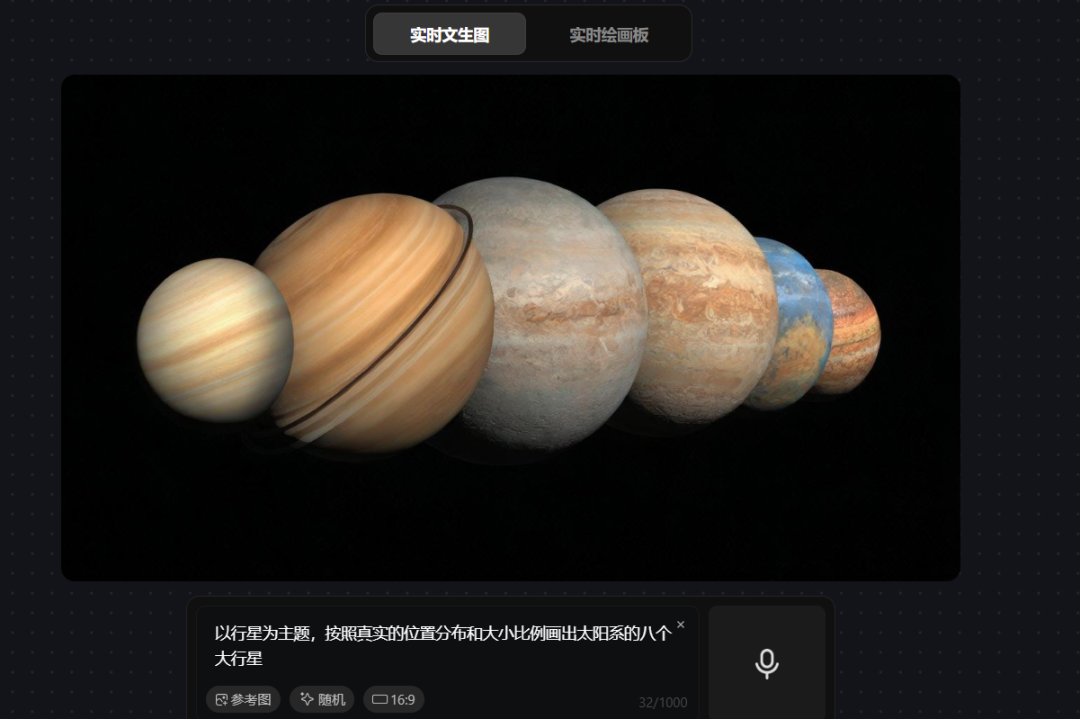
这张图片只画了5个行星,并没有画出太阳系的八个大行星,更没有按照位置排布,对学科知识的掌握弱于GPT-4o。
prompt 6:一张微笑的憨豆先生黑白照,在抽着香烟跟一位女士在交谈
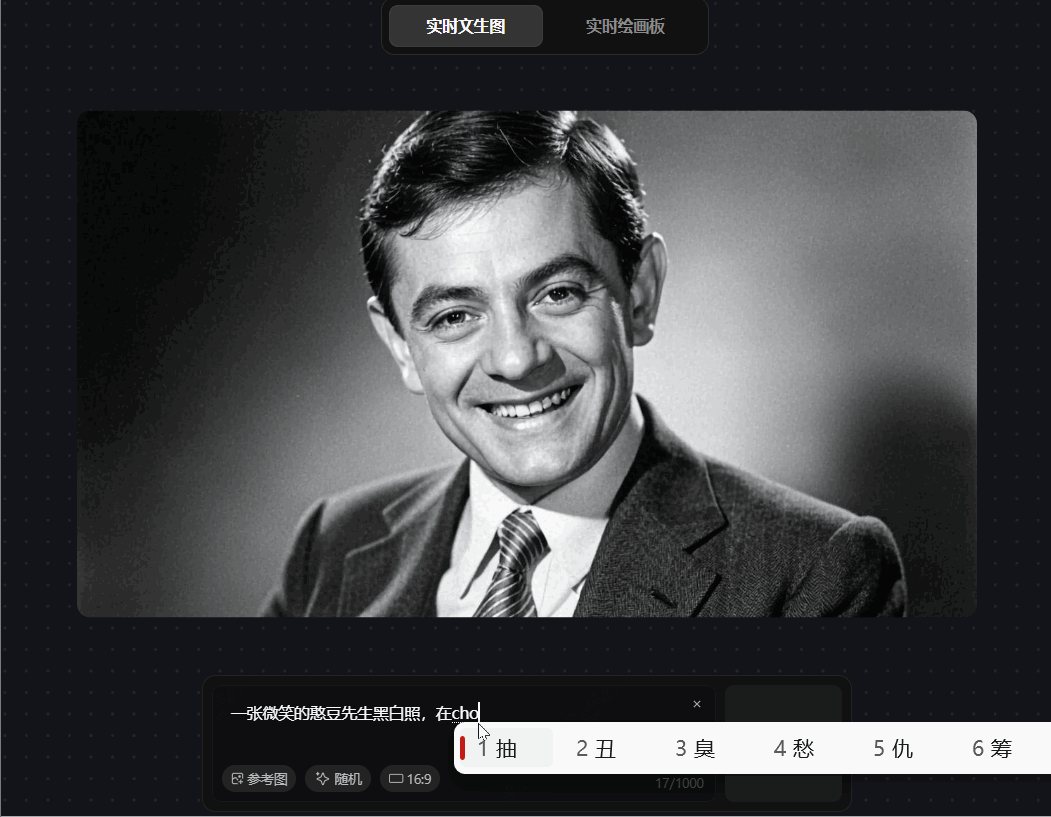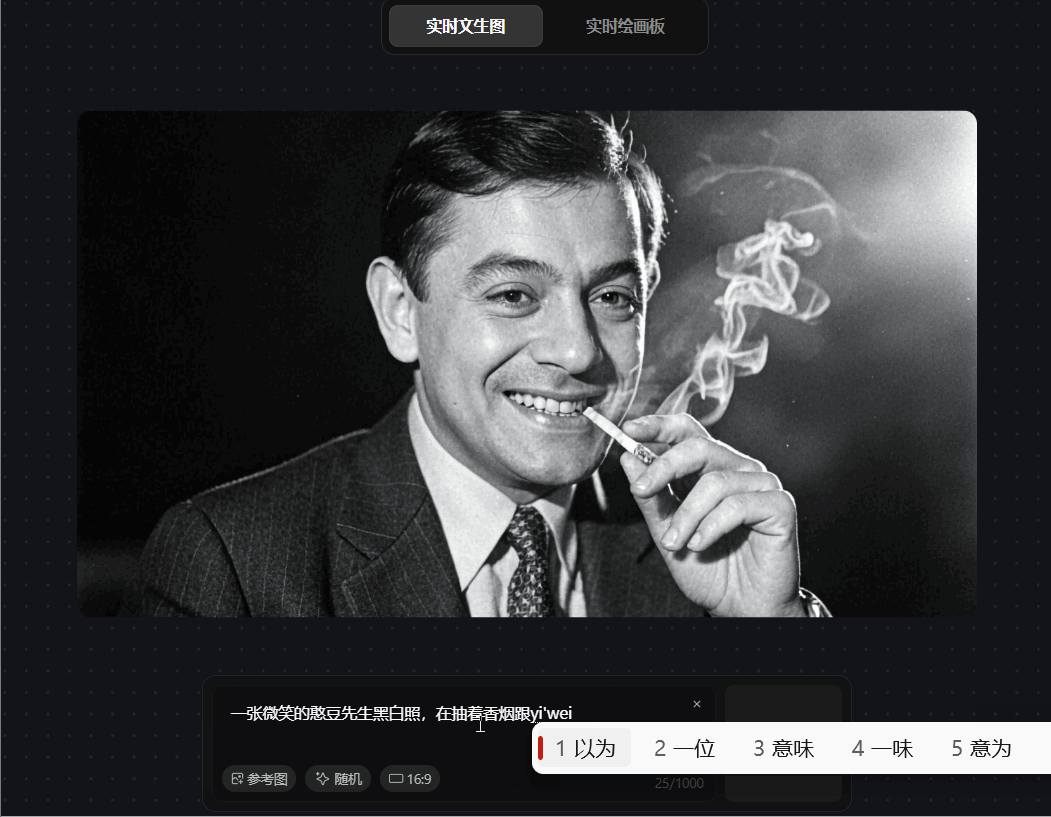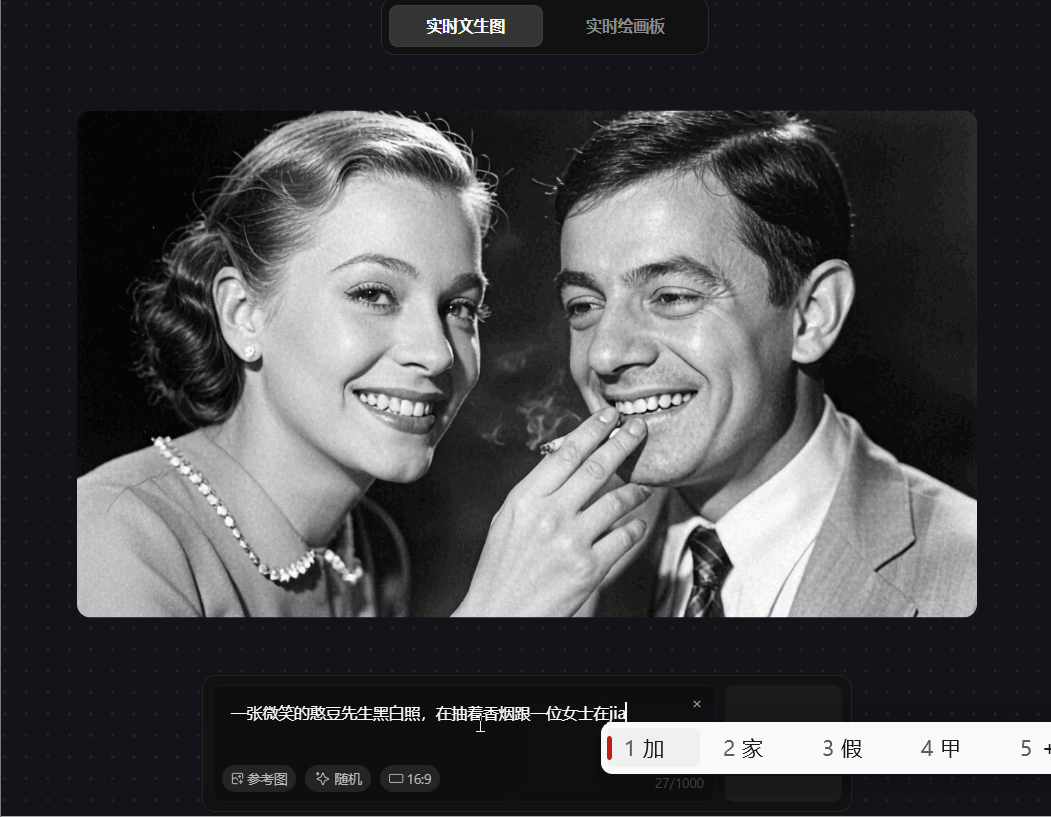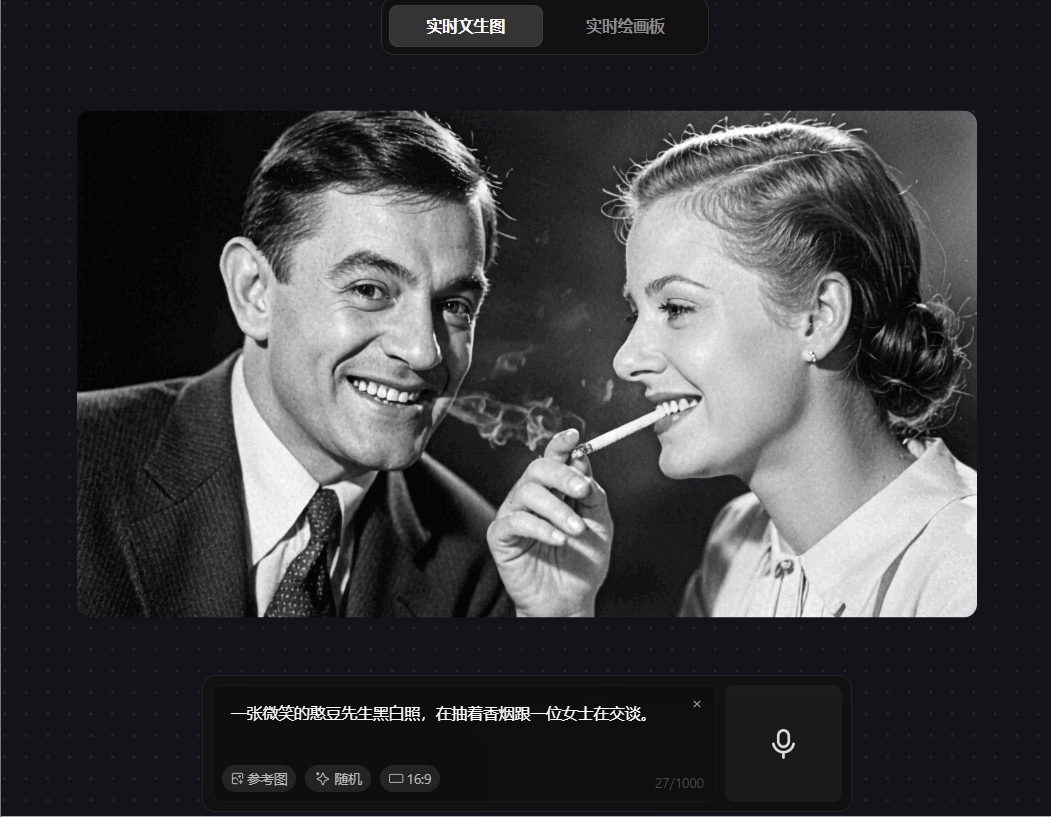
混元图像 2.0 对单主体 prompt”微笑的憨豆先生黑白照"生成精准,展现强理解力。但处理多元素组合指令"抽香烟 + 与女士交谈”时,虽中间过程短暂符合要求,最终输出却将抽烟主体错误映射至女士,多主体交互场景的指令遵循能力差,生成的动作与主体不相符,多对象交互场景的语义一致性较差。
prompt 7:蒙娜丽莎的微笑这幅画,让蒙娜丽莎用手挡住嘴哭泣
