







近年来,在使用文本指令编辑图像方面取得了相当大的成就。当这些编辑器应用于动态场景编辑时,由于这些2D编辑器逐帧的特性,新型场景往往在时间上不一致。为了解决这个问题,作者提出了Control4D,一种新颖的高保真和时间一致的4D肖像编辑方法。Control4D建立在具有基于2D扩散的编辑器的有效4D表示的基础上。该方法不需要编辑器的直接监督,而是从编辑器中学习一个4D GAN,避免了监督信号的不一致。具体地说,使用鉴别器来学习基于编辑后的图像的生成分布,然后用鉴别信号更新生成器。为了更稳定的训练,从编辑后的图像中提取多层次信息,用于促进生成器的学习。实验结果表明,Control4D 编辑方法优于以往的编辑方法,编辑效果更加逼真,时间更加一致。项目网站的链接是: https://control4darxiv.github.io/。
介绍
生成模型的最新进展使计算机视觉领域发生了革命性的变化,使得从自然语言提示合成真实的图像成为可能。生成模型的成功已经超越了2D图像的生成,包括视频合成的时域和3D形状生成的空间域。
在文本到视频生成领域,最近的研究已经扩大了仅空间文本到图像生成模型的范围,以涵盖时空领域。此外,几种方法已将重点转向使用文本提示的视频编辑,旨在缓解计算资源需求。这些方法展示了真实的基于文本的视频编辑,然而,确保强大的时间相关性和一致性,仍然是一个持续的挑战。
转向3D领域,预训练的图像扩散模型的可用性引发了以文本和图像为条件的3D内容创建和编辑的新兴领域。通过在扩散模型的指导下优化NeRF表示,这些工作不仅能够基于给定的文本提示生成3D对象,而且能够通过使用不同的提示进行微调来编辑生成的对象。最近,Instruction-NeRF2NeRF通过使用其提出的迭代数据集更新编辑现有的NeRF场景,将纹理控制能力推广到孤立对象之外的场景。不幸的是,编辑4D场景(时间+3D)场景还没有开发出来。主要有两个问题:如何在不同的刚体和非刚体运动下进行时空一致编辑?如何使剪辑后的场景真实?
Control4D,是一种只需要输入文本指令就可以编辑4D动态肖像的新方法。为了确保以4D一致的方式反映所产生的编辑,首先训练时空连续的动态场景模型,给定一组具有已知相机参数的多视图视频序列。在这里,采用Tensor4D,一种紧凑高效的基于4D神经多平面的架构作为场景表示。这种4D场景表示至关重要,因为它是生成和编辑空间的基础。此外,应用图像条件扩散模型迭代修改输入图像,同时优化底层4D场景。这个迭代过程产生了一个符合指定编辑指令的优化4D场景。
然而,基于扩散的编辑器采用2D生成过程,并在4D空间中跨时间和视图产生不一致的编辑。因此,使用这些不一致的图像进行优化时,动态场景模型往往会发散或产生模糊平滑的结果。鉴于这一挑战,建议从2D编辑器中学习4D GAN,并缓解编辑后的数据集产生的超视觉不一致的问题。该方法的核心思想是根据编辑器生成的图像学习一个更加连续的生成空间,避免使用直接但不一致的监督。具体地说,将4D场景表示与一个4D生成器结合起来,该生成器可以基于 Tensor4D 渲染的低分辨率潜在特征生成高分辨率图像。同时,使用鉴别器从编辑后的图像中学习生成分布,然后为更新生成器提供判别信号。为了确保稳定的训练,从编辑后的图像中提取多层次的信息,并利用这些信息来促进生成器的学习过程。
