






前几天,阿里巴巴正式开源新一代通义千问模型 Qwen3。上期我们从创作、分析、操作和问答四方面进行了任务实测,本期聚焦其通用能力与应用场景评测。OpenAI 员工、姚班校友姚顺雨发布文章《大模型下半场是产品的游戏,做研究也要有产品思维》,人工智能的重点,已经从“解决问题”转向了“定义问题”,评估或许比训练更重要。模型评测中,应摒弃 “刷榜” 思维,以全面评测视角牵引训练反映模型真实性能,进而推动模型优化。

目录:
1.评测核心结论
2.通用评测结果
3.应用场景评测结果
4.告别刷榜,构建全面评测新体系
1.评测核心结论
Qwen3 模型支持思考模式和非思考模式,可通过参数实现两种模式的切换。Qwen3-235B-A22B的具体实力如何,AGI-Eval 大模型评测社区第一时间做了模型评测,客观评测结论报告如下:
-
在通用能力上,Qwen3-235B-A22B 在 Qwen3 此次更新模型系列中表现最强。其中Thinking 模式略低于 DeepSeek-R1,高于 QwQ-32B;非 Thinking模式落后于 DeepSeek-V3-0324。同时 Qwen3 系列在 SimpleQA 上表现相对较弱,存在一定幻觉风险。
-
在输出长度上,推理任务中,Qwen3-235B-A22B 的平均token为3882,输出长度较 DeepSeek-R1 (平均token为2977)更长,但相比 QwQ-32B(平均token为4596) 有缩减。
-
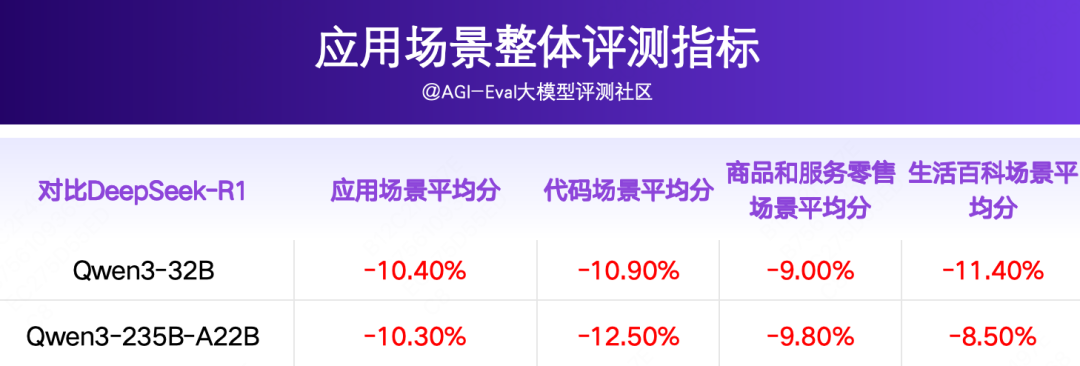
在应用场景上,Qwen3-32B、Qwen3-235B-A22B整体处于同一水位,整体落后QwQ-32B~3.4-3.6pp、落后DeepSeek-R1~10.3-10.4pp。

2.通用评测结果
评测基于自建的通用能力评测集、公开评测集。
自建评测集由主观、客观评测两部分构成,覆盖交互能力、推理、知识储备等各能力;