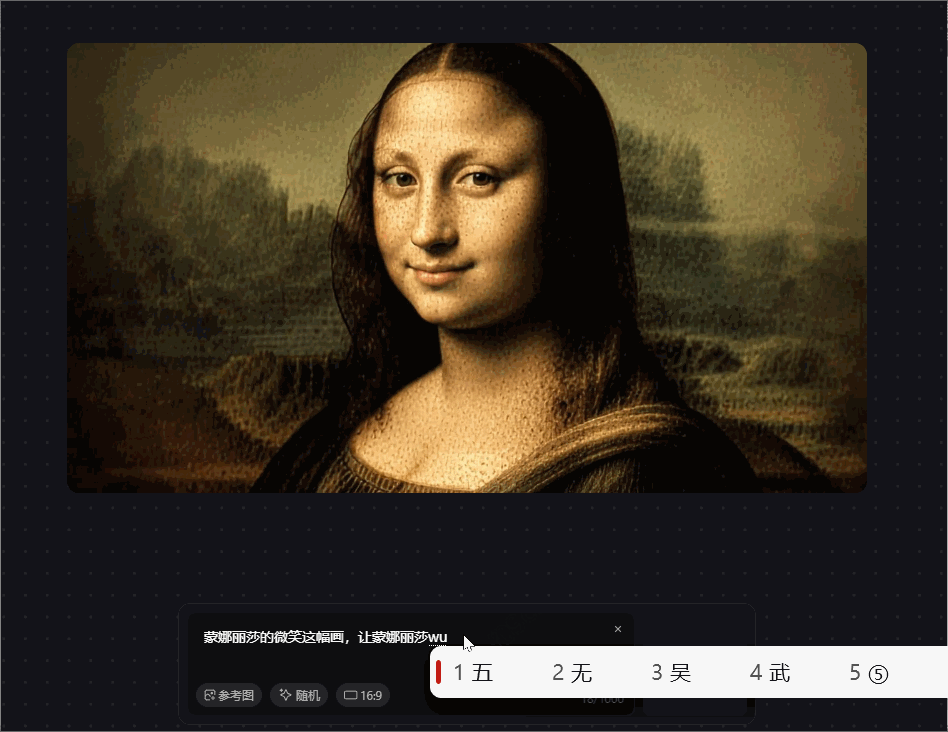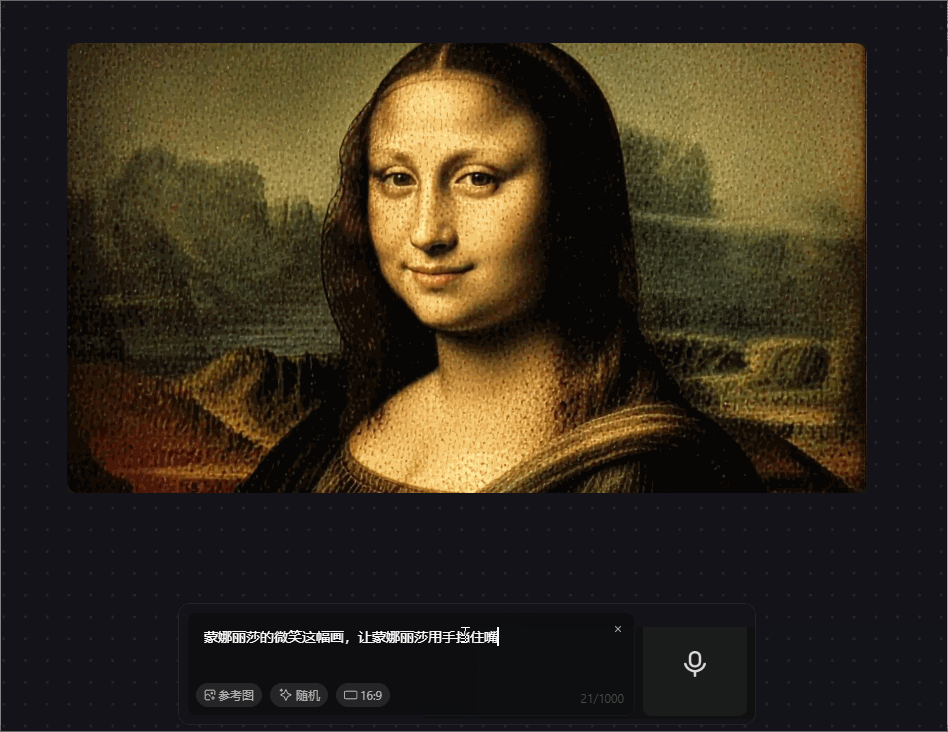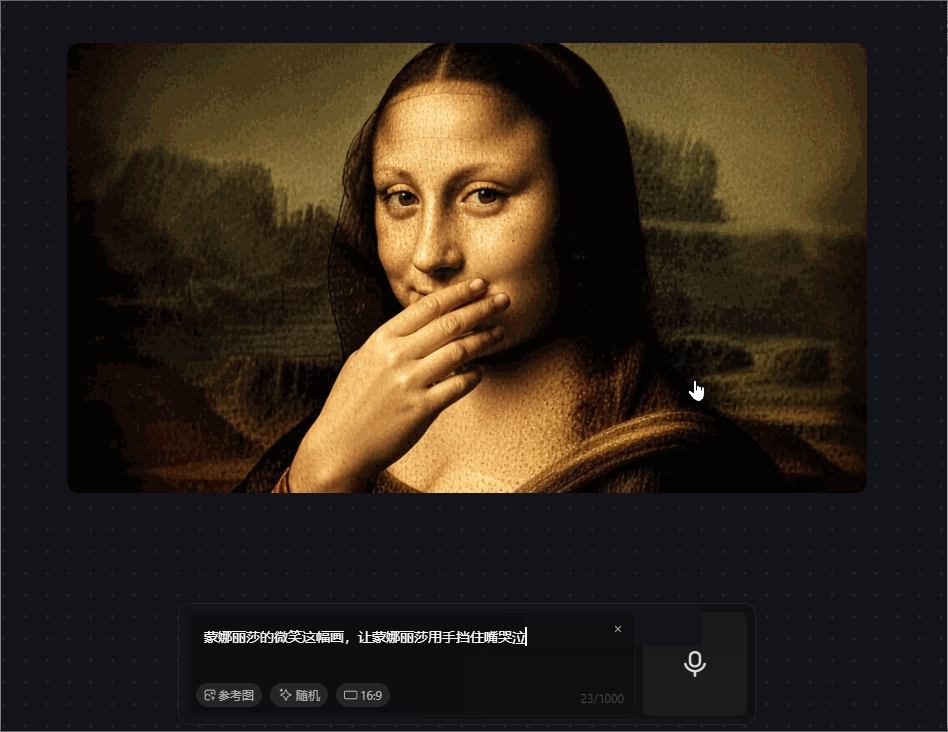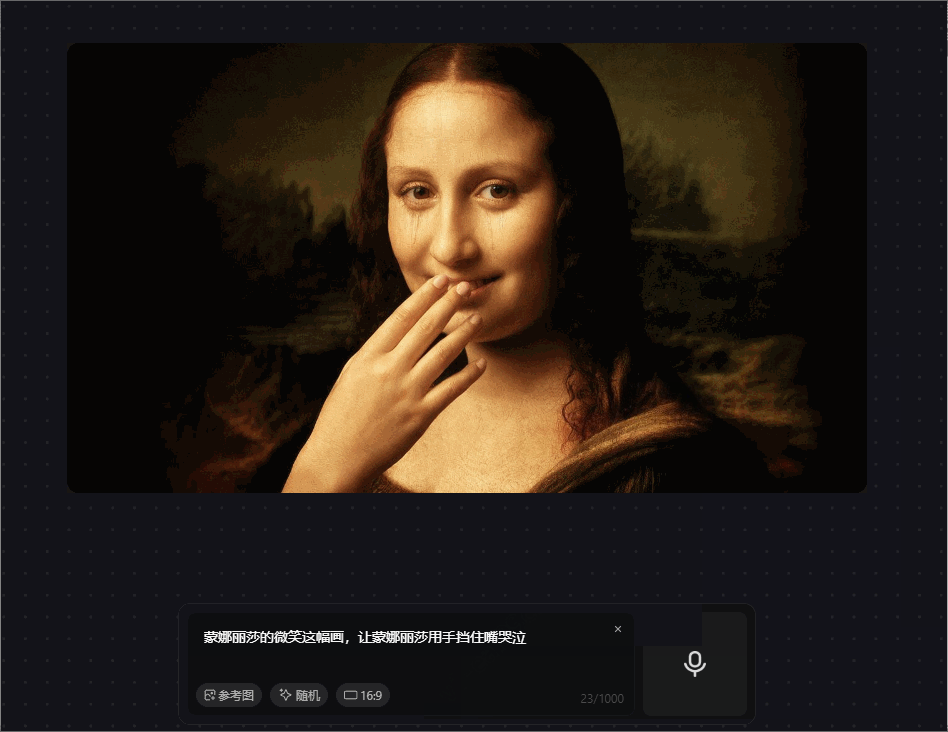
prompt 中前半句可以满足,画面的还原度较高,输入prompt的后半句可以看到眼泪的痕迹,虽然语义上可以对齐,但与现实并不相符,哭泣时的表情仍在微笑,没有结合现实因素。
prompt 8:富士山下的樱花树林,超清,真实摄影
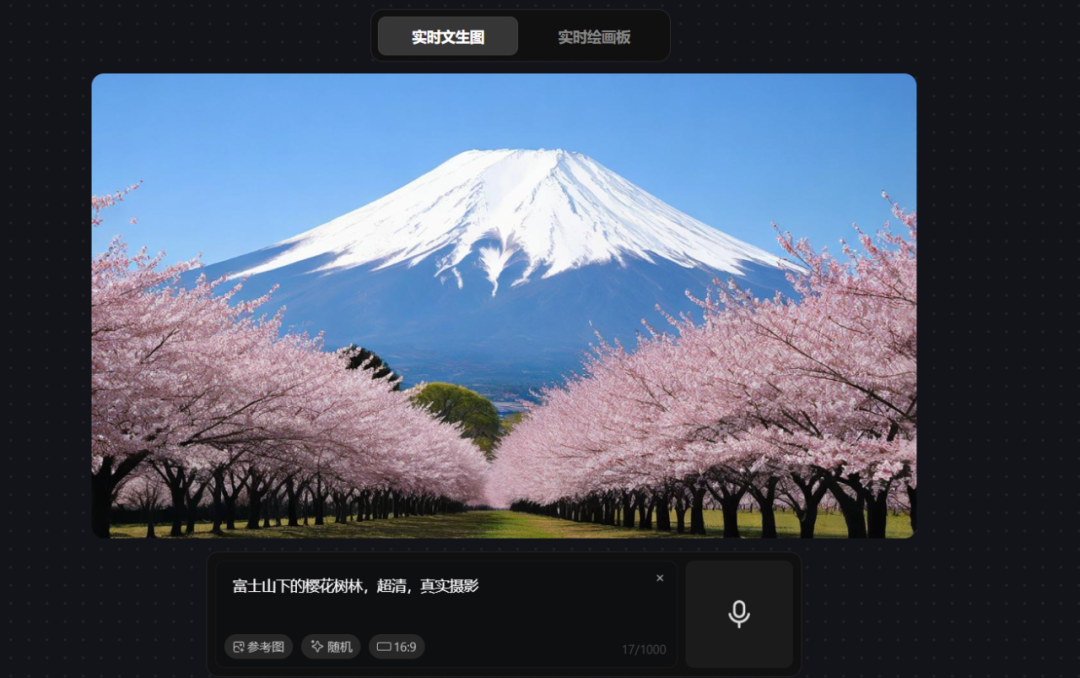
这张图的生成效果较好,画面的真实度非常高,画面构成也符合需求,完成度很高。
prompt 9:用很多朵红玫瑰编织而成的上海武康大楼,这是一座建在30°锐角的路口上,楼身狭长像一艘轮船,采用法国文艺复兴式建筑风格,墙上有一个LED屏,展示腾讯混元图像 2.0 模型的字样,街道上很多行人,敞篷跑车在等红绿灯,背景是上海的老建筑,天空格外晴朗,能看到太阳光

