










文章链接:https://arxiv.org/pdf/2409.15278
github链接:https://github.com/AFeng-x/PixWizard
亮点直击
- 任务统一:针对视觉任务的多样性,提出将其框架化为图像到图像的转换问题,并通过后处理将生成的可视化效果转化为所需格式,以简化表示形式的挑战。
- 数据构建:构建了一个包含3000万个数据点的全面训练集,支持五大功能,包括图像生成、编辑、恢复、定位和密集预测,旨在整合视觉领域的任务和数据多样性。
- 架构设计:采用基于流的 Diffusion Transformer(DiT)作为基础模型,强调其灵活性和稳定性,并通过动态分区和填充方案增强模型对输入图像的处理能力,结合结构感知和语义感知指导,以支持多模态指令。
总结速览
解决的问题
图像生成、操作和转换的复杂性,特别是基于自由形式语言指令的多种视觉任务。
提出的方案
- 设计了一个多功能的图像到图像视觉助手PixWizard,整合各种视觉任务到一个统一的图像-文本到图像生成框架。
- 构建了一个全面的Omni Pixel-to-Pixel Instruction-Tuning Dataset,使用详细的自然语言指令模板。
应用的技术
- 基于Diffusion Transformers (DiT)作为基础模型,扩展其功能以支持灵活的任意分辨率机制。
- 结合结构感知和语义感知的指导,以有效融合输入图像的信息。
达到的效果
- PixWizard展示了在多种分辨率图像上的卓越生成和理解能力。
- 具有良好的泛化能力,能够处理未见过的任务和人类指令。
Omni Pixel-to-Pixel Instruction-Tuning数据集
为了使我们的图像到图像视觉助手具备全面的图像生成、操作和翻译功能,首先编译了一个用于视觉指令调优的多任务、多模型训练数据集,该数据集由七个主要领域的3000万个实例组成。据我们所知,这个数据集是最大、最多样化、最易于使用的图像指令图像三元组数据集。它由开源和内部数据集构建,在MLLM和手动审查的帮助下进行过滤,如图1所示:


PIXWIZARD