公开评测集均为客观评测,选取代码、复杂推理、学科等各类有影响力和区分度的评测集,并对其进行质检修正,采用更合理的评测方式(如AIME系列评测集因本身波动较大,采用跑10次结果取均值的方式计算指标,IFEval_Pro为社区基于IFEval修正改造后的评测集)。
2.1 内部评测结果
Qwen3-235B-A22B 在 Thinking 模式下客观准确率为0.7469,略低于 DeepSeek-R1 的0.7660,高于 QwQ-32B 的0.6995;而 Qwen3-235B-A22B 非Thinking 模式与 DeepSeek-V3-0324差距较大(约4pp)。
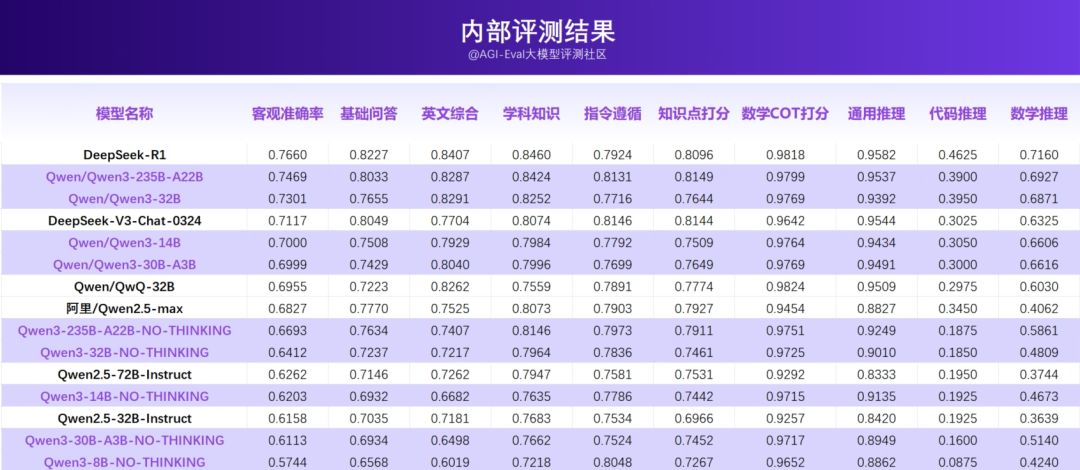
此外,从输出长度上来看,在推理任务上,Qwen3-235B-A22B 的平均token为3882,输出长度较 DeepSeek-R1(平均token为2977)更长,但相比 QwQ-32B(平均token为4596) 有缩减。
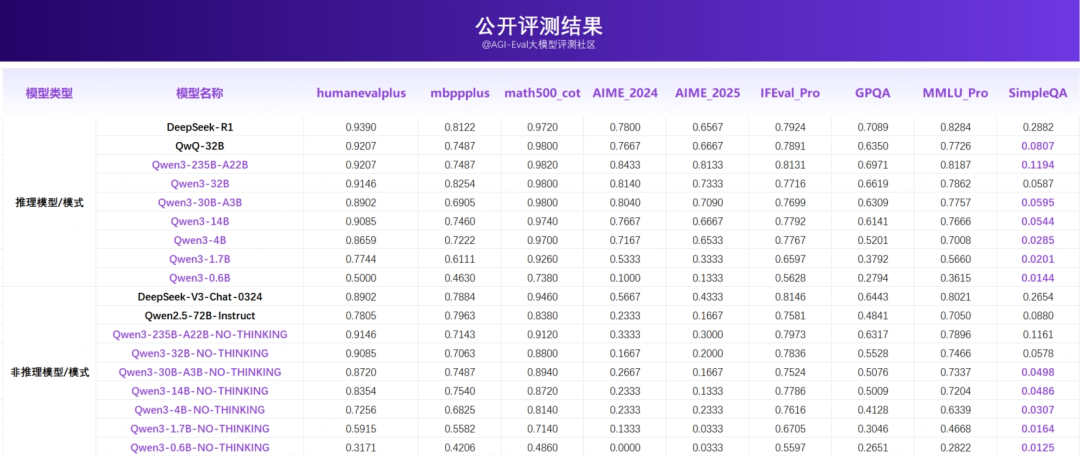
2.2 公开评测结果
Qwen3 系列在 SimpleQA 上表现相对较弱,存在一定的幻觉风险。
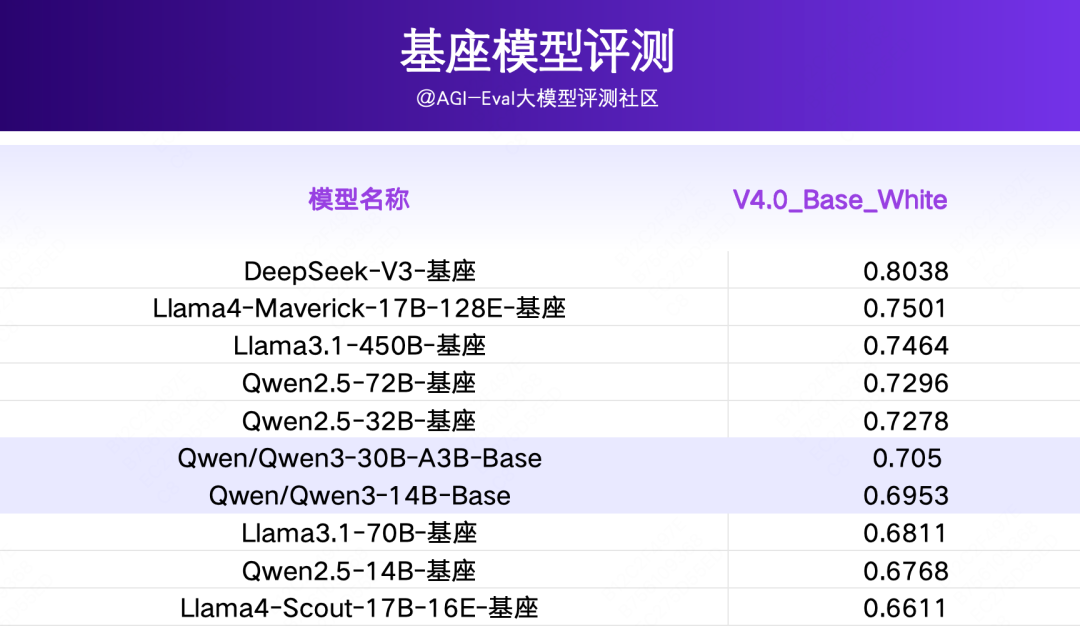
2.3 基座模型评测
-
Qwen3 系列基座,最大尺寸模型未开源,仅开源 Qwen3-30B-A3B-base、Qwen3-14B-Base 及以下尺寸。
-
在通用基座评测集上,Qwen3-30B-A3B-base 和 Qwen3-14B-Base 准确率与近期开源的Llama4-Maverick-17B-128E-基座仍有较大差距。
3.应用场景评测结果
我们来看在代码、商品和服务零售、生活百科3个典型应用场景的客观评测集。Qwen3-32B、Qwen3-235B-A22B(开启Thinking模式,下同)大幅落后于标杆推理模型 DeepSeek-R1,甚至明显落后于自家上一代推理模型 QwQ-32B。
3.1 应用场景整体评测结果