作者使用各种动态肖像集对该方法进行了全面评估。为了验证计决策的有效性,进行了相关研究,并将该方法与InstructionNeRF2NeRF的升级4D扩展进行了比较。评价结果表明,该方法在实现4D人像编辑的真实感绘制和时空一致性方面具有显著的能力。综上所述,作者的主要贡献如下:
-
Control4D,一种4D人像编辑方法。对于高保真度渲染和编辑,作者将其建立在高效的4D场景表示和基于分级扩散的编辑器之上。
-
对于时间一致的编辑,作者通过从基于2D扩散的编辑器中学习4D GAN来构建更连续的4D GAN空间,并避免使用不一致的离散监督信号。
-
为了使学习过程更加稳定,作者从编辑后的图像中提取多层次信息,并使用这些全局和局部线索来促进生成器的学习。
相关工作
基于扩散的2D图像生成与编辑
扩散模型使用潜变量迭代地将随机样本转换成类似于目标数据分布的样本。这些模型与预训练的模型相结合,可以解决图像字幕和视觉问答等多模态任务。为了提高性能,VQdiffusion和LDMs在自动编码器的潜在空间内操作。最近的工作通过微调或编辑预训练的扩散模型取得了巨大的成果,但当应用于编辑视频或4D场景时,会出现时间一致性问题。
基于扩散的视频生成与编辑
最近的研究集中在基于扩散的视频时域生成和编辑方法上。视频扩散模型(VDM)采用U-Net架构,将训练图像和视频数据结合起来。ImagenVideo等改进版本通过使用参数化和级联扩散模型实现了高分辨率视频生成。有几种方法,比如 Make-A-Video、 MagicVideo、 Pix2Video和Text2video zero,旨在将文本图像生成转移到文本视频,但由于与训练文本视频模型相关的高成本,许多人专注于使用文本提示编辑视频。这种方法的例子包括 Text2Live、 Dreamix、 Gen-1和 Tune-A-Video。尽管这些方法说明了基于文本的视频编辑的潜力以及 VDM 如何增强视频,但在保持强大的时间一致性、生成高质量视频以及从新视角观看经过编辑的视频方面仍然存在挑战。
基于NeRF的3D生成与编辑
NeRFs因基于校准照片进行逼真的3D场景重建和新颖的视图而广受欢迎,并在随后的许多研究中得到了进一步发展。尽管如此,NeRF仍然对编辑目的构成挑战,主要是由于其潜在的代表性。
NeRF编辑研究人员专注于利用GANs和Diffusion模型的强大生成能力。基于GAN的方法已经看到了将隐式或显式3D表示与神经渲染技术相结合的新架构的激增,取得了有希望的结果。然而,在训练高分辨率3D GANs时,基于体素的GANs面临着诸如高内存要求和计算负担等挑战。另一方面,基于扩散的方法具有将2D编辑扩展到3D NeRF的两种主要方法。第一个涉及使用带有分数蒸馏采样(SDS)损失的稳定扩散来生成3D NeRFs,如DreamFusion及其后续行动中所示。然而,这些方法只能生成孤立的对象,缺乏对合成输出的精细级别控制。第二种方法利用数据集更新(DU)迭代指导NeRF收敛,如Instruction-NeRF2NeRF所示,但它存在网络收敛问题,可能会耗费大量成本。
