










文章链接:https://arxiv.org/pdf/2504.04842
开源地址:https://fantasy-amap.github.io/fantasy-talking/

亮点直击
设计了一种双阶段视听对齐训练策略,以适配预训练的视频生成模型:首先在片段级别建立与输入音频对应的、包含背景和上下文对象(而不仅限于肖像本身)的连贯全局运动,随后构建精确对齐的唇部运动以进一步提升生成视频的质量。
摒弃了传统的参考网络用于身份保持的方法,转而设计了一个专注于面部的交叉注意力模块,该模块集中建模面部区域,并以一致的身份指导视频生成,从而简化流程。
引入了运动强度调制模块,显式控制面部表情和身体运动的强度,从而实现对肖像运动的可控操纵,而不仅限于唇部运动。
大量实验表明,FantasyTalking在视频质量、时间一致性和运动多样性方面达到了新SOTA。
总结速览
解决的问题
-
静态肖像动画化的挑战:从单张静态肖像生成可动画化的虚拟形象,难以捕捉细微的面部表情、全身动作和动态背景。
- 现有方法的不足:
-
依赖3D中间表示(如3DMM、FLAME)的方法难以准确捕捉细微表情和真实动作。
-
基于扩散模型的方法生成的内容真实性不足,通常仅关注唇部运动,忽略面部表情和身体动作的协调性。
-
背景和上下文对象通常是静态的,导致场景不够自然。
-
-
身份保持与动态灵活性的矛盾:现有方法在保持身份一致性和动态灵活性之间存在权衡问题。
提出的方案
- 双阶段音频-视觉对齐策略:
-
第一阶段(片段级训练):利用视频扩散Transformer模型的时空建模能力,建立音频与全局视觉动态(包括肖像、背景和上下文对象)的隐式关联,实现整体场景运动的连贯性。
-
第二阶段(帧级细化):通过唇部追踪掩码和音频映射的视觉token注意力机制,精确对齐唇部运动与音频信号。