Qwen3-32B 和 Qwen3-235B-A22B 在开启 Thinking 模式下,整体处于同一水位,对比 QwQ-32B 落后~3.4-3.6pp,对比 DeepSeek-R1 落后~10.3-10.4pp。
-
对比 QwQ-32B,Qwen3-32B 和 Qwen3-235B-A22B 整体落后~3.4-3.6pp,在代码场景上差距最大(落后~7.7-9.3pp),在商品和服务零售场景上差距为4.2-5.0pp,在生活百科场景上领先1.1-4.0pp;
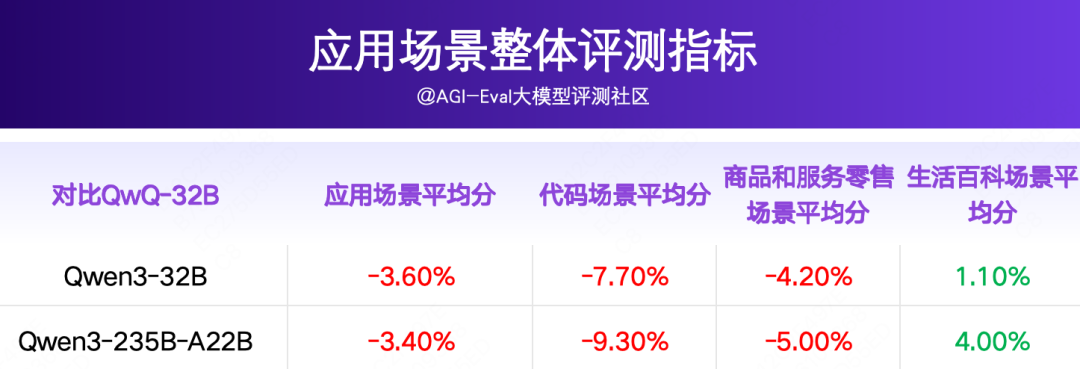
△推理模型的对比开启了 Thinking 模式
-
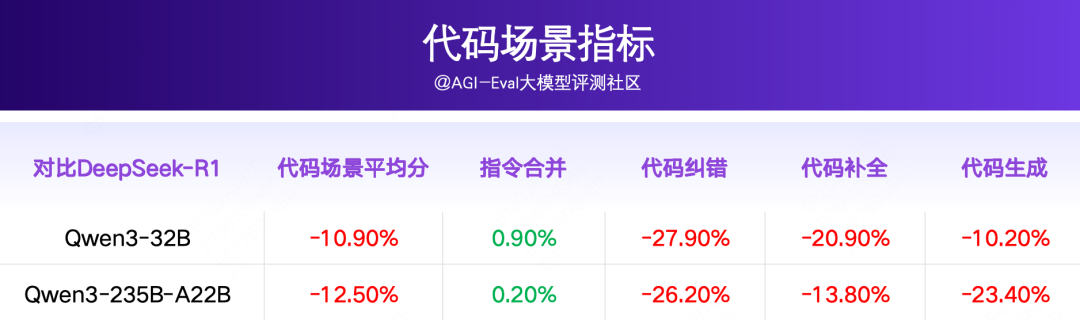
对比 DeepSeek-R1,Qwen3-32B 和 Qwen3-235B-A22B 整体落后~10.3-10.4pp,在代码、商品和服务零售、生活服务场景上均落后~10pp。
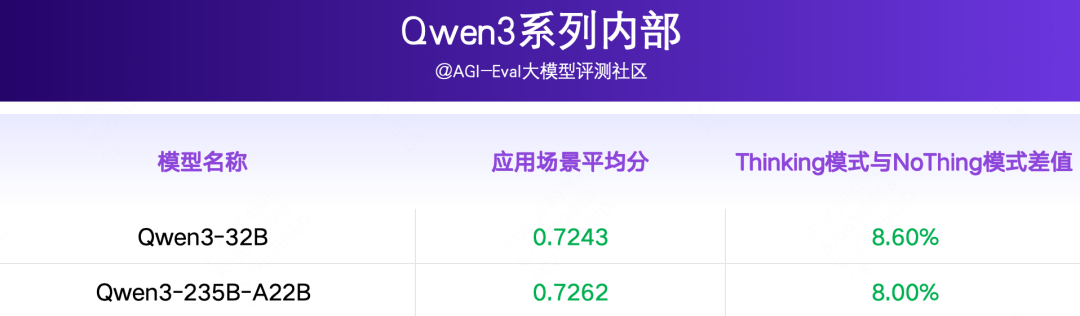
Qwen3系列内部来看:
-
Qwen3 系列的相同模型,开启 Thinking 模式比不开启 Thinking 模式的指标整体高8.0-8.6pp(如下表)。
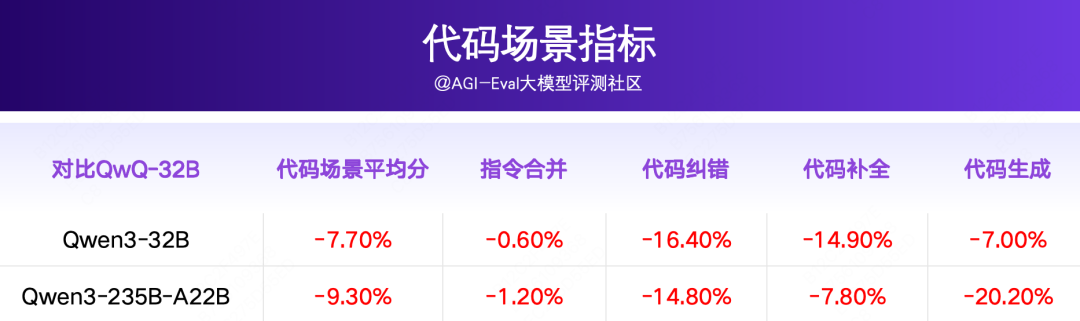
分场景来看:
-
Qwen3系列在代码场景整体表现较差,落后于 QwQ-32B、DeepSeek-R1 至少7.7pp。其中,Qwen3-32B、Qwen3-235B-A22B在指令合并场景上表现尚可,落后QwQ-32B 0.6-1.2pp;在代码纠错、补全、生成场景上大幅落后QwQ-32B 约7.0-20.2pp;
-
Qwen3系列在商品和服务零售场景上整体表现较差,落后于 QwQ-32B、DeepSeek-R1至少 4.2pp。其中,Qwen3-32B、Qwen3-235B-A22B在需要逻辑推理的评测集上表现较差(如在搜索应用场景相关评测集上,易将与用户搜索词/需求不相关的结果判定为符合需求,或错判搜索词和改写词的上/下位词关系);在商品信息提取这类简单信息处理任务上表现较好;
