










文章链接:https://arxiv.org/pdf/2408.03046
git链接:https://github.com/Cranken/CPD
亮点直击
提出统一模型压缩框架:包含梳理、剪枝和蒸馏三个步骤,其中梳理步骤提取架构依赖,使剪枝不依赖特定模型。
结合剪枝与知识蒸馏:研究了这两者的结合,进一步提升剪枝后模型的性能。
性能提升与效率优化:通过与基线模型对比,展示了在性能可接受的前提下显著提高模型效率,如在ResNet-50上实现了超过2倍的加速效果。
轻量且高效的模型对于资源有限的设备(如自动驾驶车辆)至关重要。结构化剪枝提供了一种有前途的模型压缩和效率提升方法。然而,现有方法通常将剪枝技术与特定的模型架构或视觉任务绑定在一起。为了解决这一局限性,本文提出了一种新颖的统一剪枝框架:Comb, Prune, Distill (CPD),它同时解决了模型无关和任务无关的问题。本文的框架采用梳理步骤来解决分层层次依赖问题,从而实现架构独立性。此外,剪枝流程根据重要性评分指标自适应地移除参数,无论视觉任务是什么。为了支持模型保留其学习到的信息,在剪枝步骤中引入了知识蒸馏。广泛的实验表明,本文的框架具有广泛的适用性,包括卷积神经网络(CNN)和Transformer模型,以及图像分类和分割任务。在图像分类中,实现了最高4.3倍的加速,准确率损失为1.8%;在语义分割中,最高加速达1.89倍,mIoU损失为5.1%。
方法
A. 框架概述
下图2展示了本文方法的概述。本文的方法依赖于三个组件的结合。如前所述,需要确保输入到模型中特定操作(如加法和乘法)的维度匹配。为此,引入了一种分层依赖解析算法,旨在检测这些依赖关系。该算法生成了一组耦合组,其中包括需要同时剪枝的参数以保持一致的通道维度。
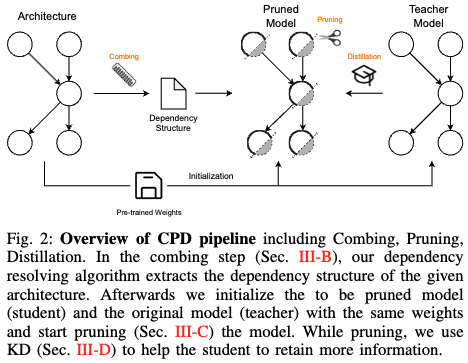
基于这些耦合组,可以开始对给定模型进行剪枝。不是随机选择一个组并剪枝其中的神经元,而是使用基于Hessian的重要性评分对神经元进行排序,根据其重要性在每次迭代中移除最不重要的神经元。为了辅助剪枝并保持预测性能,还研究了将知识蒸馏与模型的任务特定损失结合使用。
B. 梳理流程
首先,将一个模型形式化为其包含的一组n个操作,即。为了找到模型层之间的输出-输入依赖关系,需要定义两个操作之间的直接关系。
定义 III.1(直接关系)。δ 和 之间直接相连,中间没有停止操作。在此上下文中,停止操作是指可能改变输入和输出之间通道维度大小的操作,例如线性层或卷积层。注意,诸如reshaping之类的操作不被视为停止操作,因为它们不改变大小,只是改变通道维度的布局。下图3展示了模型中直接关系的一个示例。
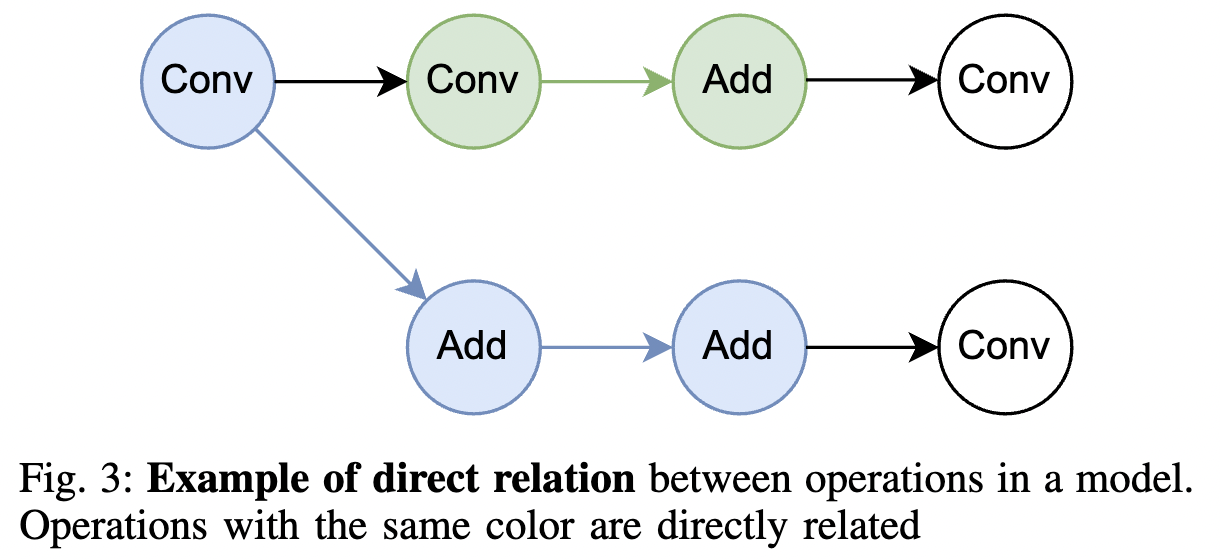
在网络中还需要考虑另一种操作类型,即定义的耦合操作。耦合操作的主要特点是它们接受多个输入,并要求输入在至少一个通道维度上匹配。耦合操作“耦合”了两个输入,这些输入的通道维度在剪枝时必须保持一致,因此这些输入的前几层应该一起剪枝。常见的此类操作示例是加法或矩阵-矩阵乘法。将模型ϕ中的所有耦合操作集合记为ϕ。