-
- 身份保持优化:
-
摒弃传统的参考网络(易限制动态效果),改用专注于面部建模的交叉注意力模块,确保视频中身份一致性。
-
- 运动强度控制模块:
-
显式解耦角色表情和身体动作,通过强度调节实现动态肖像的可控生成(如增强表情或身体动作幅度)。
-
应用的技术
-
基于DiT的视频扩散模型:利用预训练的视频扩散Transformer(DiT)生成高保真、连贯的动态肖像。
- 多模态对齐框架:
-
音频驱动动态建模(片段级和帧级)。
-
唇部掩码引导的局部细化。
-
-
交叉注意力机制:替代参考网络,通过面部聚焦的交叉注意力模块保持身份一致性。
-
运动强度调制:通过额外条件输入控制表情和身体动作的强度。
达到的效果
- 更高真实性与连贯性:
-
生成动态肖像的面部表情、唇部运动和身体动作更自然,背景和上下文对象动态协调。
-
- 精确的音频同步:
-
帧级唇部细化确保唇动与音频信号高度同步。
-
- 身份保持与动态灵活性的平衡:
-
交叉注意力模块在保持面部一致性的同时,允许全身灵活运动。
-
- 可控运动强度:
-
用户可调节表情和身体动作的强度,超越传统仅唇部运动的限制。
-
- 实验验证:
-
在质量、真实性、连贯性、运动强度和身份保持方面优于现有方法。
-
方法
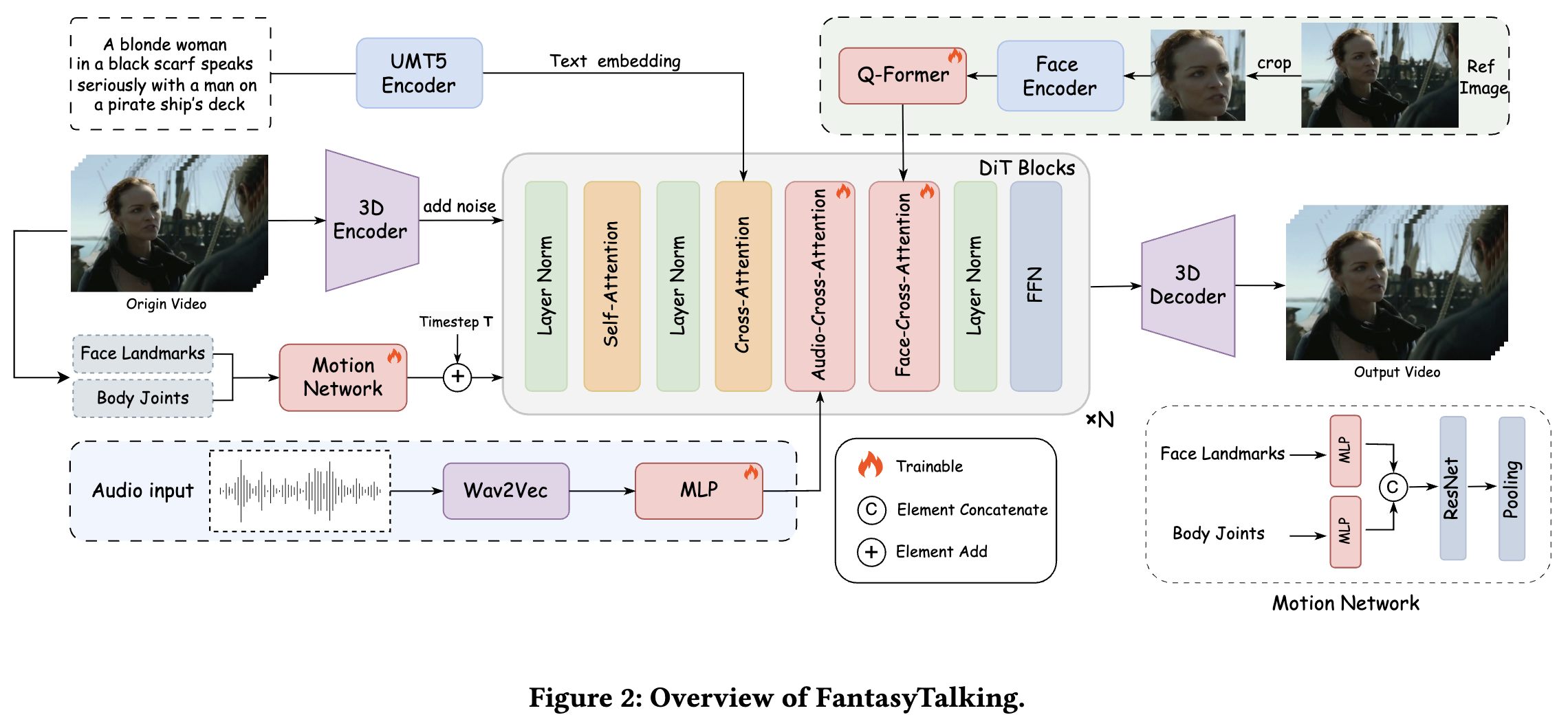
给定单张参考图像、驱动音频和提示文本,FantasyTalking 被设计用于生成与音频同步的视频,同时确保人物在动作过程中的身份特征得以保持。图2展示了FantasyTalking的总体框架。研究了双阶段方法以在注入音频信号时保持视听对齐。采用身份学习方法保持视频中的身份特征,并通过运动网络控制表情和运动强度。
双阶段视听对齐