PixWizard是一个多功能的图像到图像模型,经过自定义的全像素到像素指令调优数据集的微调。本节将从模型架构(如下图2所示)和训练策略的角度介绍PixWizard框架的细节。
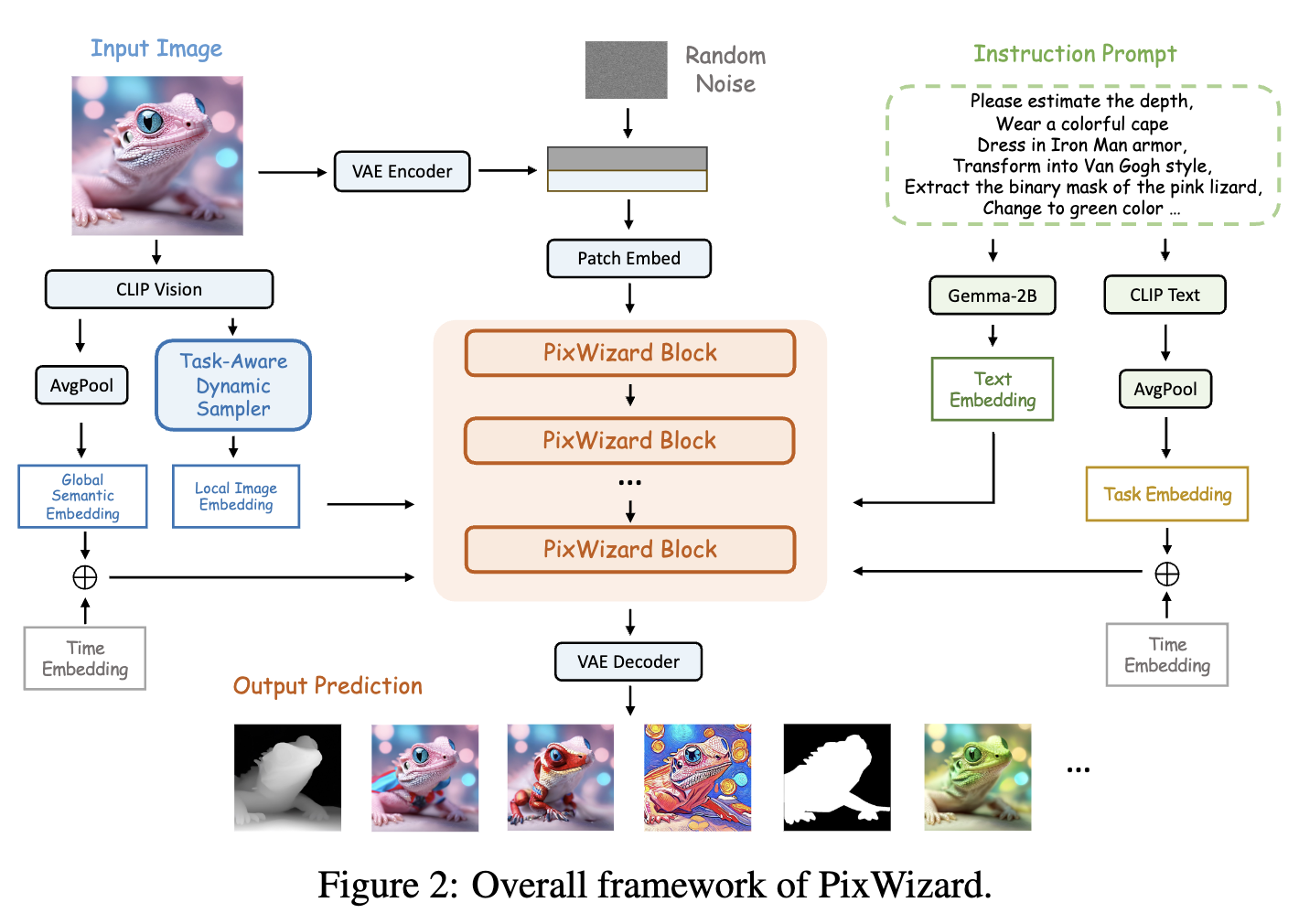
基于流的条件指令调优
之前的研究表明,对于图像转换和编辑任务,微调大型扩散模型的效果优于从头开始训练模型。因此,使用预训练的Lumina-Next-T2I检查点初始化PixWizard的权重,该模型是一个基于流的DIT,利用其广泛的文本到图像生成能力。学习一个网络 v θ v_\theta vθ,该网络在给定图像条件 c I c_I cI和文本指令条件 c T c_T cT的情况下预测速度场 u t u_t ut。最小化以下损失函数:
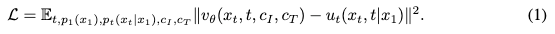
架构
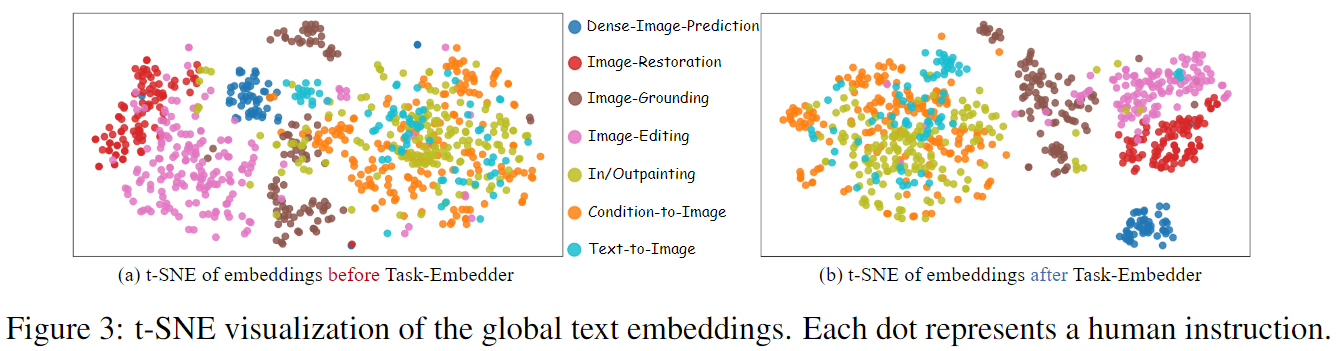
文本编码器。首先使用Gemma-2B作为PixWizard中的文本嵌入器,以对文本提示进行编码。然而,在多任务学习中,仅依赖文本指令不足以准确指导模型执行用户命令。为更好地指导生成过程,结合了CLIP文本编码器。对CLIP文本嵌入应用全局平均池化,以获得粗粒度的文本表示,然后通过基于MLP的任务嵌入器生成任务嵌入。该嵌入随后通过调制机制与时间步嵌入相加,集成到PixWizard Block中。如图3所示,这种方法自适应地在潜在空间中聚类相似的任务指令,同时将不同任务的指令分离,有助于指导模型生成过程朝正确的任务方向发展。
结构感知指导
为了有效捕捉输入图像条件的整体结构特征,首先使用变分自编码器(VAE)从SDXL对图像进行编码。接下来,沿通道维度将图像潜在向量与噪声潜在向量连接在一起。根据(Brooks et al., 2023),向补丁嵌入器添加额外的输入通道,这些新通道的权重最初设置为零。
语义感知指导
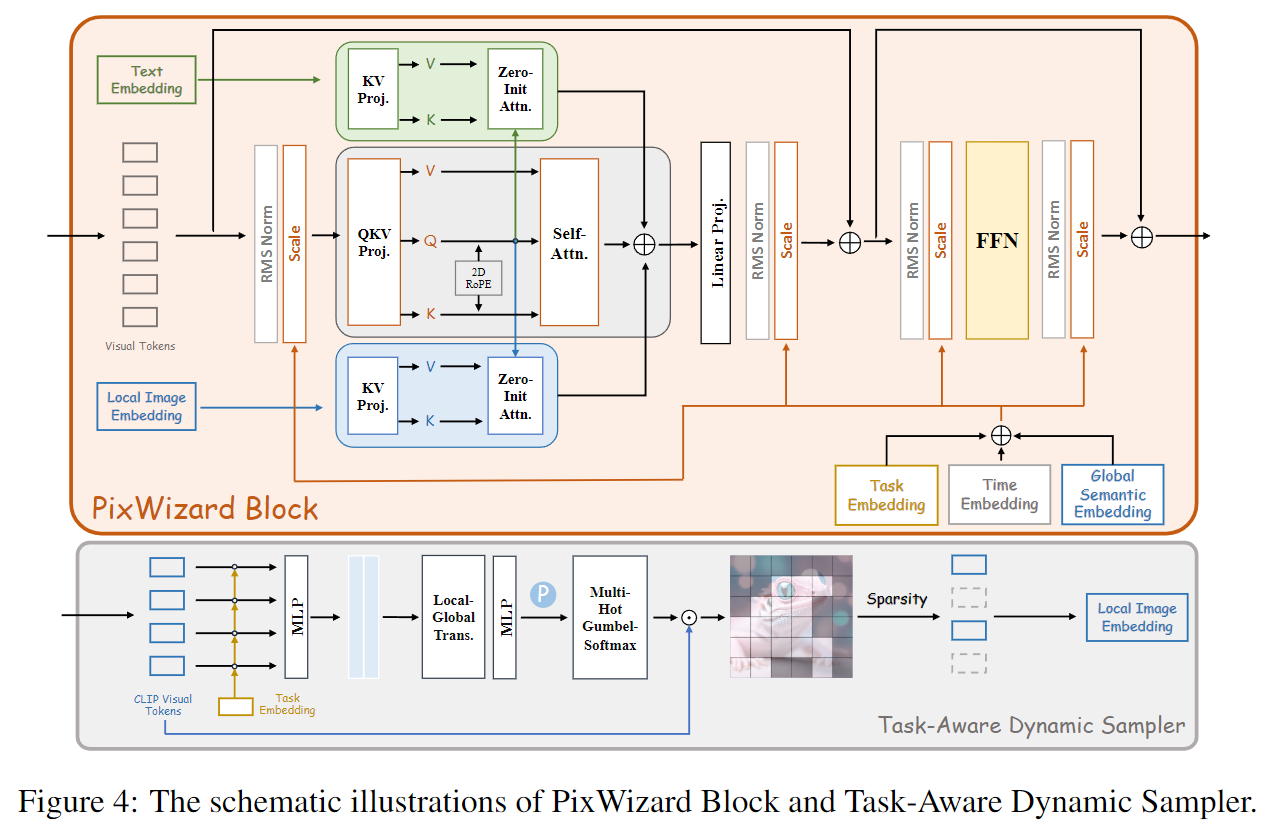