所提出的4D编辑方法以DU为基线,并利用学习生成策略对其进行了改进。作者基于编辑后的NeRF输入生成扩散先验,从而生成高质量的编辑结果,并克服了DU方法的局限性。
用于动态场景的NeRF
为了将NeRF的成功扩展到时间域,研究人员采用了在具有时间维度的4D域中建模场景的策略。DyNeRF提出了一种基于关键帧的训练策略来扩展具有时间条件的NeRF。VideoNeRF直接从单角度视频中学习时空辐照度场,并通过结合深度估计来解决单目输入中的形状运动模糊性。同时,NeRFlow和DCT-NeRF利用点投影来规范网络优化。Park[32,33]、Pumarola][37]、Tretsck[52]等人采用了类似的框架,分别引入了单独的MLP来预测多视图和单目视频的场景变形。动态场景的另一种方法是DeVRF,它采用基于体素的表示来对3D规范空间和4D变形场进行建模。此外,包括Neuralbody等在内的方法利用参数体模板作为系统先验,以实现复杂人类表现的照片逼真的新视图合成。最近,为了用较低的内存实现更高的质量,NeRFPlayer将4D空间分解为静态、变形和新出现的内容区域。同时,HexPlane以及K-Planes已经提出使用2D张量使用低秩分解来表示4D场景,而HumanRF使用3D和1D张量。
尽管在开发高效和反式4D表示方面做出了许多努力,但对编辑动态NeRF的研究仍然缺乏。作者首次提出了一种基于Tensor4D的动态4D NeRF场景编辑方法,这是一种高效的4D NeRF表示,并取得了非常有希望的结果。
预备知识
用于动态场景表示的Tensor4D
作者利用高效的4D表示Tensor4D作为4D编辑的基础。与其他基于NeRF的表示相比,Tensor4D通过将4D场景张量分解为九个平面来更有效地表示动态场景。通过这种方式,可以以更紧凑的方式同时捕获时空信息。具体而言,使用标准空间+流方法实现动态NeRF,并使用Tensor4D同时分解标准空间h()和4D流场f():
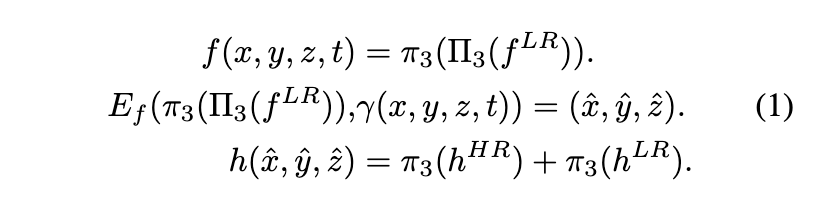
通过合并流表示,可以生成更一致的结果。Tensor4D中标准空间和流表示的结合能够有效地建模和捕捉场景的动态方面,从而实现更准确和逼真的4D编辑结果。
指令-NeRF2NeRF
Instruction-NeRF2NeRF是一种使用文本指令进行3D NeRF场景编辑的最新方法。他们采用了InstructionPix2Pix,一种图像条件扩散模型,以实现基于指令的2D图像编辑,并提出NeRF微调期间的迭代数据集更新(迭代DU)。迭代DU的关键思想是在编辑NeRF输入图像和通过编辑图像的直接监督更新NeRF表示之间进行切换。