视听对齐。本文使用Wav2Vec提取包含多尺度丰富声学特征的音频token。如下图3所示,音频token长度与视频token长度不同,其中、和分别表示潜在视频的帧数、高度和宽度。这两个token序列之间存在一一映射关系。
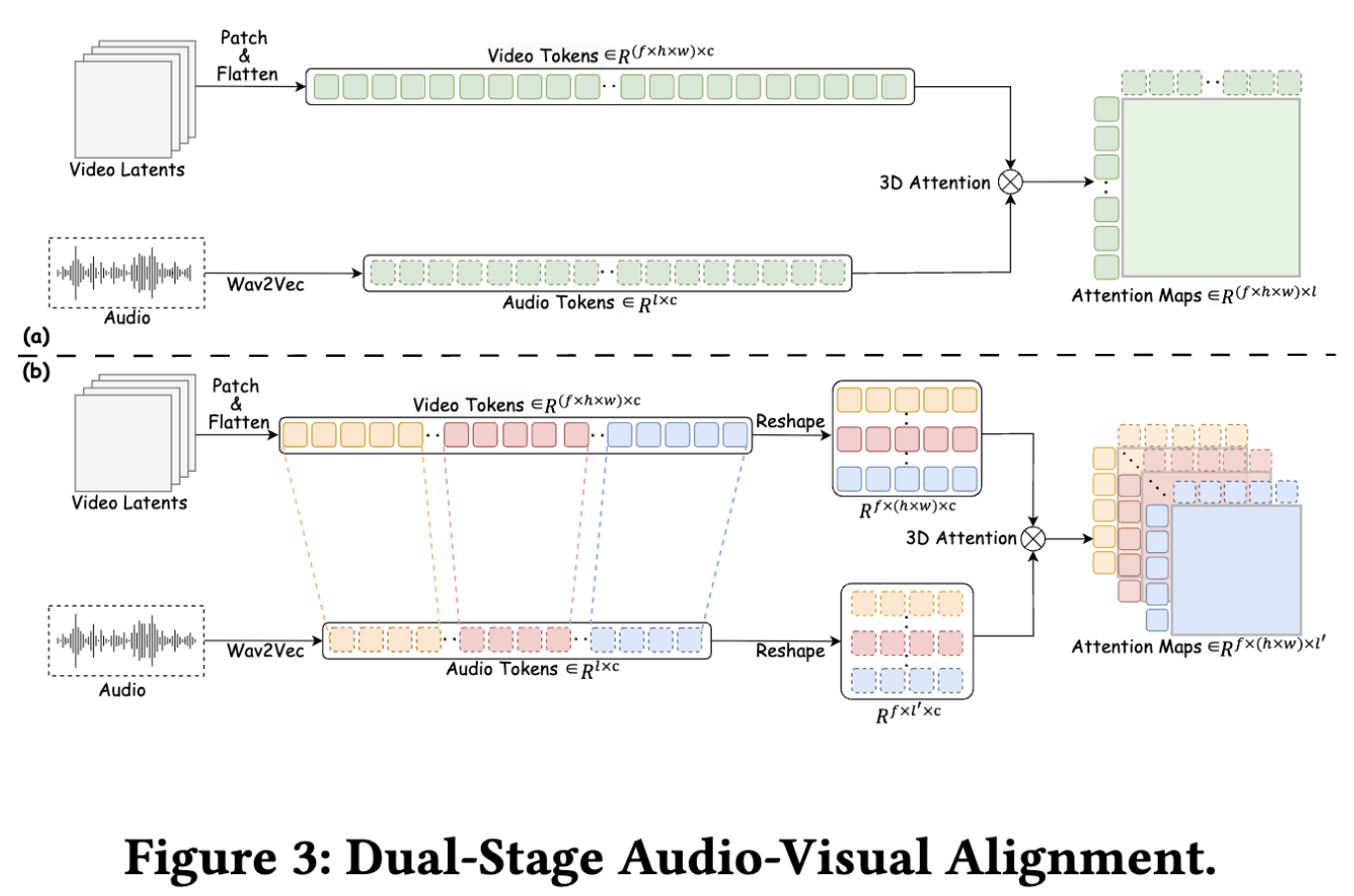
传统的说话头视频生成通常关注唇部运动的帧级对齐。然而,自然说话头生成不仅需要关注与音频直接相关的唇部运动,还需关注与音频特征弱相关的其他面部组件和身体部位的运动(如眉毛、眼睛和肩膀)。这些运动并不与音频严格时间对齐。为此,我们提出双阶段视听对齐方法:在第一训练阶段学习片段级与音频相关的视觉特征;在第二训练阶段专注于帧级与音频高度相关的视觉特征。
片段级训练。如图3(a)所示,第一阶段在片段级别计算全长视听token序列的3D全注意力相关性,建立全局视听依赖关系并实现整体特征融合。虽然该阶段能联合学习弱音频相关的非语言线索(如眉毛运动、肩膀动作)和强音频同步的唇部动态,但模型难以学习精确的唇部运动。这是因为唇部仅占据整个视场的小部分,而视频序列在每帧中都与音频高度相关。
帧级训练。如图3(b)所示,第二阶段通过帧精确的视听对齐专门优化唇部中心运动。我们将音频和视频按一一映射关系分段,将视频token重塑为形状,音频token重塑为形状,其中表示通道数。随后计算这些token间的3D全注意力,确保视觉特征仅关注对应的音频特征。
此外,为将注意力集中于唇部区域,我们利用MediaPipe[29]提取像素空间的精确唇部掩膜,并通过三线性插值投影到潜在空间,形成唇部聚焦约束掩膜。公式1中的帧级损失因此被重新加权为:

其中表示逐元素相乘。然而,仅依赖唇部特定约束可能导致过度正则化,抑制自然的头部运动和背景动态。为缓解此问题,我们采用概率来控制约束的应用强度,使模型能在聚焦唇部运动与保持整体运动自然性之间实现平衡。
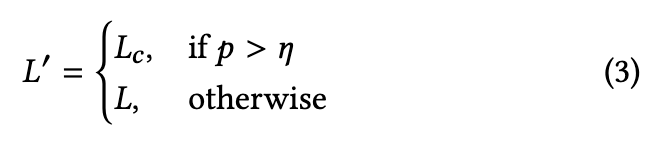