基于这些定义,可以找到给定停止操作的所有直接后续耦合操作:
![]()
最后,为了找到模型中的最终耦合组,将所有共享至少一个共同耦合操作的操作累积起来,如下图4所示,即:
![]()
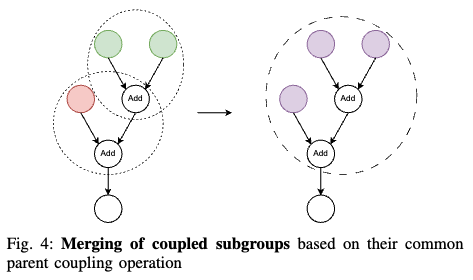
此时,这些耦合组仅用于指定在给定剪枝步骤中哪些操作的输出通道应一起剪枝。然而,每个耦合组中的操作也有一组直接后续操作。这些后续操作依赖于其前一个操作的输出通道维度,从而导致固有的输出依赖性。因此,还必须剪枝后续操作的输入通道维度,以确保层之间输入和权重的一致性。
C. 剪枝流程
一旦依赖解析算法识别出耦合组,模型的剪枝过程就可以开始。首先,需要决定在给定的剪枝步骤中要移除哪些操作和通道。为此,采用了一种基于Hessian的重要性评分方法,该方法量化了参数或通道对模型预测性能的重要性。为了在减少模型规模的同时保留性能,通过结合知识蒸馏来增强剪枝过程,使用未剪枝的模型作为教师模型。
重要性评分。尽管从模型中随机移除参数可能会取得一定的成功,但采用系统的参数排序和选择策略被证明是一种更有效的方法。这些策略通过给定模型量化参数的重要性。为此,已经提出了多种重要性评分方法。在这项工作中,选择基于Hessian重要性评分的贪婪策略。需要注意的是,本文的剪枝方法独立于实际的重要性评分。本文提出了一种基于Hessian的重要性函数,因为它在剪枝中效果显著。研究表明,损失函数的平坦曲率轮廓对剪枝引入的小扰动更具抵抗力。巧合的是,损失函数的曲率轮廓对应于Hessian矩阵的特征值集合。对于给定的损失函数L,Hessian矩阵定义为

其中, 和 代表模型权重 的元素。由于只需要 Hessian 矩阵的特征值,更具体地说,是特征值的 Frobenius 范数 ,可以跳过 Hessian 矩阵的复杂计算,转而计算:
![]()
其中, 是正态分布中的随机向量。与其直接计算 ,可以通过有限差分近似上述方程 ,其中 是一个小的正数。此外,引入一个二进制mask 给模型中的每个可剪枝参数,而不是直接剪枝给定权重 。mask 初始化为 ,这得到了门控权重 。
最后,可以定义二进制 及其对应权重通道的重要性评分为:
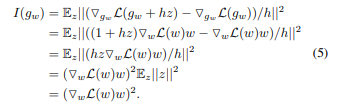
在这里,使用关系 进一步简化方程。由于在反向传播过程中可以获取权重及其梯度,因此这种重要性评分可以以高效的方式计算。此外,引入一个正则化参数 ,旨在根据剪枝的预期性能影响来规范化重要性评分。由于无法轻易预计算精确的影响,因此使用代理评分。由于内存减少与网络加速的相关性比其他指标(如FLOPs)更直接,特别使用内存规范化。
为了计算移除给定权重或操作的单个通道的内存复杂度,计算 ,其中 是批量大小, 和 分别是输出张量的高度和宽度。要计算整个mask 参数 的总内存复杂度,计算 。由于是一个二进制mask ,因此只有剩余的未剪枝参数会影响内存复杂度。因此,最终的重要性评分由下式给出:
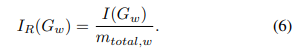
模型剪枝。通过制定一种对模型中神经元重要性进行排名的方法,可以逐步掩蔽它们,直到达到所需的总体剪枝参数阈值。为此,采用贪婪策略,在固定的训练迭代间隔内剪枝参数。在这个间隔内,计算反向传播过程中的每个神经元的重要性评分,并在整个间隔内累积这些评分。由于不仅仅剪枝单个神经元,而是剪枝神经元组,因此在迭代结束时汇总个别评分,以计算整个组的重要性评分。最后,通过掩蔽移除剪枝间隔内重要性最低的神经元组,即重要性评分最低的组。
D. 知识蒸馏
除了使用正常的任务损失外,还使用知识蒸馏(KD)来辅助剪枝和微调过程。KD 的思想是使用较大的教师模型在训练过程中指导较小的学生模型。在其最简单的形式中,这通过尝试使学生模型的输出与教师模型的输出匹配来实现。具体来说,当给定教师模型、学生模型 及其各自的输出类别概率分布 时,本文的目标是优化以下方程:
![]()
其中 是损失函数, 是学生模型和教师模型输出类别预测概率分布之间的KL散度。
继承了基本形式的 vanilla KD,已经引入了各种基于 logit 的 KD 框架,以对齐教师和学生模型的输出,同时消除结构冗余。选择其中一些工作来研究它们在与本文提出的剪枝流程相结合时的适用性和普遍性。这意味着严格关注模型无关的 KD 方法,并排除例如 transformer 特定的 KD 方法。相反,在实验中包括任务特定的 KD,因为它不会影响本文剪枝流程的普遍性。
通道级知识蒸馏(CWD) 用于密集预测任务。与基本的基于 KL 的蒸馏方法相比,CWD 的主要区别在于最小化通道级输出概率分布之间的 KL 距离。具体而言,CWD 不仅计算每个类别概率之间的 KL 距离,而是以通道级的方式计算每个像素的 KL 距离。
研究者们将输出激活概率分布,即特征激活图,表示为 ,其中 是通道索引, 是空间位置。因此,CWD 损失的定义为:
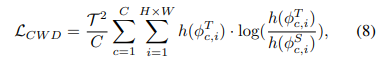
其中 是用于计算输出概率分布的相同温度超参数。然后用 替换方程 7 中的标准 。作者假设,由于方程 8 中使用的 KL 散度的不对称性,当 较大时,即在特征激活图的高显著性区域,学生模型更有效地最小化信息丢失。在密集预测实验中,发现使用 CWD 比标准 KL 公式取得了更好的结果,这也支持了这一假设。
跨图像关系知识蒸馏(Cross-Image Relational Knowledge Distillation) 是另一种专门为语义分割设计的 KD 方法。作者的主要思想是将跨图像关系知识引入 KD 过程。这种方法通过三个额外的损失扩展了方程 7 给出的标准 KD 形式。首先,他们引入了一个小批量像素对像素损失 ,旨在实现同一小批量内输出特征图的像素级对齐。这是通过指导学生学习教师为一个小批量中所有图像生成的成对跨图像关系信息来完成的。特别地,本文的目标是确保学生的特征图成对相似度矩阵与教师生成的矩阵紧密匹配。