腾讯混元图像 2.0 模型满足 prompt 提到的“行人、跑车、红绿灯、老建筑”等元素,但不符合常识,对上海著名地标不清楚,生成的内容图文不符,LED屏内容显示不清楚,存在明显字符畸形。
tips:如果遇到画面没有变化时,可以点击画质优化,也可以起到刷新的作用。

2.2.2 有参考图类型
为了给大家对比测试有无参考图,对模型生成图像的影响,我们仍选用了上述prompt9的内容,紧接着将武康大楼的参考图上传,看看效果。
prompt 1:用很多朵红玫瑰编织而成的上海武康大楼,这是一座建在30°锐角的路口上,楼身狭长像一艘轮船,采用法国文艺复兴式建筑风格,墙上有一个LED屏,展示腾讯混元图像 2.0 模型的字样,街道上很多行人,敞篷跑车在等红绿灯,背景是上海的老建筑,天空格外晴朗,能看到太阳光
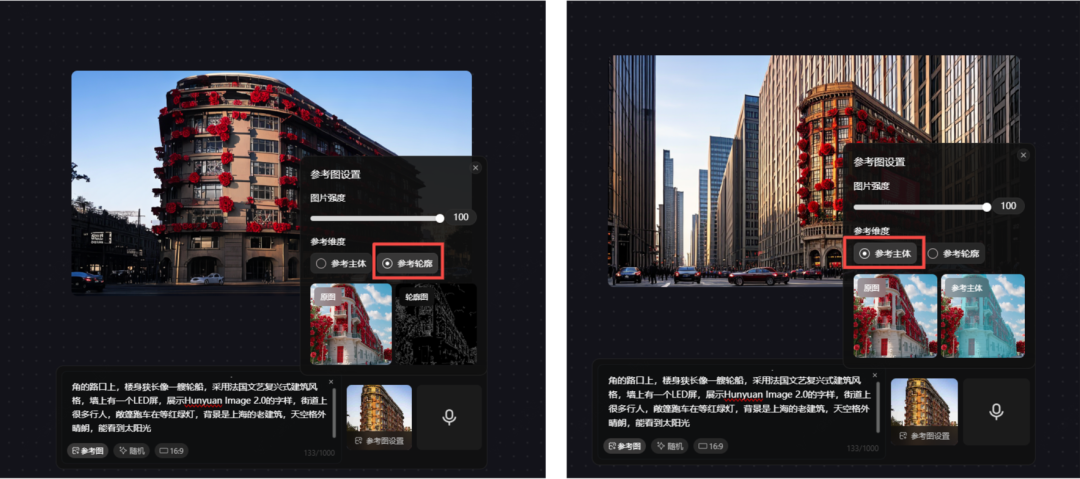