身份保持
虽然音频条件能有效建立声学输入与角色动作间的关联,但长时间视频序列和剧烈运动常导致合成结果中身份特征快速退化。现有方法通常采用从主干模型初始化的参考网络来保持身份特征,但这些方法存在两个关键缺陷:首先,参考网络处理全帧图像而非面部感兴趣区域,导致模型偏向生成静态背景和表现力受限的运动;其次,参考网络通常采用与主干模型相似的结构,造成特征表示能力高度冗余,并增加模型计算负载和复杂度。
为解决该问题,本文提出一种保持面部特征一致性的身份保持方法。首先从参考图像中裁剪面部区域,确保模型仅关注与身份相关的面部区域。随后利用ArcFace提取面部特征,并通过Q-Former进行对齐,最终得到ID嵌入。与音频条件类似,这些身份特征通过专用交叉注意力层与每个预训练DiT注意力块交互。形式上,每个DiT块的隐藏状态被重构为:
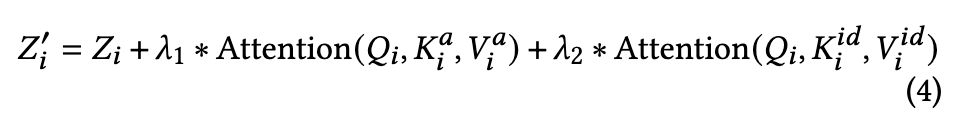
其中i表示注意力块的层数,是查询矩阵,和分别是音频和身份的键矩阵,和是注意力操作中的音频和身份值矩阵。超参数和控制着音频条件和身份条件的相对贡献。
运动强度调制网络
个体的说话风格在面部表情和身体运动幅度上表现出显著差异,这些差异无法仅通过音频和身份条件进行显式控制。特别是在自然说话头场景中,与拘束说话头场景相比,角色的表情和身体运动更加多样且动态。因此,引入了一个运动强度调制网络来调控这些动态特征。
本文利用Mediapipe提取面部关键点序列的方差,记为面部表情运动系数ω,并使用DWPose计算身体关节序列的方差,记为身体运动系数ω。ω和ω都被归一化到[0,1]的范围,分别代表面部表情和身体运动的强度。
如下图2所示,运动强度调制网络由MLP层、ResNet层和平均池化层组成。得到的运动嵌入会与时间步相加。在推理阶段,允许用户自定义输入系数ω_l和ω_b来控制面部和身体运动的幅度。