Control4D
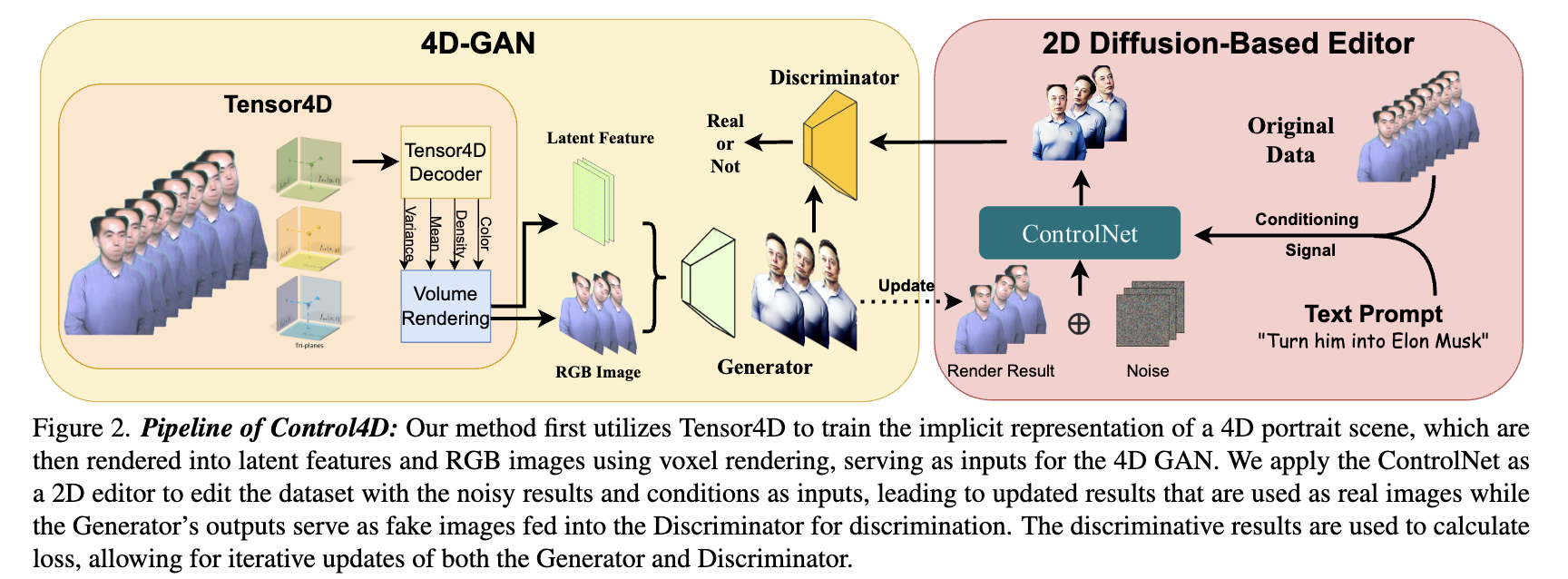
为了实现4D编辑,作者首先引入了一种基线方法,该方法包括三个关键组成部分:Tensor4D作为动态场景表示,ControlNet作为图像编辑器,数据集更新(DU)作为训练策略,通过从图像编辑器中学习生成,提高了4D编辑的保真度和一致性。此外,作者引入了一种高效的分阶段训练策略,有助于在4D场景中更快地收敛。结合所提出的策略,显著提高了4D剪辑的整体能力和效率,并提供了改进的保真度,一致性和收敛速度。
直接监督4D编辑的基线
最初,Tensor4D在多视图视频序列上进行训练,以获得时空连续的4D表示,这是后续4D编辑的基础。然后使用ControlNet作为编辑器来编辑训练数据集中的所有图像。ControlNet有三个输入:Tensor4D渲染图像、原始图像和编辑提示。为了建立控制条件,提取原始图像的法线。对于人手,额外提取开放姿势关键点作为控制条件。为了适应最初对大规模编辑效果的需求,并随着场景与目标编辑场景变得更加一致而逐渐转变为小规模编辑效果,将不同级别的噪声应用于Tensor4D渲染图像。这使得能够引入不同规模的编辑效果。随后,将有噪声的渲染图像、控制条件和编辑提示输入到ControlNet中,以获得编辑后的图像。
在完成编辑过程后,Tensor4D在新编辑的图像的直接监督下进行了微调。数据集更新(DU)用于在训练过程中不断更新数据集。在每次更新中,都会在数据集中选择一个随机索引,并将Tensor4D渲染的相应图像、控制条件和编辑提示输入ControlNet。新生成的图像将替换先前编辑的图像。随着渲染图像和编辑目标变得越来越一致,ControlNet的更新幅度减小,从而导致收敛。
虽然这种方法能够进行4D编辑,但重复使用ControlNet来更新数据集会导致较高的训练成本。此外,与3D编辑不同,将这种方法应用于4D序列需要编辑来自不同视点和时刻的图像。ControlNet逐帧编辑的特性,每次都会生成整体风格、照明和局部细节不同的图像,这给Tensor4D实现一致收敛带来了挑战。因此,Tensor4D会产生模糊而平滑的结果。
从2D编辑器学习4D GAN
为了促进复杂和反向编辑过程中的网络收敛,作者提出了一种新方法,如何从2D编辑器生成4D场景,从而稳定4D编辑的优化。该方法背后的关键思想是避免对编辑后的图像进行直接监督。相反,该方法通过GAN学习更连续的生成空间,以在Tensor4D和动态生成的图像之间建立联系。具体来说,将Tensor4D与生成器集成,并训练GAN从扩散模型生成的编辑图像中学习生成空间。利用其生成能力,GAN可以有效地从基于扩散的编辑器中提取知识,并区分渲染图像(假样本)和编辑图像(真实样本)。随后,Tensor4D可以在由判别损失监督的连续生成空间内进行优化。通过这种方式,提出的学习生成有效地缓解了模糊效果,从而实现了高保真度和一致的4D编辑。将Tensor4D与GAN集成用于4D场景生成;以及具有多层次指导的生成。「通过将Tensor4D与GAN集成来生成4D场景」。为了实现基于NeRF的表示的生成能力,通过用GAN增强Tensor4D表示来构建4D场景生成器。Tensor4D增加了潜在特征,作为绘制分布图的附加属性。基于渲染的分布图,将对潜在特征图进行采样并将其输入生成器。具体而言,增强Tensor4D可以捕捉潜在特征在每个空间位置的统计分布,包括它们的均值和方差。