可以看出,有了参考图,轮廓和建筑风格上至少会相似几分,但形状和样式却相去甚远,少部分内容按照 prompt 生成;同时,点击参考轮廓会比参考主体的构图更贴近原图,但整体来看都没有按照 prompt 的需求来生成,整体指令遵循能力较差,生成图片质量不高。
prompt 2 :按照参考图片的风格,生成一个都市女白领喝咖啡的照片
此次我们给到参考图,为宫崎骏风格,但是 prompt 并没有明确说明是“宫崎骏风格”,需要腾讯混元图像 2.0 模型自己识别。
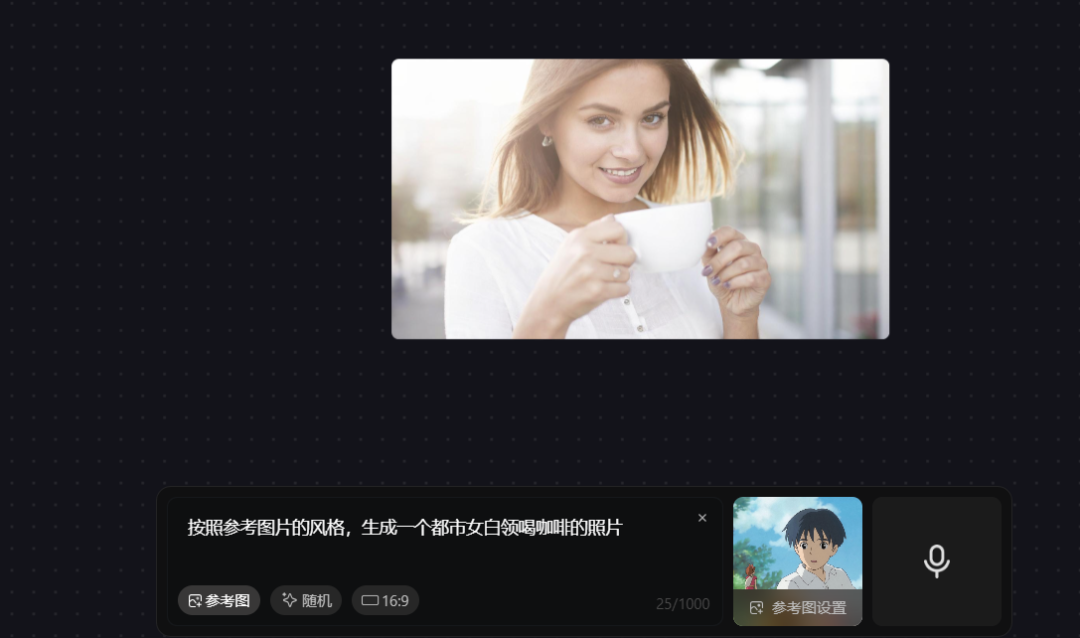
腾讯混元图像 2.0 模型 在艺术风格迁移测试中显现技术短板:当输入指令明确要求"宫崎骏风格"并细化场景描述后,输出图像仍未能呈现该风格标志性特征。
测试表明,当前版本对艺术风格关键词的语义解析存在表层化问题,且在复合指令(风格定义+生物特征+空间逻辑)叠加场景下,生成系统难以有效协调多维度参数,导致核心要素丢失或风格表达失真。
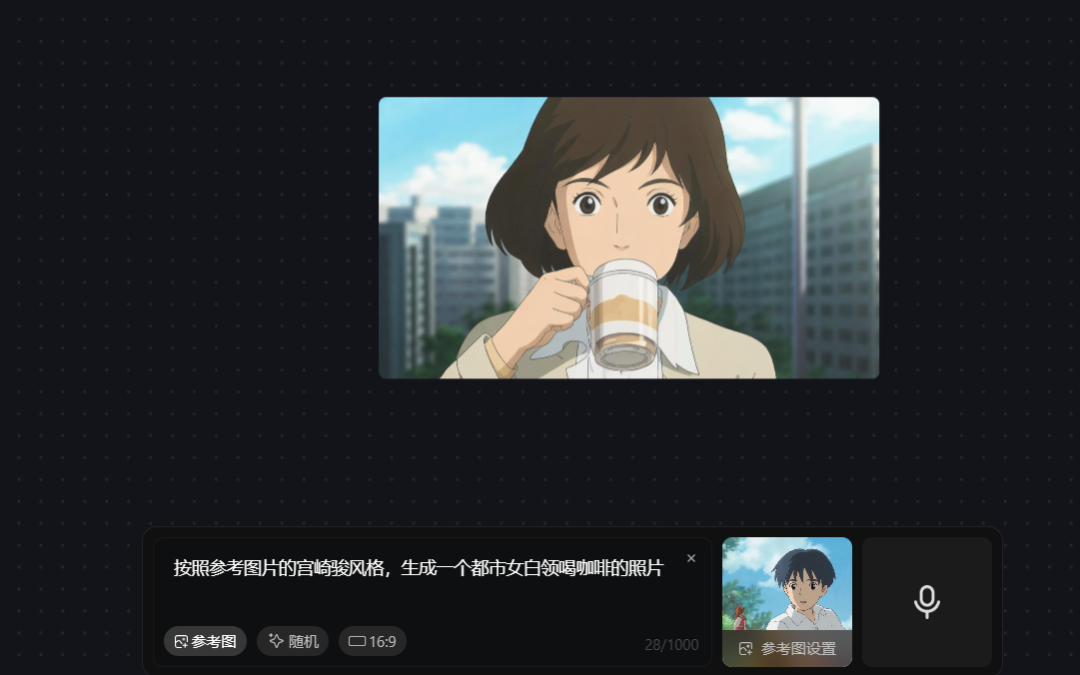