实验
实验设置
实现细节: 本文采用Wan2.1-I2V-14B作为基础模型。在片段级训练阶段,训练约80,000步;在帧级训练阶段,训练约20,000步。在所有训练阶段,身份网络和运动网络都参与端到端训练。使用Flow Matching来训练模型,整个训练在64块A100 GPU上进行。学习率设置为1e-4。设为1,设为0.5,η设为0.2。为增强视频生成的多样性,参考图像、引导音频和提示文本各自以0.1的概率被独立丢弃。在推理阶段,采用30个采样步数,运动强度参数ω和ω设为中性值0.5,音频的CFG设为4.5。
数据集:
本文使用的训练数据集由三部分组成:Hallo3、Celebv-HQ以及从互联网收集的数据。本文使用InsightFace排除面部置信度得分低于0.9的视频,并移除语音和嘴部运动不同步的片段。这一筛选过程最终得到约150,000个片段。本文使用HDTF中的50个片段来评估拘束说话头生成。此外,还在包含80个不同个体的自然说话数据集上评估我们的模型。
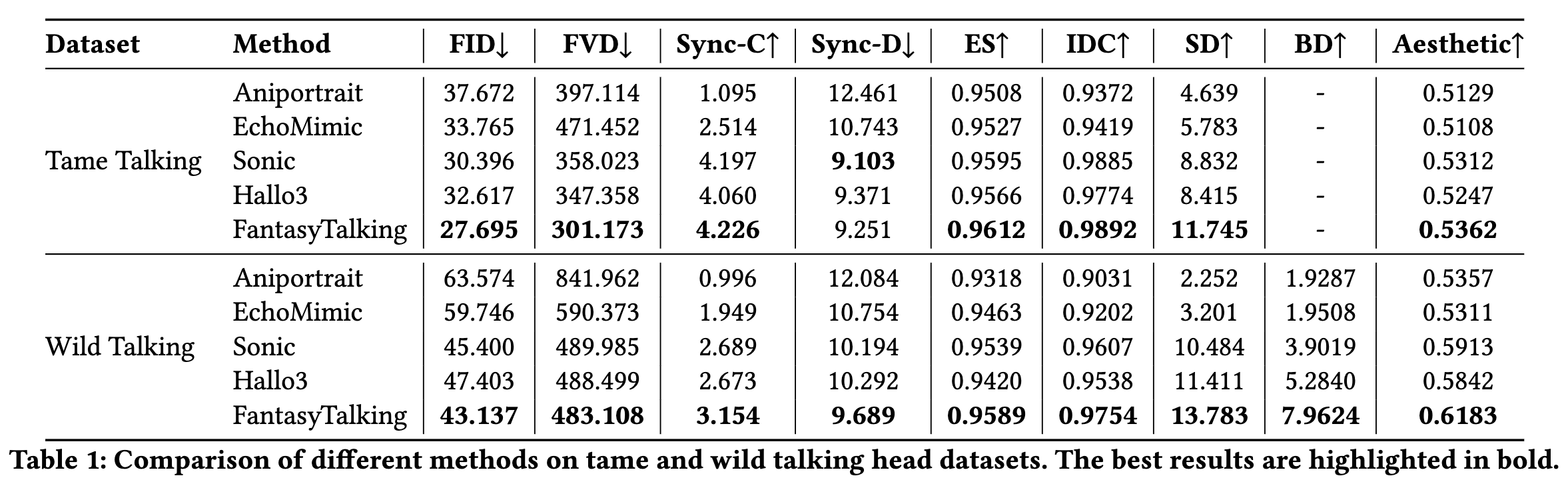
评估指标与基线: 本文采用八个指标进行评估。Frechet Inception Distance(FID)和Fréchet Video Distance(FVD)用于评估生成数据的质量。Sync-C和Sync-D用于测量音频和唇部运动之间的同步性。Expression Similarity(ES)方法提取视频帧之间的面部特征,并通过计算这些特征之间的相似度来评估身份特征的保持情况。Identity Consistency(IDC)通过提取面部区域并计算帧间的DINO相似度度量来衡量角色身份特征的一致性。本文使用SAM将帧分割为前景和背景,并分别测量前景和背景的光流得分来评估主体动态(SD)和背景动态(BD)。使用LAION审美预测器评估视频的艺术和审美价值。