除了识别结构特征外,语义信息也至关重要。因此,使用CLIP L/14-336获取语义图像嵌入。在PixWizard块中引入两个零初始化的注意力机制,使潜在目标图像token能够从条件的键和值中查询信息。具体而言,采用零初始化的门控机制,逐步将条件图像和文本信息注入到token序列中。给定目标图像查询 Q i Q_i Qi、键 K i K_i Ki、值 V i V_i Vi,以及文本指令的键 K t K_t Kt和值 V t V_t Vt,和条件图像的键 K c i K_{ci} Kci及值 V c i V_{ci} Vci,最终的注意力输出被表述为:
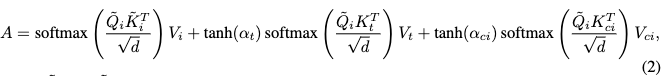
其中, Q ~ i \tilde{Q}_i Q~i和 K ~ i \tilde{K}_i K~i表示应用RoPE(Su et al., 2024), d d d是查询和键的维度, α \alpha α表示在门控交叉注意力中的零初始化可学习参数。然而,将所有图像token输入到注意力层中通常会导致显著的计算需求,我们还发现并非所有语义token与特定任务相关。为了解决这个问题,引入了任务感知动态采样器,旨在为每个任务选择最相关的语义token。该采样器使用由四个线性层和激活函数组成的轻量级排名网络。受DynamicViT启发,我们采用一种技术,将图像token映射到局部和全局特征。此外,我们集成任务嵌入 x task x_{\text{task}} xtask,以帮助采样器识别与任务最相关的token。计算过程被表述为:
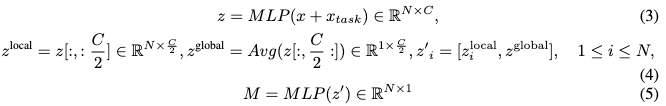
其中, M i M_i Mi表示第 i i i个token的重要性。然而,在实践中实现token稀疏化是具有挑战性的。基于重要性分数直接采样token是不可微的,这阻碍了端到端的训练。为了解决这个问题,使用Gumbel-Softmax技术,并将其调整为多热Gumbel-Softmax(MHGS),以实现同时采样前 K K K个token。

其中,Gumbel-Softmax的输出是一个多热张量,表示保留token的掩码。 ⊙ \odot ⊙表示哈达玛积,表示按重要性分数前 K K K个token的权重为1,因此被保留,而剩余的 ( N − K ) (N - K) (N−K)个token的权重为零并被丢弃。最后,我们为每个Transformer块的每一层配备一个独立的任务感知动态采样器。这种方法不仅有助于捕捉每层所需的最相关语义特征,以满足不同任务的要求,还降低了注意力过程中的计算成本。