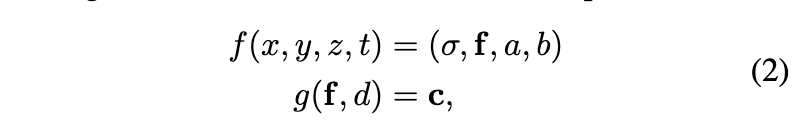
其中f和g是Ten-sor4D中的几何和颜色MLP,a,b是潜在特征的平均值和方差。可以同时渲染低分辨率RGB图像和分布图,分别表示为和,它们捕捉潜在特征的平均值和方差。通过利用这个分布图,开始对潜在特征图进行采样,该特征图将被输入生成器:
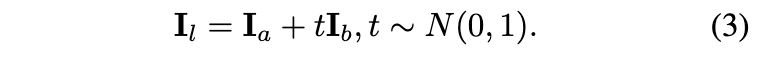
然后,给定来自Tensor4D的渲染RGB图像和潜在特征图$(I_l),将这两个图连接起来,并将它们输入生成器以合成高分辨率图像:
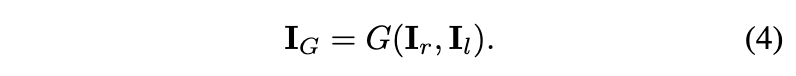
如上所述,由于逐帧编辑,所编辑的图像在时间上不一致。为了避免直接监督的离散和不一致问题,通过GAN从这些编辑的图像中学习更连续的生成空间。具体而言,生成的图像被视为假样本,而编辑的图像被视为真实样本。GAN损失可公式化如下:
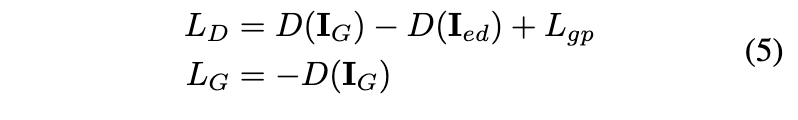
D是鉴别器,是 Wasserstein GAN 梯度惩罚损失。
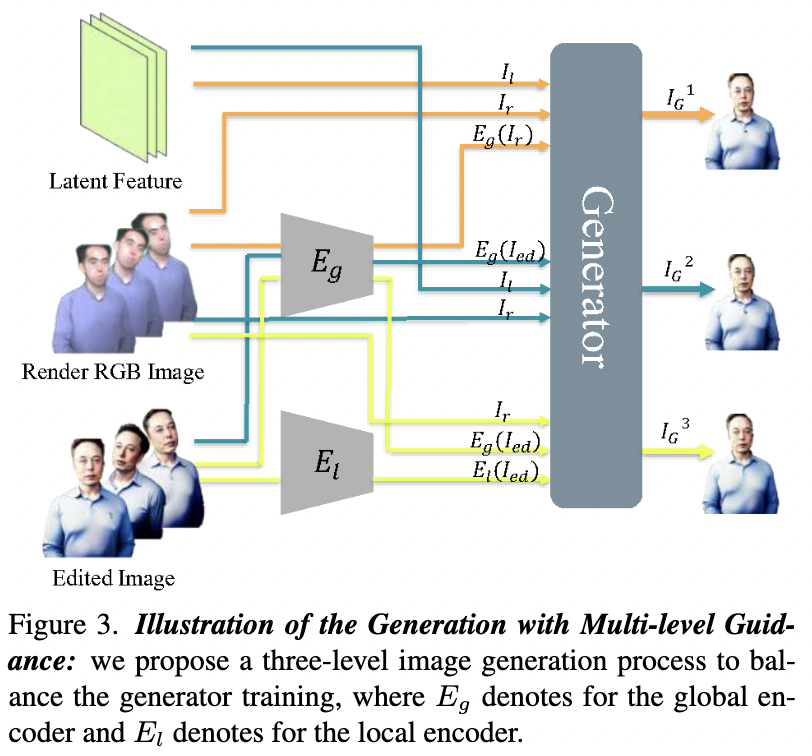
「具有指导的多级生成」。当训练GAN时,方程5中的损失,观察到学习过程中经常会出现崩溃问题。这可以解释为编辑的图像数量有限,鉴别器很容易学会如何区分不同的样本来源。为了稳定学习过程,作者建议从编辑后的图像中提取多层次信息,并使用这些全局和局部线索来指导生成器的学习。如上图3所示,在训练过程中,构造了两个网络全局编码器 和局部编码器 来分别提取编辑后的图像 的全局编码和局部特征图。有了这些条件作为额外的输入,发电机可以在三个层次上合成图像:
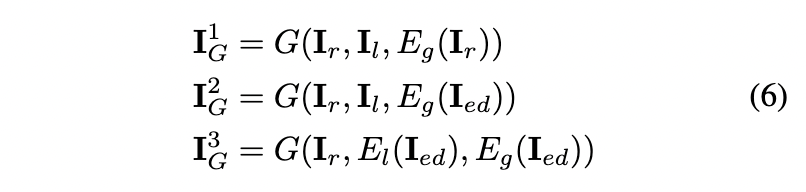
在从级别1到级别3的整个过程中,生成器生成的图像逐渐接近真实编辑的图像: • 在第1级,生成器直接基于Tensor4D合成图像。 • 在第2级,引入来自真实编辑图像的全局信息作为条件,引导生成器产生与真实图像的整体风格一致的结果。 • 在第3级,来自真实编辑图像的全局和局部信息都被用作条件,使网络能够生成与真实编辑图像在整体模式和更精细细节方面表现出一致性的图像。

还在不同层面上利用不同的损失:
1级采用原始GAN损失。在第2级,引入了概念损失,作为全局样式中强制一致性的附加约束。在级别3,损失函数同时包含L1损失、感知损失和GAN损失作为惩罚,因为需要细节和全局风格的一致性。这种多级信息引导生成器向扩散模型的生成空间逐渐收敛,与原始GAN训练过程相比,提高了单个场景中的训练稳定性并加速了收敛。