本文选择了几种最先进的方法来评估本文的方法,这些方法都有公开可用的代码或实现。这些方法包括基于UNet的Aniportrait、EchoMimic和Sonic,以及基于DiT的Hallo3。为公平比较,本文的方法在推理时将提示设为空。
结果与分析
拘束数据集对比实验: 拘束说话头数据集的背景和角色姿态变化有限,主要关注唇部同步和面部表情准确性。下表1和图4展示了评估结果。本方法在FID、FVD、IDC、ES和美学评分上均取得最优成绩,这主要归功于模型能生成最具表现力的自然面部表情,从而产生最高质量的视觉效果。在Sync-C和Sync-D指标上,本方法取得第一或第二的成绩,表明DAVA方法使模型能准确学习音频同步特征。
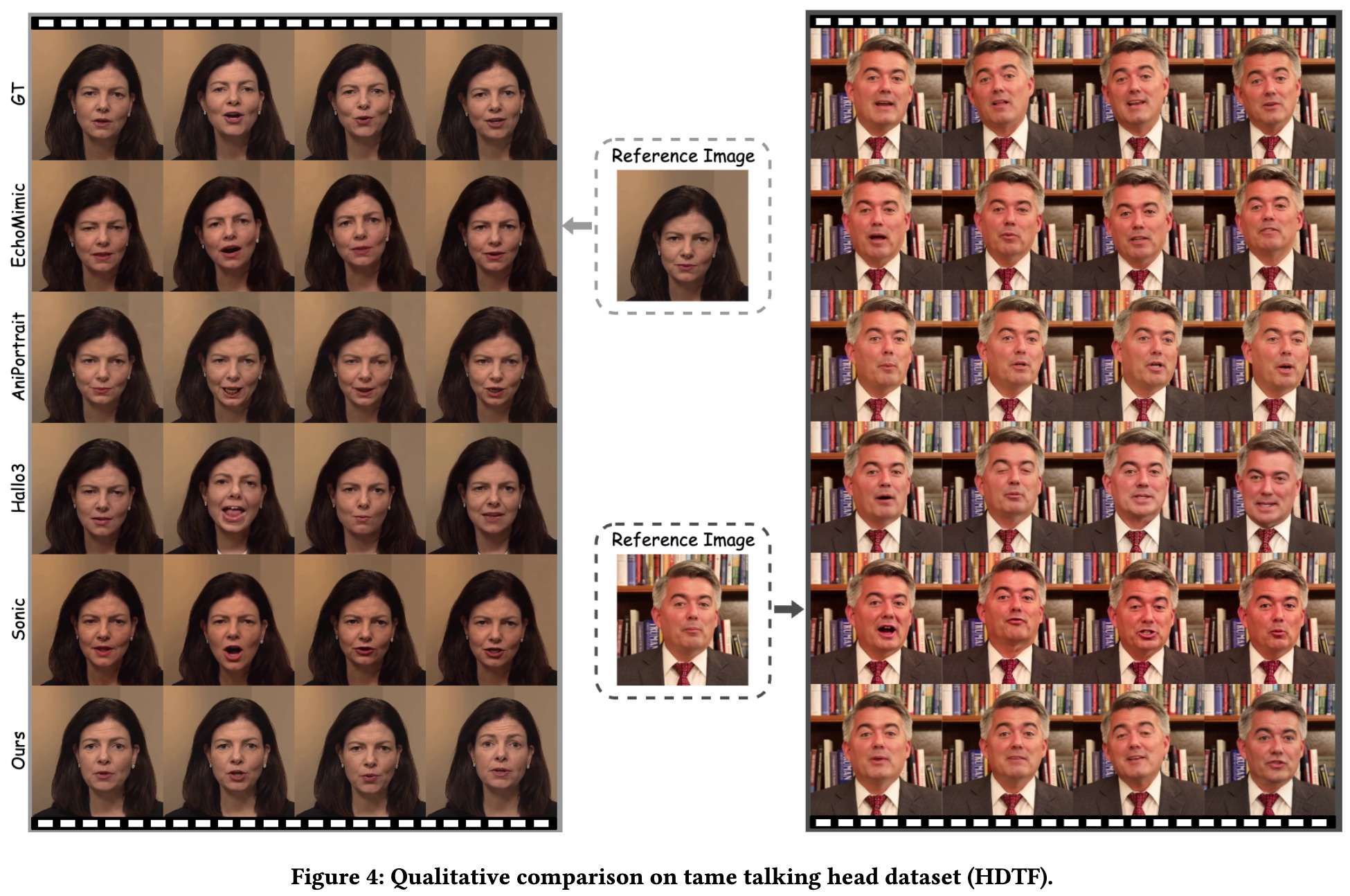
自然数据集对比实验: 上表1和下图5展示了包含显著前景/背景变化的自然说话头数据集评估结果。现有方法过度依赖参考图像,限制了生成的面部表情、头部运动和背景动态的自然度。相比之下,本方法在所有指标上均取得最优结果,其输出具有更自然的前后景变化、更好的唇部同步和更高的视频质量。这主要得益于:1)DAVA方法强化了音频理解能力;2)面向面部特征的身份保持方法。这些技术使模型在保持角色身份特征的同时,能生成更复杂的自然头部和背景运动。

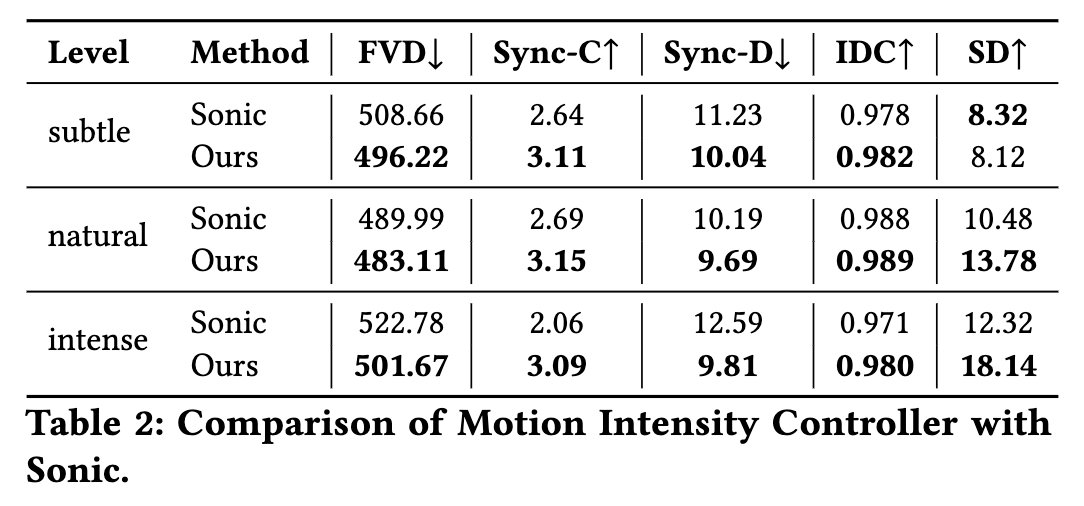
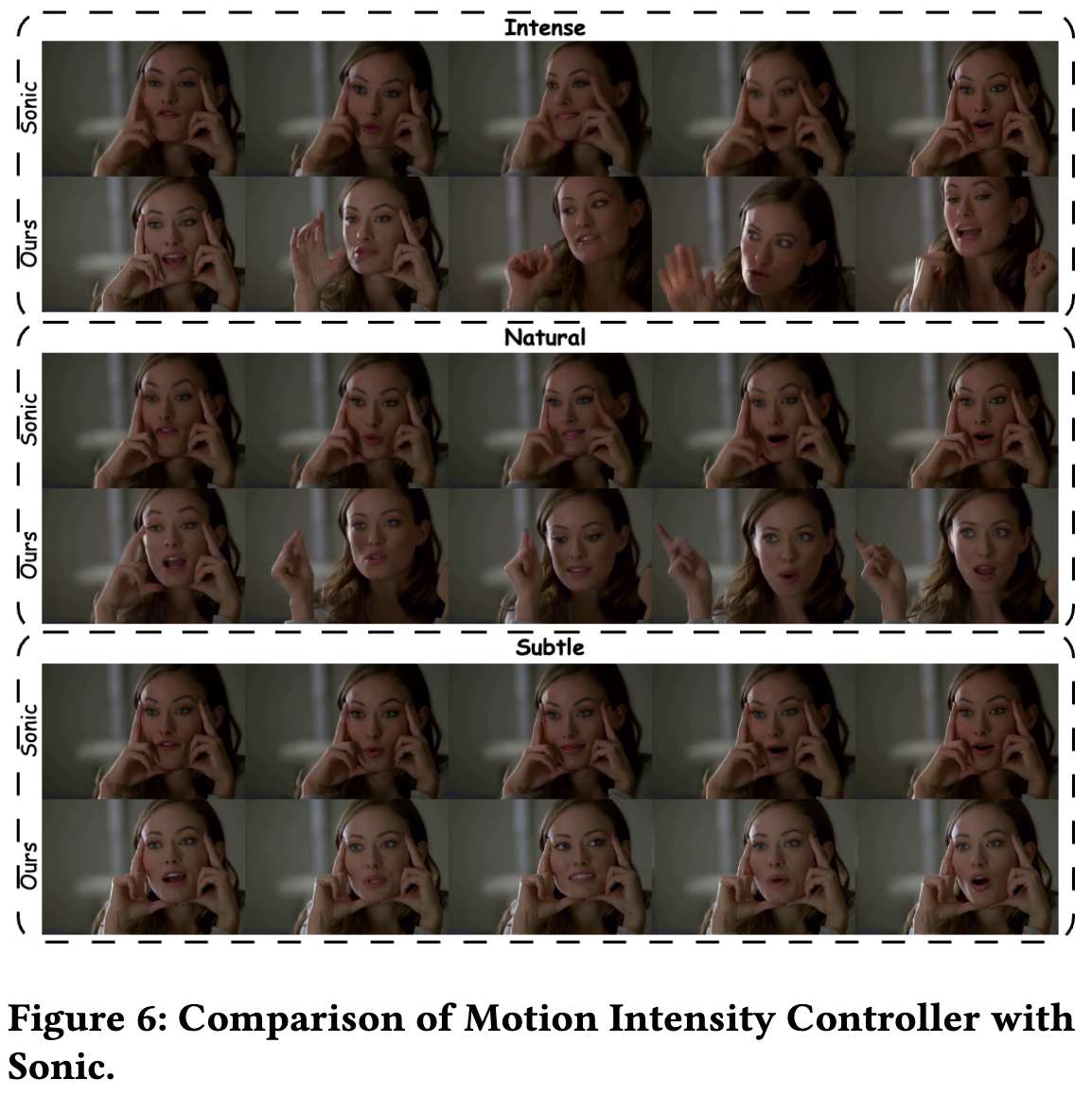
运动强度控制器与Sonic对比: Sonic通过参数β提供类似的运动强度控制功能。我们将运动强度分为三个等级进行对比实验:轻微(βωω)、自然(βωω)和剧烈(βωω)。下表2和图6显示,在自然和轻微强度下,两种方法都能良好控制运动强度并保持唇部同步;但在剧烈运动场景中,本方法因考虑全身运动(而Sonic仅控制头部),展现出更完整的人体运动表征能力。