任意分辨率
PixWizard继承了(Zhuo et al., 2024)提出的动态分区和填充方案,使模型能够在微调和推理过程中处理任意分辨率和纵横比的图像。然而,在实践中,不同任务所需的分辨率可能有显著差异。为了支持更灵活的任意分辨率处理,并尽可能保留每个图像的原始分辨率,使用[512², 768², 1024²]作为分辨率中心,以生成一组候选补丁分区。在训练过程中,将具有相似分辨率的数据项分组到同一桶中,以确保每批次内最长和最短序列的长度不会过于不同,从而最小化填充token的使用,提高训练效率。在推理过程中,通过结合NTK感知缩放RoPE和夹心归一化,PixWizard还表现出卓越的分辨率外推能力。
两阶段训练和数据平衡策略
为了释放模型的潜力并提高其在数据集较小任务上的性能,我们提出了一种两阶段训练和数据平衡策略。
阶段1:在此阶段,我们通过将预训练的文本到图像模型的权重与随机初始化的新模块权重结合来初始化模型的权重。首先选择数据集较小的任务,并为每个数据集分配一个采样权重,以增加其数据量。该权重决定了在单个周期内数据集的重复次数。通过这种方法,每个任务大约有20k个数据点。然后,我们随机选择来自其他任务的训练样本以匹配此规模,创建我们的第一阶段训练数据集。训练过程持续4个周期。
阶段2:在第二阶段,我们使用第一阶段获得的权重初始化模型,并将所有收集的数据组合进行进一步训练。为了平衡任务,我们手动为每个数据集分配采样权重,如果权重小于1.0,则随机选择数据。我们还以1:1的比例将文本到图像数据包含在内,形成我们的第二阶段训练数据集。在此阶段,总训练数据量达到2000万个样本。
实验
第一部分结果
设置
对于图像修复,遵循之前的研究(Conde et al., 2024; Potlapalli et al., 2024),在训练期间准备各种修复任务的数据集。对于评估,首先选择两个代表性基准:Rain100L用于去雨,SIDD用于去噪。此外,为了进一步评估其他修复任务的性能并检验零-shot能力。