由于 仅捕获小批量内的关系,作者引入了第二种类型的损失:基于记忆的像素对像素损失,记作 。该组件依赖于一个跨所有小批量的全局类感知记忆队列,以包含像素之间的全局依赖关系。对于学生和教师生成的每个输出嵌入,他们从记忆队列中采样指定数量的嵌入。然后,类似于 ,分别为学生和教师计算相似度矩阵。最后,学生通过调整以最小化矩阵之间的 KL 散度来模仿教师的相似度矩阵。
研究者们发现离散的像素embeddings可能不足以完全捕捉图像内部的复杂关系,因此引入了第三项,基于记忆的像素到区域损失 。其公式类似于 ,但区别在于记忆队列现在存储的是区域embeddings,而不是像素embeddings。
综合起来,得到以下损失方程:
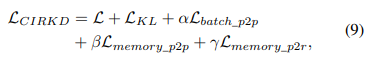
其中 。
实验
A. 设置
实现细节。实验中使用的模型来自 MMPretrain 和 MMSegmentation 的现成模型。所有训练和评估均在 NVIDIA GeForce RTX 2080 Ti GPU 上进行。为了训练和微调模型,使用了相应模型作者提供的原始配置。
数据集。在 ImageNet 数据集上进行实验,以评估不同架构的性能。为了验证本文在密集预测任务(如语义分割)上的剪枝方法,使用了 ADE20K 数据集。该数据集包含150种不同类别的物体和背景,分为超过 2 万张训练图像、2 千张验证图像和 3 千张测试图像。此外,本文还使用该数据集进行剪枝过程中的知识蒸馏(KD)消融研究。
B. 图像分类
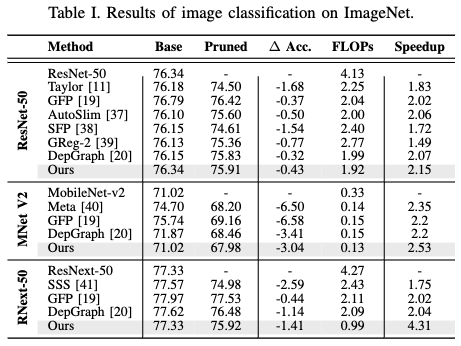
下表 I 展示了本文剪枝方法与之前最先进方法的对比结果。为了展示本文方法的广泛适用性,选择了几种架构不同的模型进行测试,包括使用残差连接的ResNet、使用深度卷积的MobileNet-v2,以及使用分组卷积的ResNext。结果表明,本文的方法结合了简单的剪枝标准与知识蒸馏(KD),在保持精度损失在可接受范围内的同时,达到了或超越了当前最先进的剪枝方法,实现了超过2.15倍的加速效果。以ResNext-50为例,甚至将FLOPs(浮点运算次数)减少了4.31倍,精度仅相对下降了1.8%。
C. 语义分割
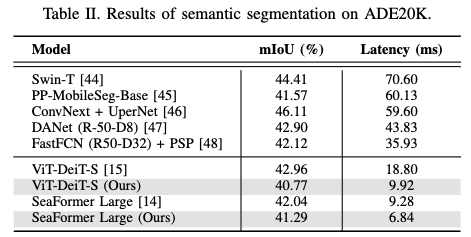
在ADE20K数据集上评估了SeaFormer和ViT模型的语义分割性能。在下表II中,所有实验均使用了通道级知识蒸馏(CWD)作为本文的蒸馏方法。例如,将ViT-DeiT-S的延迟降低了47%以上。对于SeaFormer-L,虽然只实现了26%的延迟改进,但性能损失更小,仅为1.7%。延迟是在导出的ONNX模型上测量的,以模拟真实世界的使用场景。每个结果都是在大量(n≥1000)评估中计算出的平均延迟。
D. 消融研究
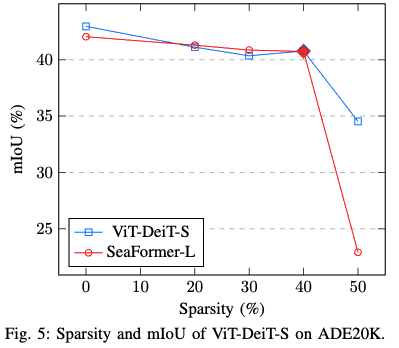