这次我们在 prompt 中,指出了参考图为宫崎骏风格,生成的画面符合我们的需求,生成的都市女性是“宫崎骏风格”的。
2.3 实时绘画板评测
来到实时绘画板区域,左边是你的创意画板,右边就是实时生图的区域,绘画板图片的生成速度慢于实时文生图,不过还是可以接受的。这里依旧将从无参考图和有参考图 两个方向进行评测。
2.3.1 无参考图类型
实时绘画板的使用,可以先在左边手绘参考图,下方输入 prompt,在右侧生成图片。
prompt 1:两个生日蛋糕,上面都有两支蜡烛
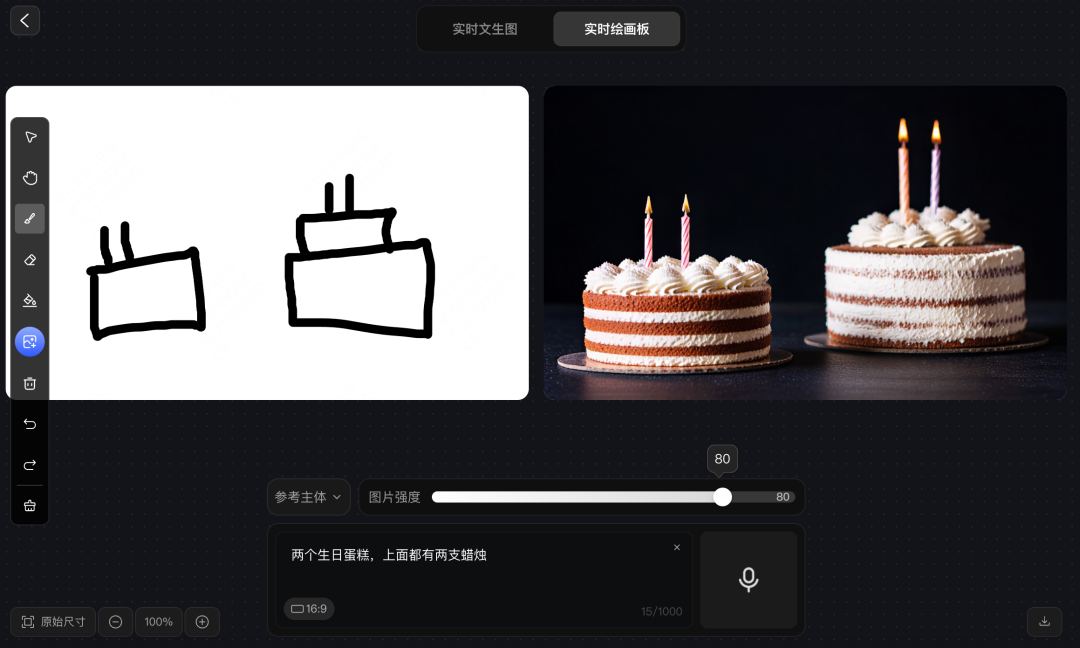
这是一个基础的绘画问题,腾讯混元图像 2.0 模型生成了两个生日蛋糕,很明显,绘画板上左侧是一个单层蛋糕,右侧是一个双层蛋糕,而生成了两个蛋糕,均为单层蛋糕,对更细节的层次数量上还无法满足。
prompt 2:三颗流星划过地球上空,旁边有一个小飞碟
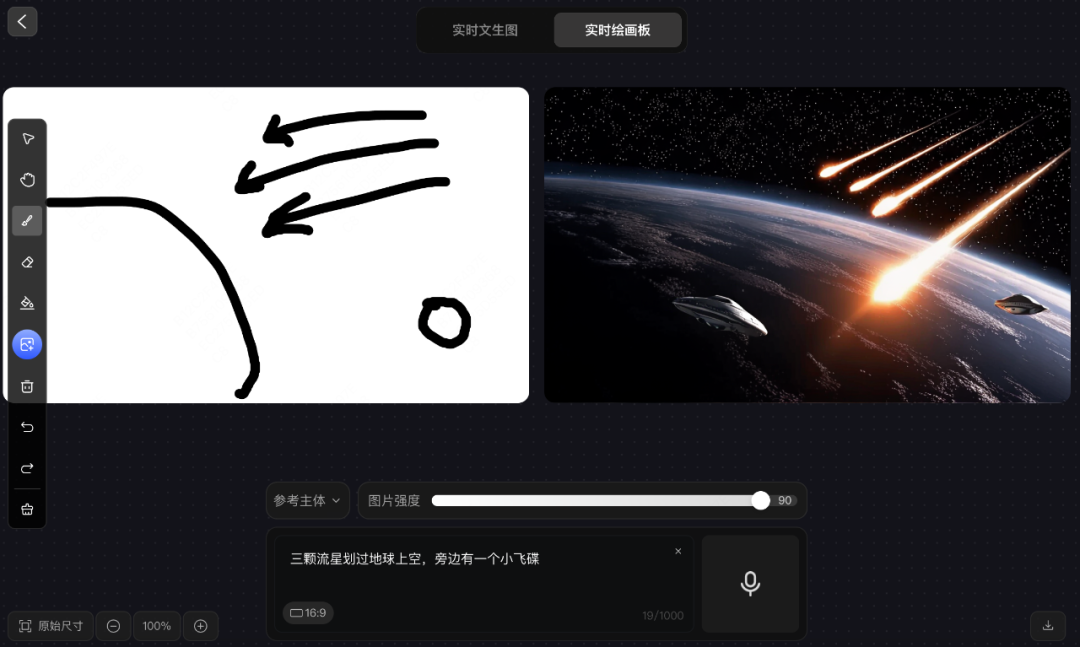
在此案例中,图片的生成效果尚可,颇有“大片感”,但也存在严重的问题,prompt中要求三颗流星、一个飞碟,图片中却出现了四颗流星,两个飞碟。说明模型对“数字”掌握的不好。