对于图像定位,在gRefCOCO、RefCOCO和RefCOCO+的验证和测试集上评估引用分割任务。为了评估与专门模型的性能差距,报告几种专家方法的结果,并主要将我们的方法与两个统一模型进行比较:Unified-IO和InstructDiffusion。按照标准实践(Liu et al., 2023a),使用累积IoU (cIoU)作为性能指标。
密集图像预测任务评估三项视觉任务:ADE20k 用于语义分割,NYUv2和SUNRGB-D 用于单目深度估计,以及NYU-Depth v2用于表面法线估计。对于语义分割,通过识别最近邻的RGB颜色值来分配标签,使用平均交并比 (mIoU)指标评估准确性。对于单目深度估计,对输出图像在三个通道上进行平均,并应用训练期间使用的线性变换的逆向,获得范围在[0,10]米内的深度估计。准确性使用均方根误差 (RMSE)进行评估。对于表面法线估计,从输出图像中恢复相应的法向量,并使用平均角误差来评估准确性。

结果
表1展示了与近期最先进的任务特定和一体化方法的全面性能比较。结果显示,尽管去噪和去雨数据仅占整体训练集的一小部分,我们的方法在统一方法中表现优异,甚至超越了一些任务特定的方法。在图像定位任务中,PixWizard在RefCOCO(验证集)上比基于扩散的通用模型InstructDiffusion高出4.8 cIoU。然而,与其他高度专业化模型相比,仍有改进空间。此外,如图6所示,PixWizard支持灵活的指令,能够不仅直接在图像上突出和可视化目标对象,还生成相应的二进制掩膜。这突显了其在现实世界互动和实际应用中的强大性能。
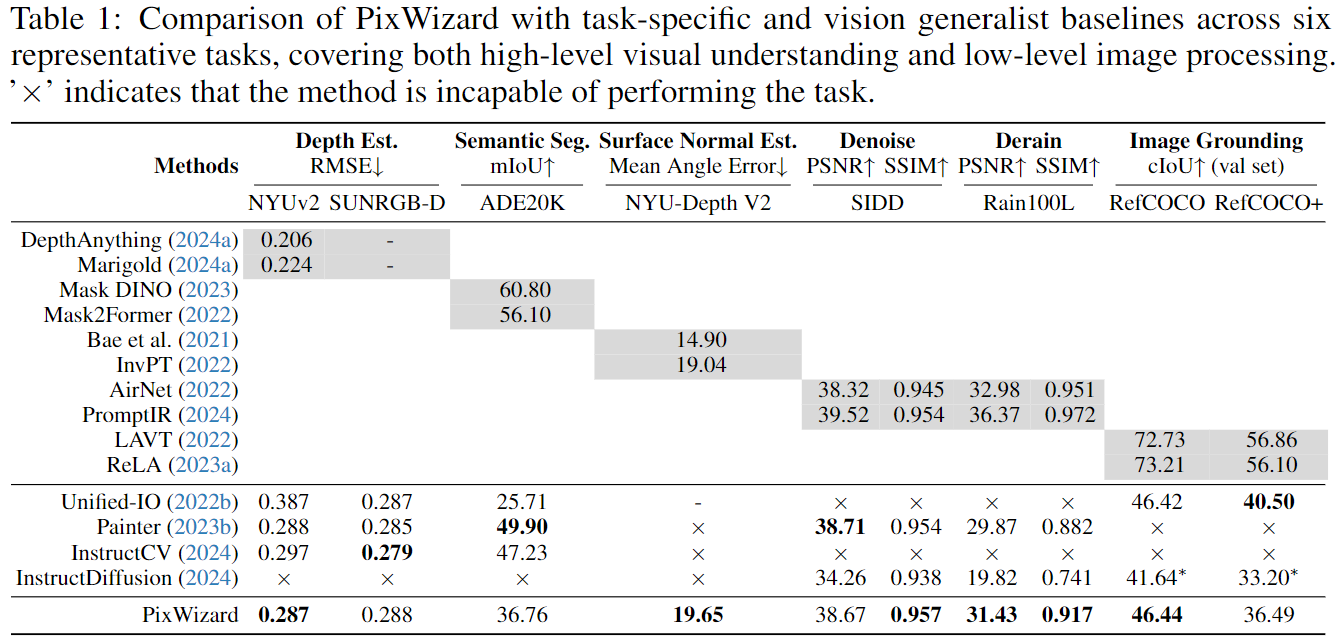

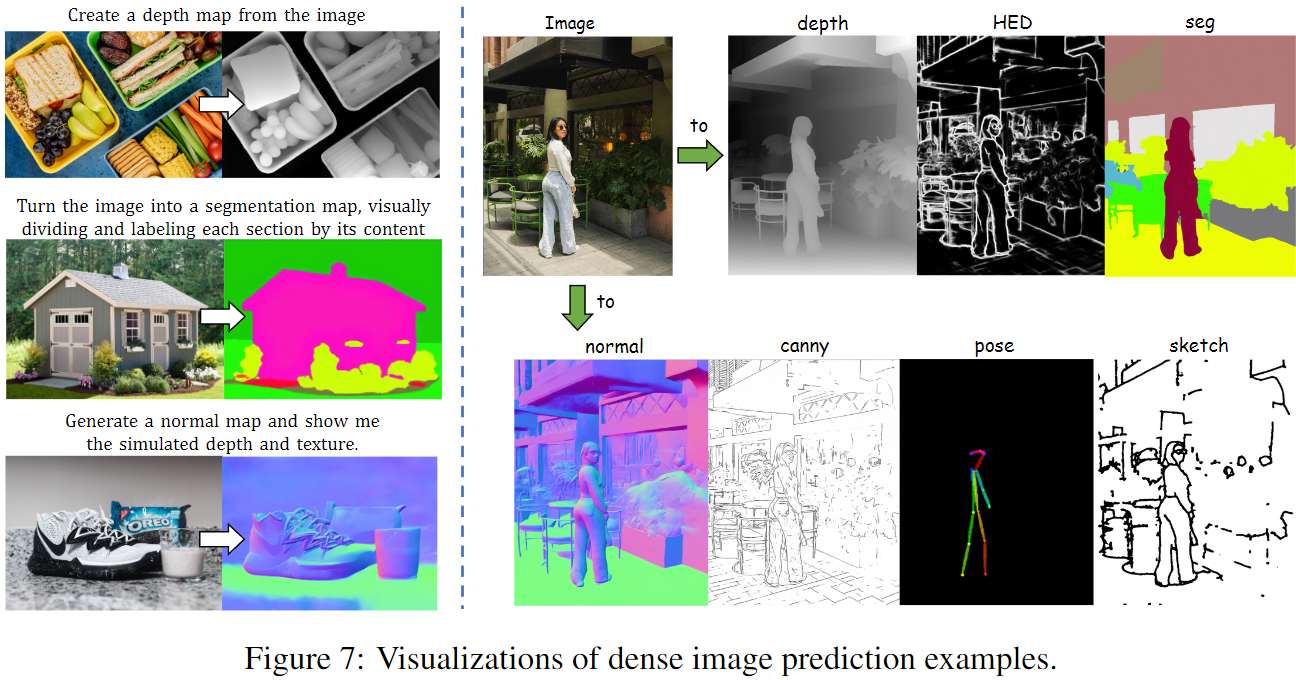
对于密集预测任务,在所有三个任务中,PixWizard在与通用基线和任务特定基线的竞争中表现出色。在NYUv2测试集上的深度估计中,PixWizard在RMSE上相比Unified-IO提高了10.0%,并且与Painter和InstructCV的表现相似。在语义分割中,PixWizard在mIoU上超越Unified-IO,提升了11.05分,尽管仍落后于其他方法。此外,图7展示了PixWizard的输出示例。通过为同一图像提供相应的任务特定提示,我们可以轻松生成相应的条件可视化,突显了PixWizard的重要实用价值。