可视化效果与Hallo3对比: 下图7展示了与基于DiT的Hallo3方法的可视化对比。Hallo3的输出存在明显缺陷:上图出现面部/唇部畸变和虚假背景运动,下图则呈现僵硬的头部运动。相比之下,本方法生成的表情、头部运动和背景动态都更加真实自然,这得益于:1)面部知识学习增强身份特征;2)DAVA方法强化唇部同步学习。

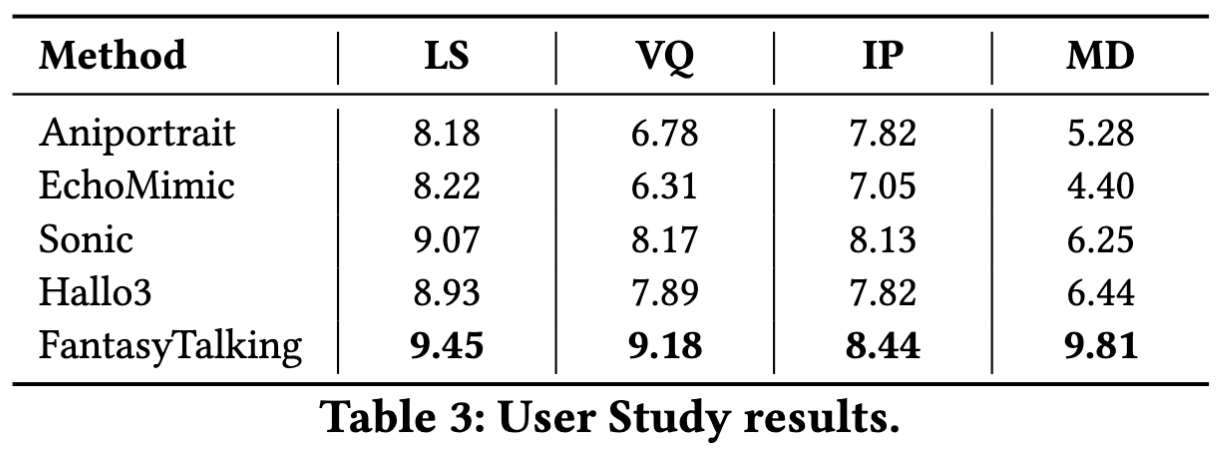
用户调研: 本文在自然说话头数据集上进行了包含24名参与者的主观评估,从唇部同步(LS)、视频质量(VQ)、身份保持(IP)和运动多样性(MD)四个维度进行0-10分评分。如下表3所示,FantasyTalking在所有评估维度上均超越基线方法,尤其在运动多样性方面提升显著。这验证了本方法在生成真实多样说话头动画的同时,能保持身份一致性和视觉保真度的优势。
消融实验与讨论
DAVA方法消融实验: 为验证DAVA方法的有效性,我们分别测试了仅使用片段级对齐和仅使用帧级对齐的训练方案。下表4和图8显示:仅采用片段级对齐会导致Sync-C指标显著下降,表明其无法学习精确的唇音对应关系;而仅使用帧级对齐虽具备强唇同步能力,但会限制表情和主体运动的动态性。相比之下,DAVA方法通过结合两级对齐的优势,在实现精确唇音同步的同时,增强了角色动画和背景动态的生动性。
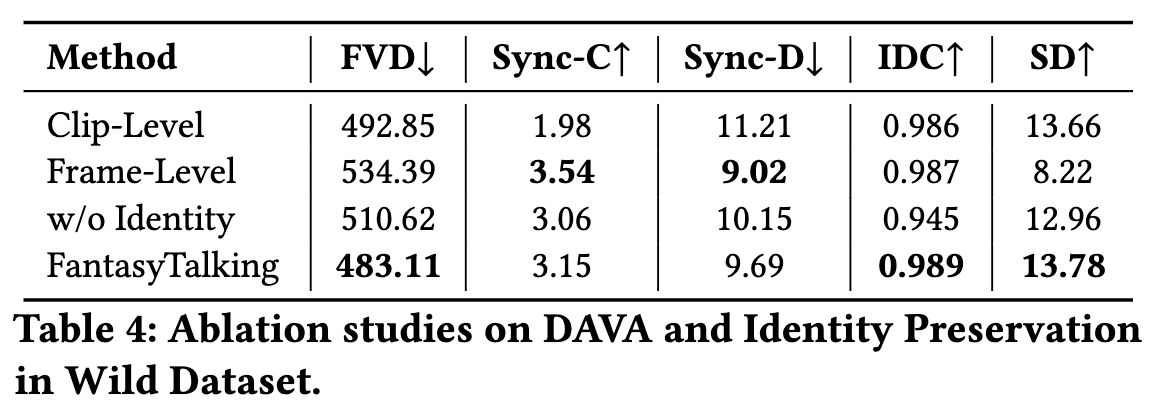

身份保持模块消融实验: 上表4结果表明身份保持模块的重要性。移除该模块会导致IDC指标显著降低,表明模型保持角色身份特征的能力大幅减弱。如下图9所示,缺乏身份保持会导致面部特征出现伪影和畸变。我们提出的面部聚焦身份保持方法,在保持唇部同步和丰富运动能力的同时,显著提升了身份特征的一致性,从而改善视频整体质量。