prompt 3:古装男女主相对站立,深情望着彼此,背景为古代城墙
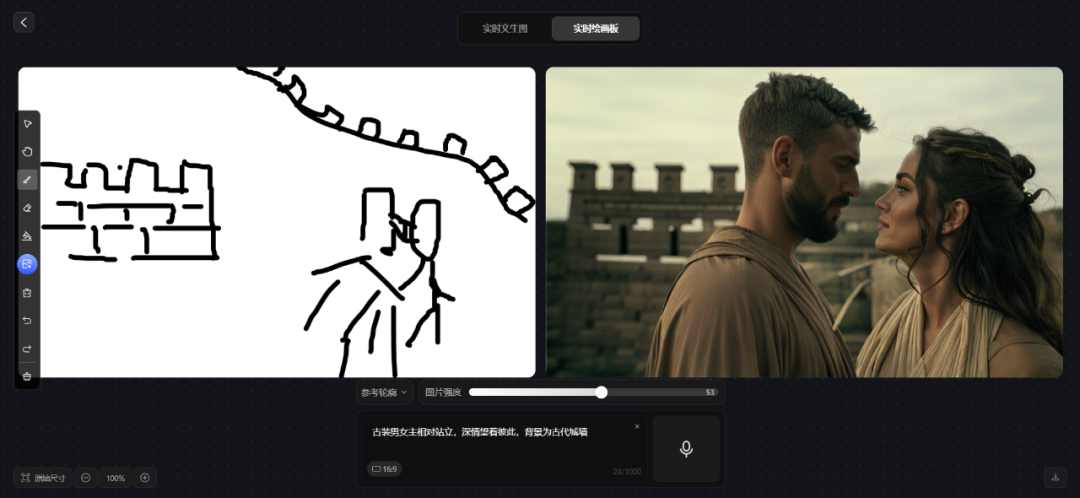
生成的图片基本包含左侧画板中的元素,通过人物的样貌与穿着可初步认为是在中欧时期,背景的城墙未按照画板内容完全显示,在原始绘图细节还原上存在一定的瑕疵。
prompt 4:夜晚的雪山全景,雪山下是一片雪地,银河横跨天际,山巅覆盖积雪,天上有云朵,云朵被月光染成淡紫色,高清, 写实风格
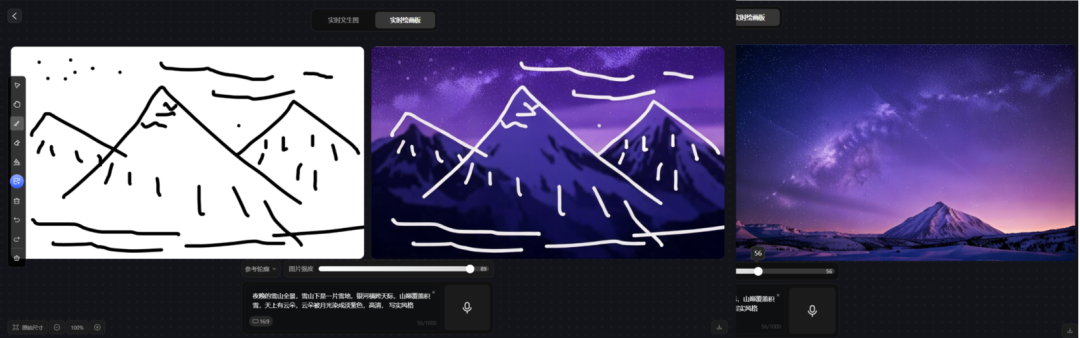
在生成写实图时,无法按照描述100%对应,当图片强度为100时,就完全按照所描绘的图画形成右侧内容,但内容带有动漫感;同时降低图片强度就会减弱对画板内容的依赖,更多的参考文本内容。
prompt 5:苹果品牌的logo是一个被咬了一口的苹果,用同样的规律生成一张"香蕉品牌"的logo