第二部分结果(图像编辑)
设置
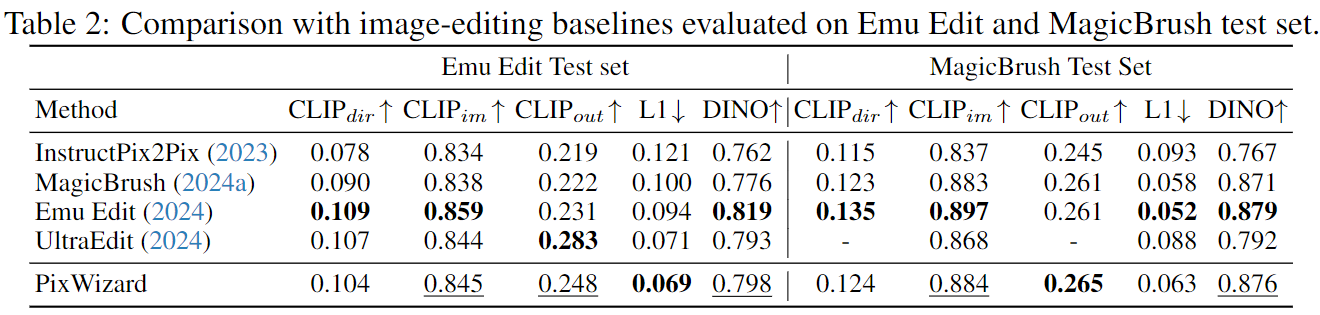
在MagicBrush测试(Zhang et al., 2024a)和Emu Edit测试(Sheynin et al., 2024)两个基准上评估PixWizard,以评估其图像编辑能力的有效性。为了公平比较,我们主要与以指令引导的图像编辑方法进行对比,包括InstructPix2Pix、MagicBrush、Emu Edit和UltraEdit。与Emu Edit一致,我们使用L1距离、CLIP图像相似度、DINO相似度、CLIP文本-图像相似度和CLIP文本-图像方向相似度作为指标。
结果
图像编辑
表2展示了我们与基线的结果。结果表明,我们的模型在自动化指标上始终超越InstructPix2Pix、MagicBrush和UltraEdit,并且在性能上与最先进的方法Emu Edit相当。图8提供了定性比较。我们的模型精准识别编辑区域,同时保留其他像素,展现了对给定指令的最佳理解。

第三部分结果(图像生成)
设置
本节重点评估PixWizard的生成能力,具体任务包括经典的文本到图像生成、可控图像生成、图像修复和图像外推。在可控图像生成中,我们评估PixWizard基于特定条件(Canny边缘图和深度图)生成图像的能力。我们通过比较输入条件与生成图像中提取的相应特征之间的相似度来评估可控性,具体使用深度图控制的RMSE和Canny边缘的F1得分。此外,为了评估生成图像的质量及其与输入文本的对齐程度,报告了FID(Fréchet Inception Distance)和CLIP-Score指标,所有实验在512×512的分辨率下进行。
在图像修复任务中,使用潜在扩散设置来测量FID和LPIPS,评估在40-50%图像区域需要修复时生成样本的质量。对于图像外推任务(outpainting),我们遵循MaskGIT设置,将图像向右扩展50%,并使用FID和Inception Score(IS)与常见基线进行比较。这两个任务在Places数据集中的30,000个512×512图像裁剪上进行评估。