-
Qwen3系列在生活百科场景整体表现不错,领先QwQ-32B约1.1-4.0pp,但距离DeepSeek-R1还有至少 8.5pp差距。其中,Qwen3-32B、Qwen3-235B-A22B在需要逻辑推理的地理位置问答评测集上表现较差,在节日食物、菜系等生活知识评测集上表现较好。
咱们详细看看 Qwen3 系列重点宣传的代码场景指标。对比 Qwen3-32B、DeepSeek-R1,Qwen3 系列差距明显,更易出现边界情况考虑不全等问题。
这里为大家展示 Qwen3-32B 典型错误 case,在下图案例中,Qwen3 没有考虑到分母为0的边界情况,导致无法通过单元测试。
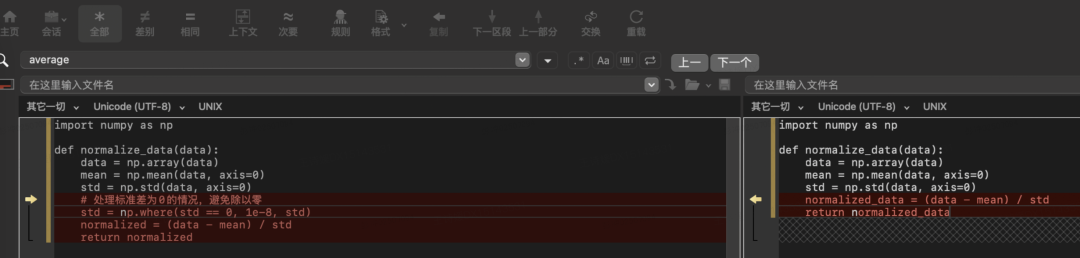
△左侧为QwQ-32B,右侧为Qwen3-32B
4.告别刷榜
构建全面评测新体系
在人工智能技术高速迭代的当下,AI 开发者群体正面临一个普遍的认知误区:将模型在特定测试中的表现误认为真正的智能。这一迷思的产生,与行业内盛行的 “刷榜” 风气紧密相关。以新一代语言模型 Qwen3 为例,围绕 Qwen3 的讨论并不总是全面和客观的,部分评价停留在表面,聚焦于模型在榜单上的排名,而忽视了背后的深层逻辑。
在模型训练的过程中,全面的评测牵引至关重要, “刷榜” 本质上是一种通过针对性训练获取短期效应的手段。开发者为提升模型在特定测试中的分数,没有从足够综合的角度来评估相关因素,围绕测试任务的规则和数据特点进行优化,使模型掌握应对测试的 “伪能力”。这种 “伪能力” 与人类智能在复杂现实场景中展现出的适应性、创造力存在本质差异,难以模拟真实世界中错综复杂的应用情境,无法真实反映 Qwen3 在实际应用中的能力与潜力。