稀疏性与性能的权衡。在下图 5 中,展示了稀疏性对模型预测性能的影响。稀疏性计算为模型中去除的参数的相对百分比。在这个例子中,使用了 CWD KD 和 ViT-DeiT-S 模型。可以观察到性能在稀疏性达到约 40% 之前有一个预期的、相对稳定的下降,然后准确率出现了相当大的下降。其他模型也可以观察到类似的行为,尽管稀疏性的临界点可能会根据模型的不同而发生在更低或更高的值。假设临界点可能会随着原始模型的大小而变化,即较大的模型往往在较高的稀疏性下出现这一临界点,而较小的模型则相反。
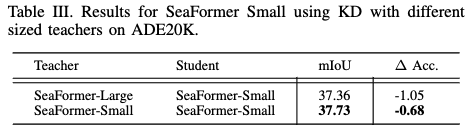
教师选择的影响。由于许多模型提供不同的架构变体,测试了使用同一家族中的更大教师模型的优势,而不是使用相同的未剪枝模型作为教师。下表 III 显示,在实验中,本文的方法可以使用未剪枝模型,而不是更大的教师模型。
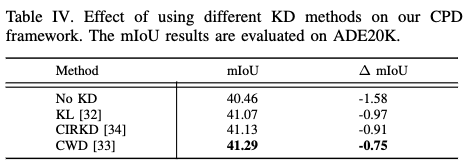
KD 方法的影响。为了测试不同的 KD 方法,选择使用 SeaFormer-Large 作为 ADE20K 数据集上的基线。在下表 IV 的实验中,发现使用 CWD 进行剪枝时保留了原始模型最多的性能。在剪枝实验中,发现 CWD 比 CIRKD 表现更好。假设这是因为在剪枝过程中,使用的是已经预训练的模型作为起点,而不是从未训练的学生模型开始。因此,CIRKD 关注的更多的全局语义信息已经由模型学习到,并且在剪枝过程中保持了这些信息,同时去除了较小的细节。因此,理论上认为,在剪枝过程中,KD 的最重要部分是确保没有细节丢失。
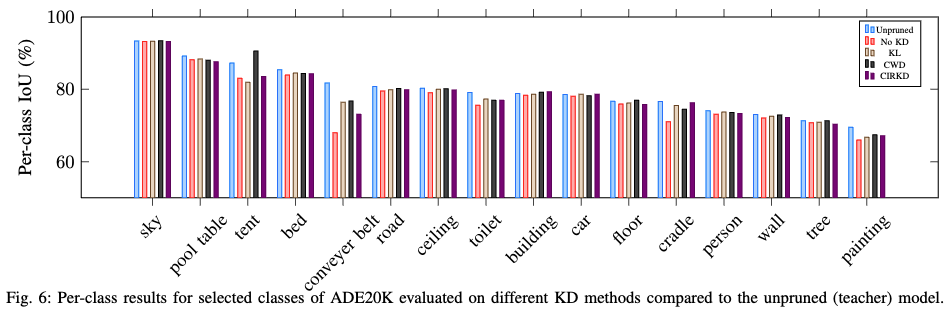
下图 6 显示了在 ADE20K 数据集上不同 KD 方法的一些单独类别得分。由于类别数量众多,本文选择了未剪枝教师模型中 mIoU 最高的 16 个类别。每种 KD 方法在模型稀疏性为 20% 时进行了评估。可以观察到,无论 KD 方法如何,剪枝模型的性能通常与其未剪枝的教师模型相似。KD 方法的选择似乎对单独类别的性能没有大的影响,因为剪枝模型中的类别得分相似。与未剪枝模型相比,最大的差异出现在较小和不常见的类别上。在这些类别中,也可以测量到 KD 方法之间的最大差异。
结论
本文提出了一个新颖的统一模型压缩框架,称为 CPD,包含三个主要步骤:梳理、剪枝和蒸馏。为了克服以前依赖于网络架构的模型特定剪枝方法的局限性,本文的框架结合了一个依赖关系解析算法,确保其灵活性,可以应用于各种架构。此外,将知识蒸馏(KD)结合到框架中,以改善剪枝后的模型。本文展示了与以前的最先进方法相比,在剪枝过程中使用 KD 可以提高模型的性能保留。对两个数据集的广泛实验证明了 CPD 框架的有效性。
参考文献
[1] Comb, Prune, Distill: Towards Unified Pruning for Vision Model Compression
更多精彩内容,请关注公众号:AI生成未来

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