在文本到图像生成任务中,使用两种主要评估方法。首先,直观展示PixWizard生成的图像示例。此外,计算两个自动评估指标:人类偏好评分(HPS)v2和MS-COCO数据集上的标准零-shot FID-30K。
可控生成结果
无需为每个模型单独训练,PixWizard是一个一体化解决方案,能够处理多种条件。如表3所示,PixWizard在深度条件下实现了最高的可控性和最佳的图像质量,同时在图像-文本对齐方面与当前的独立模型相当。图9展示了若干视觉样本,证明了我们方法的有效性。


图像修复结果
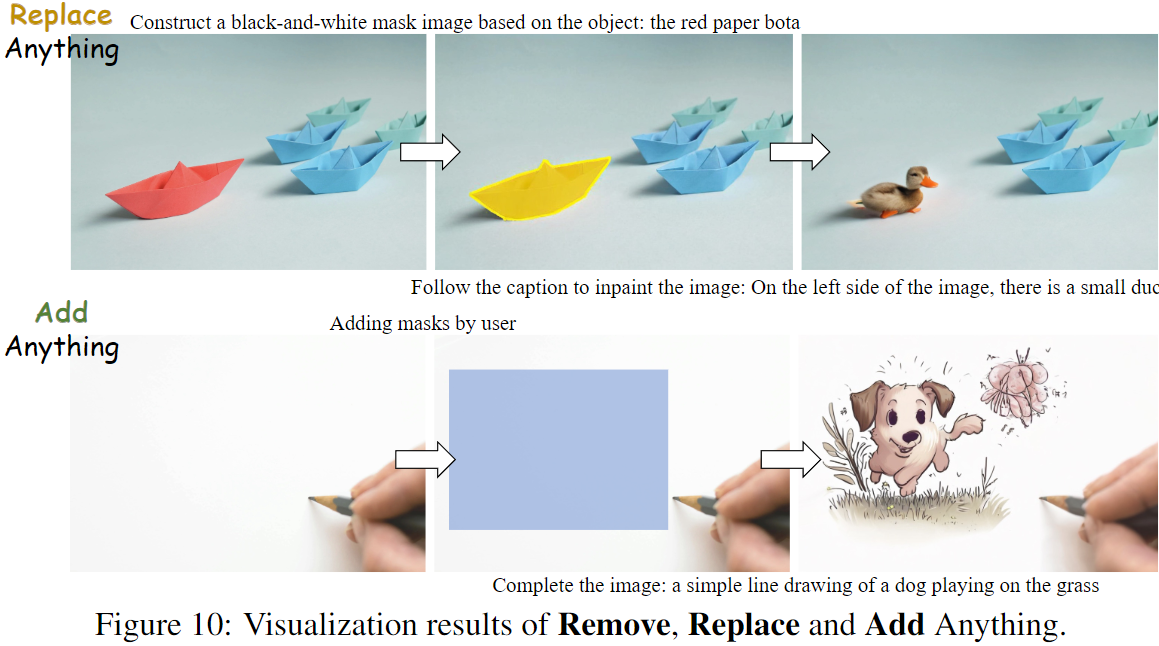
表3中与其他图像修复方法的比较显示,PixWizard在FID和LPIPS指标上提升了整体图像质量。这归因于PixWizard能够在空白画布上“绘画”,极大增强了其识别被遮挡区域并生成连贯内容的能力。通过这种图像修复能力,PixWizard支持更精确的图像编辑任务:
- Remove Anything:解决对象移除问题,允许用户在保持视觉无缝的情况下去除特定对象。过程包括识别和移除,随后将遮罩应用于原始图像,PixWizard填补该区域的适当背景细节。如图10所示。
- Replace Anything:允许用户在图像中替换任何对象。该过程与Remove Anything相似,但模型在移除对象的同时,确保用指定对象替换,背景保持一致。
- Add Anything:用户可以将任何对象插入图像,并自由放置。用户为所需区域添加遮罩并提供文本提示,PixWizard利用其强大的图像修复能力生成请求内容。

图像外推
在表3的定量比较结果中,PixWizard在图像外推任务上超越了其他基线,提供了7.54的FID分数和22.18的IS分数,展现了最先进的图像生成质量。图11的样本展示了PixWizard在各种场景和风格中合成图像的能力,灵活处理多个方向和纵横比的图像外推,并且边际一致性更好。

文本到图像生成