Qwen3 只关注了 AIME 等高难度公开评测,引入幻觉风险,在实际应用场景中,并不能满足用户的真实需求。将其与推理系模型标杆 DeepSeek - R1 对比,其间差距显著;复与该团队上一代更小尺寸的模型 QwQ-32B 相较,部分真实应用场景竟尚不及之。
因此,在人工智能模型的评测中需摒弃刷榜思维。相较于 “刷榜” 带来的短期表面成绩,深入的牵引训练能够帮助我们发现模型的潜力,识别其在长远发展中的优势与不足。一个全面的评测体系需要涵盖语义理解、生成质量、算法推理、实际任务执行多个维度,还要考量模型在未知领域的迁移能力、对模糊信息的处理智慧、以及长期交互中的稳定性。唯有坚持全面评测视角,以真实场景的综合表现为导向进行牵引训练,才能反映模型的真实性能,推动其持续优化,真正满足用户需求 。
未来 Qwen 系列模型,不知道会给大家带来什么样的新的颠覆和创新,我们AGI-Eval大模型评测社区也会持续关注现在大模型行业的发展,持续探寻 AGI 的发展之路,也期待更多人加入我们。
最后,如果你也喜欢这篇文章,那就点赞转发收藏吧~下一期继续为你带来大模型最新资讯&评测&榜单信息,记得关注我们!

AGI-Eval大模型评测
AGI-Eval是上海交通大学、同济大学、华东师范大学、DataWhale等高校和机构合作发布的大模型评测社区,旨在打造公正、可信、科学、全面的评测生态以“评测助力,让AI成为人类更好的伙伴"为使命。
14篇原创内容
公众号
往期回顾
1.【AGI-Eval评测报告 NO.1】DeepSeek 三大类型模型全面评测,通用及推理模型实现领跑,多模态位于第三梯队
2.【AGI-Eval评测报告 NO.2】DeepSeek V3-0324抢先评测!最全报告输出
3.【AGI-Eval实测速报】Qwen3 四大维度开箱评测,模型实测效果大放送!
同时文末也期待大家参与我们社群,一起探寻 AGI 的更多可能性,发现更多不一样的视角,提出问题才有机会解决问题。

















 864
864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