训练策略
为了解决与使用扩散模型相关的高迭代优化成本,作者提出了一种更有效的策略来实现4D编辑。利用标准空间+流Tensor4D表示的特点,采用分阶段训练的方法,有利于收敛。首先,固定的流程和专注于编辑标准空间。这简化了编辑过程,从4D 到3D 静态编辑,导致更快的收敛。一旦标准空间的编辑已经收敛,继续训练整个4D 序列的流。在流和标准空间分别收敛后,释放固定约束,并同时对两个组件进行微调。这个微调阶段增强了4D编辑效果的自然度。通过采用这种训练策略,克服了与差异融合模型相关的高迭代优化成本,从而在4D编辑过程中更快地收敛。
实验
作者主要在动态Tensor4D数据集上进行了实验,该数据集通过四个稀疏定位的固定RGB摄像头捕捉动态半身人视频。使用棋盘进行标定。每个数据样本在1-2分钟的时间内捕捉到各种各样的人类活动。在实验中,从全长视频中提取了2秒的片段,包括50帧,用于4D重建和编辑。此外,为了展示该方法在360度场景中的能力,还从Twindom数据集中选择了扫描的人体模型进行额外评估。
定性评价
静态场景
将作者的方法与静态场景下的nerf2nerf指令进行了比较。从Twindom数据集中选择了一些人类模型,并在360度范围内随机采样了180个视点来渲染图像。接下来,评估了该方法,并指示nerf2nerf进行编辑,并提示“把他变成埃隆·马斯克”。在图4中,展示了从我们的方法中获得的结果,并在50,000次迭代训练后指导nerf2nerf。
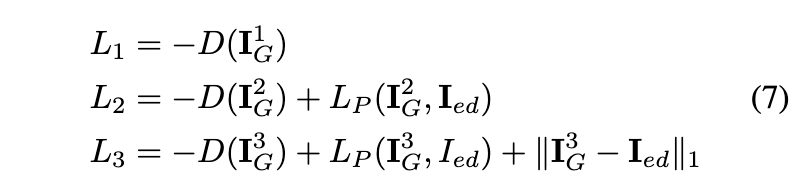
观察结果,很明显,作者的方法生成了高质量的图像,显示出丰富的细节和增强的真实感。相比之下,instructionnerf2nerf输出看起来更流畅,在侧视图的混合中观察到了一些问题。这一比较突出了4D GAN在编辑能力方面的显著优势。
动态场景
在动态场景中,比较了提出的方法和基线方法,结果如下图5所示。还展示了参与各种行为的不同个体的结果,可以参考下图6。在基线方法中,没有使用基于GAN的生成,Tensor4D直接负责在空间和时间上拟合动态变化的编辑数据集。这种直接拟合过程通常会导致平滑结果的优化,而这些结果可能缺乏一致性和高质量的细节。作者提出的方法结合了基于GAN的生成,利用GAN来学习更连续的4D生成空间。这能够利用平滑的监控信号进行优化。因此,作者的方法生成一致且高质量的结果,这些结果在动态编辑过程中表现出更好的保真度并捕捉到更精细的细节。基线方法和作者的方法之间的比较证明了4D GAN在提高生成结果的整体质量和一致性方面的有效性。


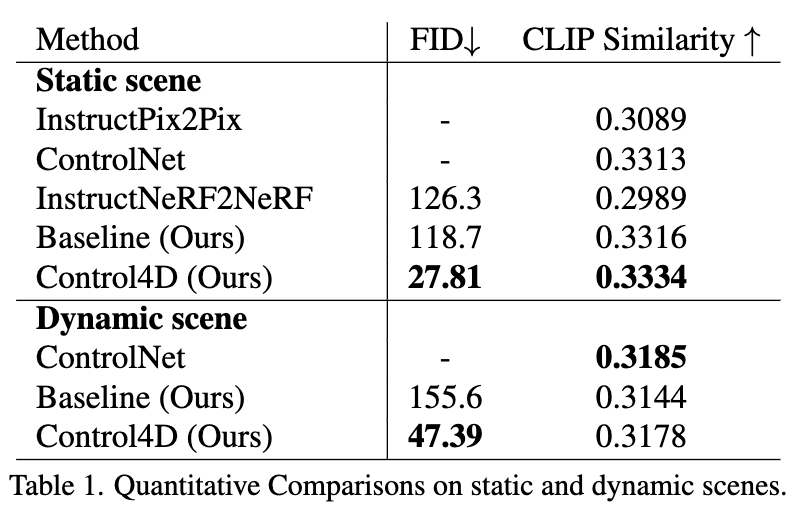
定量实验