在表3的定量比较结果中,PixWizard在COCO数据集上测试零-shot性能时取得了9.56的FID分数。尽管某些模型的FID更低,但它们专注于文本到图像任务,且依赖显著更多的训练资源。此外,还评估了人类偏好评分(HPS v2),这一强有力的基准用以评估文本到图像合成中的人类偏好。PixWizard表现出色,生成的图像质量与流行的文本到图像生成器相当。图12提供了视觉样本,PixWizard支持高分辨率图像合成,最高可达1024×1024,且适用于任何分辨率和纵横比。


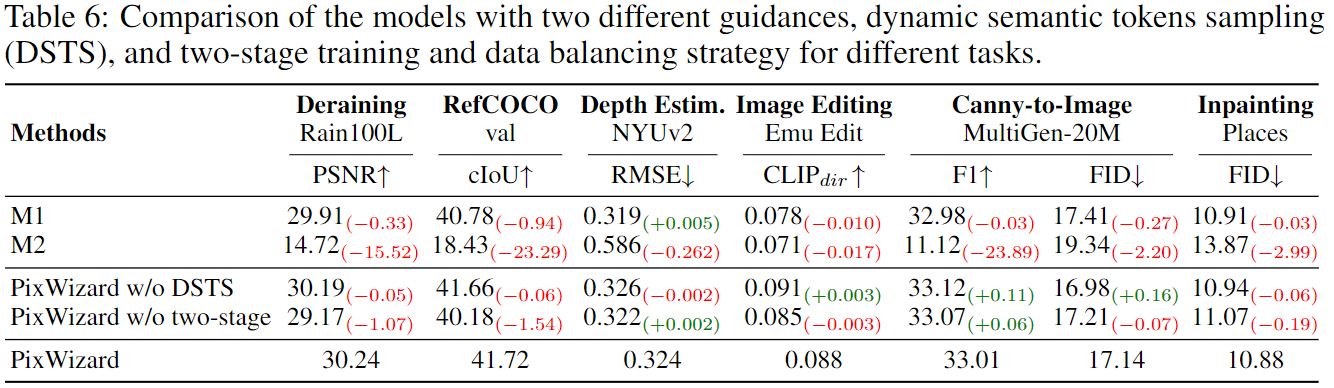
消融研究
对具有两种不同指导的模型进行比较,即动态语义标记采样(DSTS)和针对不同任务的两阶段训练和数据平衡策略。
讨论与结论
本研究探讨了如何从任务定义、数据构建和模型架构三个关键方面构建一个多功能的交互式图像生成助手。目标是创建一个能够精准遵循自由形式用户指令进行图像生成、操作和转换的系统。PixWizard,消除了对特定任务设计选择的需求,并在一系列多样任务中实现了高度竞争的性能,展现了强大的泛化能力。
然而,本研究仍存在一些局限性。首先,当前的模型架构尚不支持多图像输入条件,这在研究中是一个日益重要和有价值的方向。其次,在与专业化模型相比时,尤其是在分割和图像定位等挑战性任务上,仍有改进的空间。此外,文本编码器和基础模型的性能也发挥着至关重要的作用。更好的文本编码方法使模型能够更准确地理解和执行人类指令,而更大且更稳健的模型架构直接提升了最终输出的质量。值得注意的是,在PixWizard中提出的模块和策略可以轻松应用于其他强大的文本到图像生成器。
未来,将探索使用更先进的扩散基础模型,如SD3和FLUX,并继续推动这一有前景的方向,直到我们在视觉领域实现“GPT-4时刻”。
参考文献
[1] PixWizard: Versatile Image-to-Image Visual Assistant with Open-Language Instructions

















 909
909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