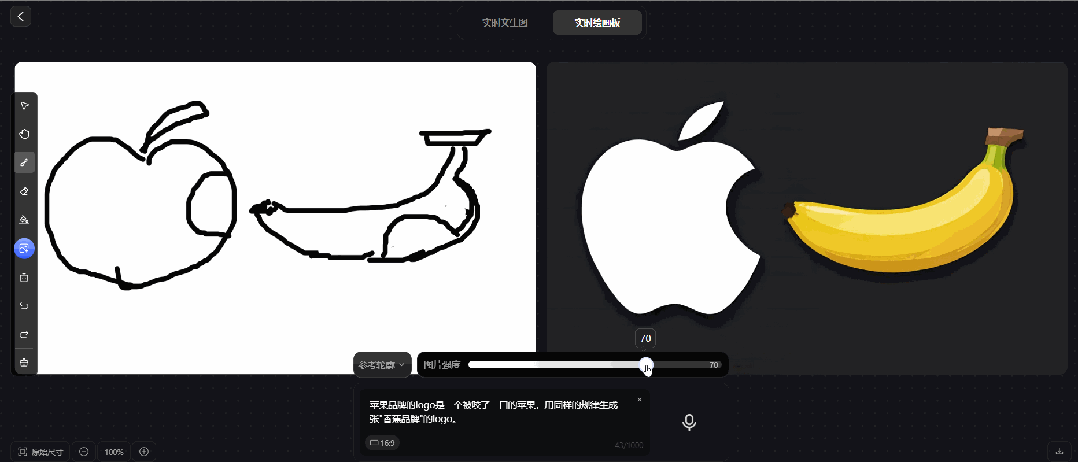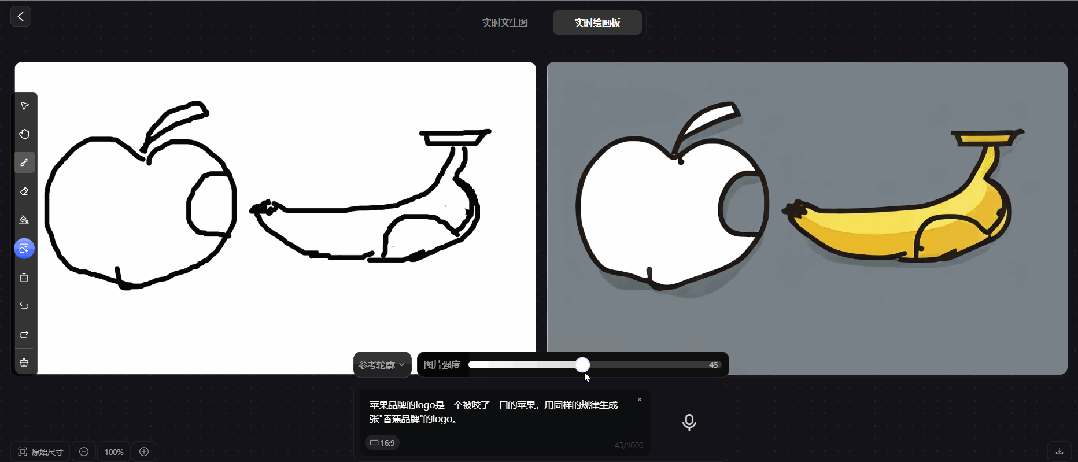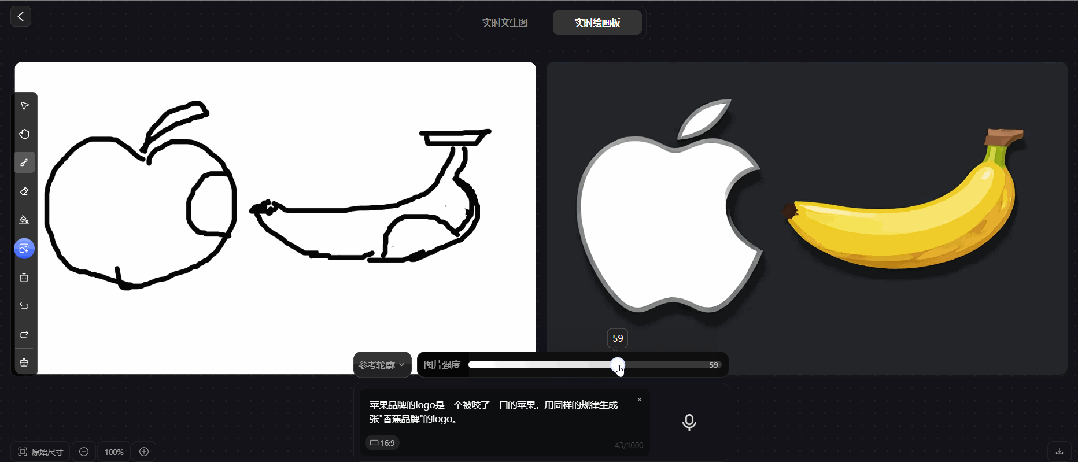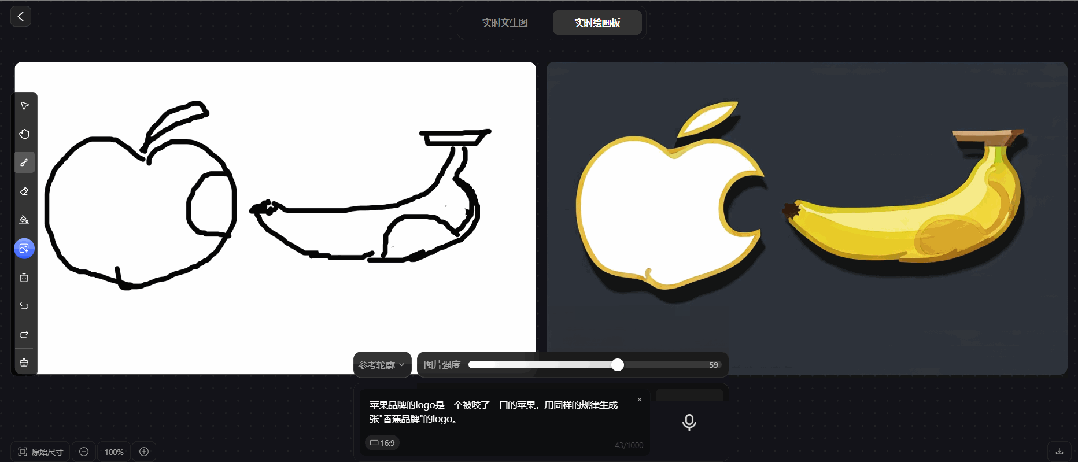
腾讯混元图像 2.0 模型的实时绘画板,也无法实现"香蕉品牌"的logo。只能对针对画板的内容进行生图,无法生成创意类的设计。
2.3.2有参考图类型
也可以先上传参考图,再在参考图中增加画面细节,我们上传了一张小狗图,并输入prompt,在绘画板中绘制了小猫简笔画。
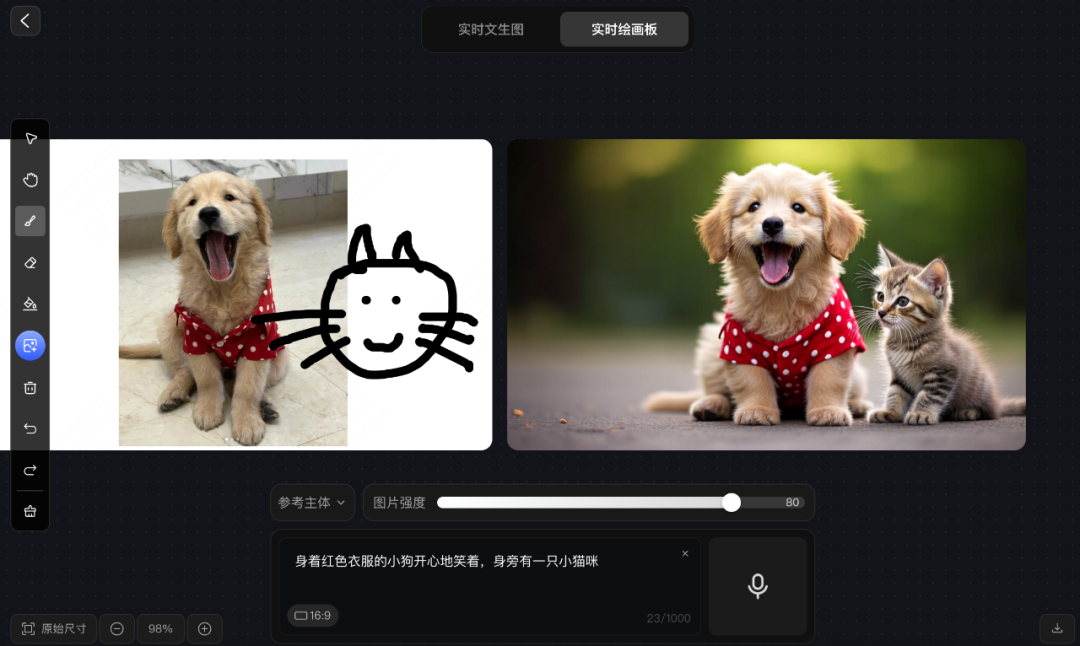
prompt 1:身着红色衣服的小狗开心地笑着,身旁有一只小猫咪
结合参考图,腾讯混元图像 2.0 模型生成了一张憨态可掬的图片,画面背景虚化,突出主体,宛如摄影作品。
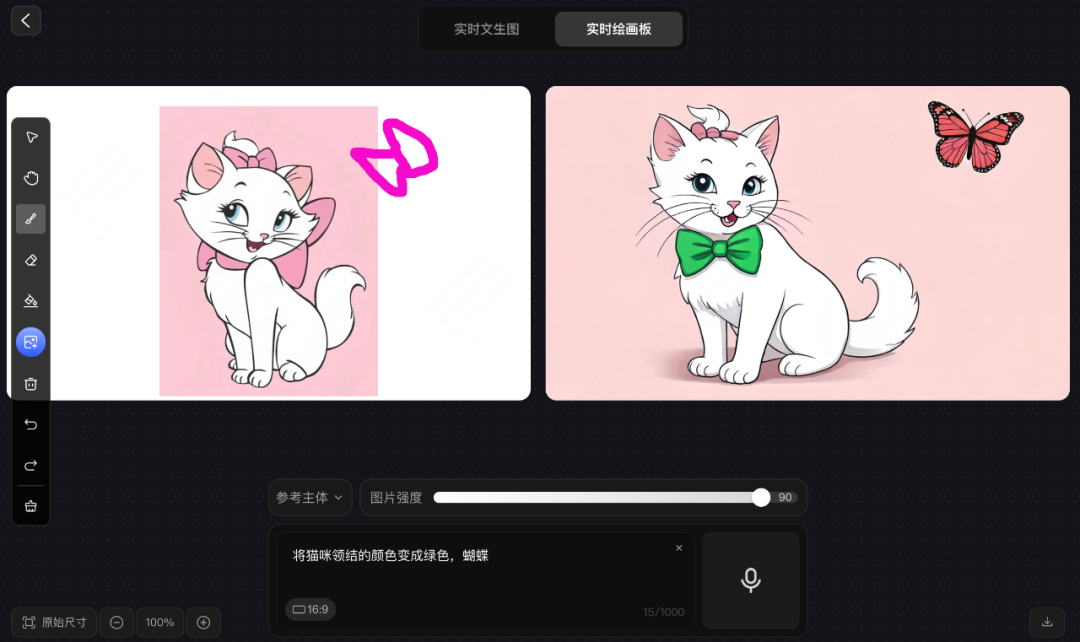
prompt 2:将猫咪领结的颜色变成绿色,蝴蝶