作者在5个静态和4个动态场景中进行了定量实验。结果如表1所示。首先,在肖像编辑的背景下比较了Instructionpix2pix和ControlNet。ControlNet在主题和编辑提示之间表现出比Instructionpix2pix更好的一致性。进一步比较了方法Control4D与基线方法和Instruction Nerf2-Nerf。方法和基线,加上ControlNet的帮助,在编辑提示方面实现了卓越的一致性。此外,还评估了Fŕechet起始距离(FID)度量。结果显示,该方法显著优于基线和Instruction Nerf2Nerf,证明了作者的4D GAN在产生高质量和逼真效果方面的有效性。
消融研究
「多层次生成」 。作者进行了消融研究,以评估提出的多级引导策略的有效性。结果如下图8所示。观察到,当使用基于单级GAN的生成时,方法很容易陷入模式崩溃。这主要是因为使用的数据集只包含单个个体,并且在训练过程中仅依赖GAN损失可能导致鉴别器过拟合。因此,生成器很难产生有意义和多样化的结果。当在第1和第3级结合基于GAN的生成时,观察到作者的方法不会出现模式崩溃。然而,生成的输出相对模糊,缺乏清晰度和精细的细节。另一方面,当同时使用基于GAN的所有三个级别的生成时,作者的方法获得了最佳结果,突出了多级引导策略在4D编辑中提高稳定性和生成输出质量的重要性。

「分阶段训练战略」。作者进行了一项消融研究,以评估提出的分阶段训练策略的有效性,结果如下图7所示。当不使用分阶段训练策略时,观察到网络无法稳定地学习标准空间和流量。这会导致生成的输出发生扭曲变形,破坏优化结果的质量和一致性。当采用分阶段训练策略时,包括首先编辑标准空间,然后学习流程,最后进行同时微调,我们可以获得稳定、高质量和一致的优化结果。

结论
综上所述,Control4D 是一种在动态4D 场景中实现高保真和时间一致性编辑的新方法。它使用了一个高效的4D 表示和一个基于扩散的编辑器。代替直接监督,Control4D 学习从编辑器生成,避免不一致的信号。鉴别器根据编辑后的图像学习生成分布,并相应地更新生成器。来自编辑图像的多层次信息增强了生成器的学习过程。实验结果证明 Control4D 在实现照片真实感和一致的4D 编辑方面的有效性,超过了以前在现实世界场景中的方法。它代表了基于文本的图像编辑的一个重大进步,特别是对于动态场景。Control4D 为进一步研究高质量的4D 场景编辑打开了可能性。
「局限性」。由于使用了标准的空间+流表示。作者的方法依赖于4D场景中的流来展示简单和平滑。这对该方法在有效处理快速和广泛的非刚性运动方面提出了挑战。此外,该方法受到ControlNet的约束,它将编辑的粒度限制在一个粗略的级别。因此,它无法形成精确的表达式或动作编辑。该方法还需要对编辑过程进行迭代优化,并且不能在一个步骤中完成。
参考
[1] Control4D: Dynamic Portrait Editing by Learning 4D GAN from 2D Diffusion-based Editor
更多精彩内容,请关注公众号:AI生成未来



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