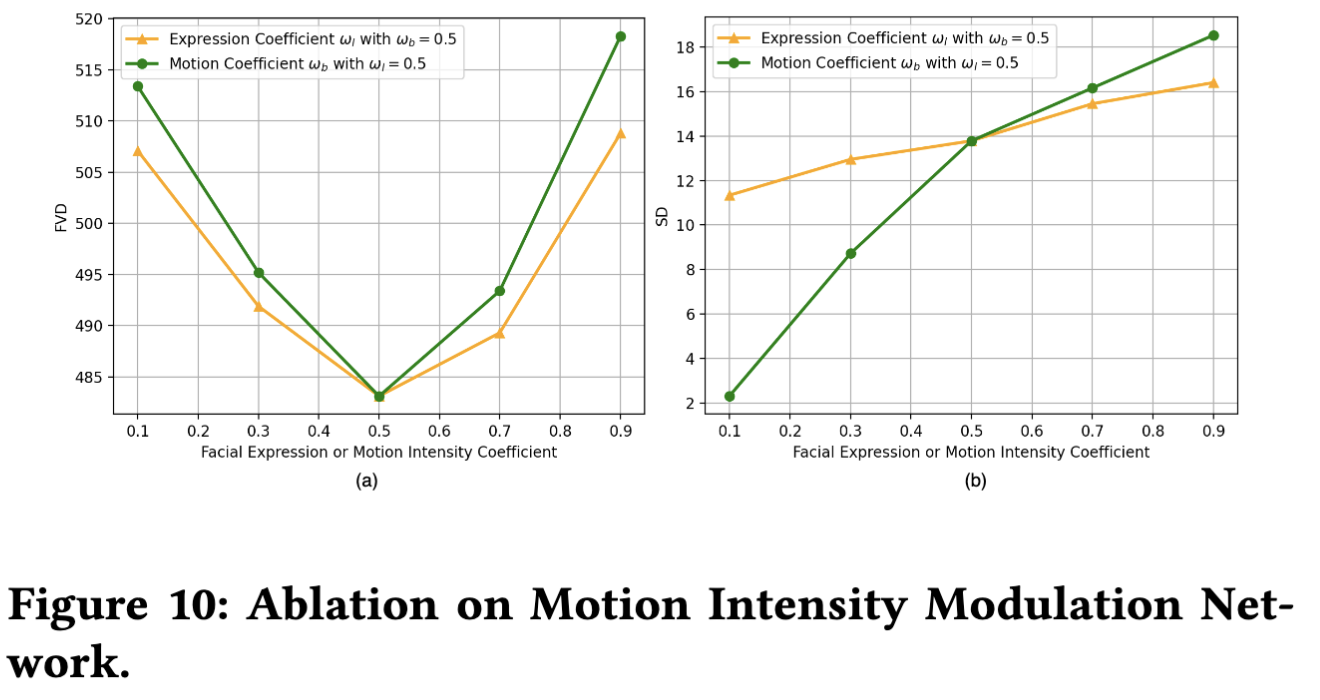
运动强度调制网络消融实验: 下图10展示了调整运动强度系数(ωω)对FVD和SD指标的量化影响。当固定其中一个参数为中性值0.5时:1) 图10(a)显示自然运动强度(ωω)取得最佳FVD分数,表明过高或过低的运动强度都会导致视觉效果偏离真实场景;2) 图10(b)显示随着ω或ω增大,主体动态评分显著提升,验证了运动控制机制的有效性。
局限性与未来工作: 尽管本方法在自然说话头视频生成方面取得显著进展,但扩散模型推理所需的迭代采样过程导致整体运行速度较慢。研究加速策略将有助于其在直播、实时交互等场景的应用。此外,基于音频驱动说话头生成技术探索具有实时反馈的交互式肖像对话解决方案,可拓展数字人avatar 在现实场景中的应用广度。
结论
本文提出了FantasyTalking,一种新颖的音频驱动肖像动画技术。通过采用双阶段视听对齐训练流程,本文的方法有效捕捉了音频信号与唇部运动、面部表情以及身体动作之间的关联关系。为增强生成视频中的身份一致性,提出了一种面部聚焦的身份保持方法以精准保留面部特征。此外,通过运动网络控制表情和身体运动的幅度,确保生成动画的自然性与多样性。定性与定量实验表明,FantasyTalking在视频质量、运动多样性和身份一致性等关键指标上均优于现有SOTA方法。
参考文献
[1] FantasyTalking: Realistic Talking Portrait Generation via Coherent Motion Synthesis

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