腾讯混元图像 2.0 模型生成了一张不错的动漫图,一个戴着绿色领结的猫咪生成了,猫咪毛发清晰真实。
prompt 3:城市高楼大厦林立,傍晚的天空中,左侧飞过飞机,右侧闪耀着绚丽的烟花
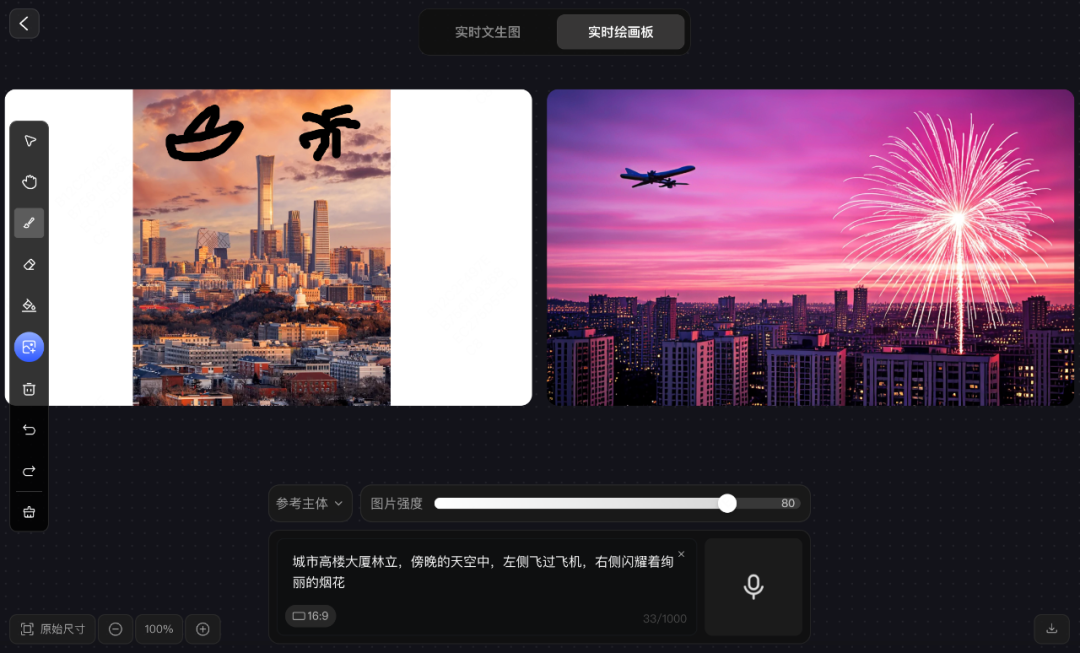
混元图像 2.0 在该场景生成中具备基础构图能力,“飞机和烟花”基本满足需求,但对建筑物改动较大,与原始参考图存在明显偏差,同时天空光影处理出现饱和度异常与自然光照失衡,“AI 味” 明显。
以上就是本次开箱的全部内容,可以看到腾讯混元图像 2.0 模型作为行业首个实现实时生成能力的产品,其创新价值值得充分认可。尽管当前效果在细节处理、语义对齐、场景适配等方面仍有很大提升空间,但技术探索的勇气已彰显行业标杆意义。
期待腾讯混元图像 2.0 模型加速迭代,在数字创作、智能设计等更多领域落地应用,以技术突破持续重构视觉生成体验。
— 完 —


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









