






一、梯度下降法
重申,机器学习三要素是:模型,学习准则,优化算法。这里讨论一下梯度下降法。
通常为了充分利用凸优化中的一些高效成熟的优化方法,像:共轭梯度、拟牛顿法等,所以呢很多的机器学习算法倾向于选择合适的模型和损失函数来构造一个凸函数作为优化的目标。但是呢,也有一些模型(例如神经网络)的优化目标是非凸的,以至于只能找到其局部最优解。
机器学习中,常用的优化算法就是梯度下降法,首先初始化参数
θ
0
\theta_0
θ0,然后按照下列公式进行参数的更新:
θ
t
+
1
=
θ
t
−
α
∂
R
(
θ
)
∂
θ
(式1)
\theta_{t+1}=\theta_t-\alpha\cfrac{\partial\mathcal{R(\theta)}}{\partial\theta}\tag{式1}
θt+1=θt−α∂θ∂R(θ)(式1)
=
θ
t
−
α
1
N
∑
n
=
1
N
∂
L
(
y
(
n
)
,
f
(
x
(
n
)
;
θ
)
)
∂
θ
(式2)
=\theta_t-\alpha\cfrac{1}{N}\sum_{n=1}^{N}\cfrac{\partial\mathfrak{L}(y^{(n)},f(x^{(n)};\theta))}{\partial\theta} \tag{式2}
=θt−αN1n=1∑N∂θ∂L(y(n),f(x(n);θ))(式2)
注:
θ
t
\theta_t
θt为第
t
t
t次迭代时的参数值,
α
\alpha
α为搜索步长,又叫做学习率(Learning Rate)。
(1)预防过拟合
对于使用梯度下降的优化算法,为了防止过拟合现象的发生,不仅可以使用增加正则化项,还可以通过提前停止来实现。
在梯度下降训练的过程中,由于过拟合的原因,在训练样本上收敛的参数,并不一定在测试集上最优. 因此,除了训练集和测试集之外,有时也会使用一个验证集(Validation Set)来进行模型选择,测试模型在验证集上是否最优.
(2)提前停止
在每次迭代时,把新的到的模型
f
(
x
;
θ
)
f(\boldsymbol{x};\theta)
f(x;θ)在验证集上进行测试,然后计算错误率。如果在验证集上的错误率不再下降,就停止迭代。这种策略就叫做提前停止(Early Stop)。如果没有验证集,可以直接在训练集上划分一个小比例的数据子集作为验证集。
图示如下:

二、批量梯度下降
优化目标:
J
(
θ
)
=
1
2
N
∑
i
=
1
m
(
y
i
−
f
θ
(
x
i
)
)
2
min
θ
J
(
θ
)
(式3)
J(\theta)=\cfrac{1}{2N}\sum_{i=1}^{m}(y_i-f_{\theta}(x_i))^2\qquad{\min\limits_{\theta}J(\theta)}\tag{式3}
J(θ)=2N1i=1∑m(yi−fθ(xi))2θminJ(θ)(式3)
优化过程:
根据整个批量数据的梯度更新参数,
θ
n
e
w
⟸
θ
o
l
d
−
η
∂
J
(
θ
)
∂
θ
\theta_{new}\Longleftarrow\theta_{old}-\eta\cfrac{\partial{J(\theta)}}{\partial{\theta}}
θnew⟸θold−η∂θ∂J(θ)
∂
J
(
θ
)
∂
θ
=
−
1
N
∑
i
=
1
N
(
(
y
i
−
f
θ
(
x
i
)
)
∂
f
θ
(
x
i
)
∂
θ
)
(式4)
\cfrac{\partial{J(\theta)}}{\partial{\theta}}=-\cfrac{1}{N}\sum_{i=1}^{N}((y_i-f_{\theta(x_i)})\cfrac{\partial{f_{\theta}(x_i)}}{\partial{\theta}})\tag{式4}
∂θ∂J(θ)=−N1i=1∑N((yi−fθ(xi))∂θ∂fθ(xi))(式4)
=
−
1
N
∑
i
=
1
N
(
y
i
−
f
θ
(
x
i
)
)
x
i
(式5)
=-\cfrac{1}{N}\sum_{i=1}^{N}(y_i-f_{\theta}(x_i))x_i\tag{式5}
=−N1i=1∑N(yi−fθ(xi))xi(式5)
θ
n
e
w
=
θ
o
l
d
+
η
1
N
∑
i
=
1
N
(
y
i
−
f
θ
(
x
i
)
)
x
i
(式6)
\theta_{new}=\theta_{old}+\eta\cfrac{1}{N}\sum_{i=1}^{N}(y_i-f_{\theta}(x_i))x_i\tag{式6}
θnew=θold+ηN1i=1∑N(yi−fθ(xi))xi(式6)
注:批量梯度下降法(Batch Gradient Descent,BGD)中,目标函数是整个训练集上的风险函数,批量梯度下降法在每次迭代时要计算在每个样本上损失函数的梯度并求和。
当训练集中的样本数量N很大时,空间复杂度比较高,每次迭代的计算开销也很大。
三、随机梯度下降
为了减少每次迭代的计算复杂度,在每次迭代时只采集一个样本,计算这个样本损失函数的梯度并进行参数更新。这就是随机梯度下降法(Stochastic Gradient Descent,SGD).当经过最够多次数的迭代时,随机梯度下降也可以收敛到局部最优解。
(1)算法流程

(2)优化目标:
J
(
i
)
(
θ
)
=
1
2
∑
i
=
1
m
(
y
i
−
f
θ
(
x
i
)
)
2
min
θ
J
(
i
)
(
θ
)
(式7)
J^{(i)}(\theta)=\cfrac{1}{2}\sum_{i=1}^{m}(y_i-f_{\theta}(x_i))^2\qquad{\min\limits_{\theta}J^{(i)}(\theta)}\tag{式7}
J(i)(θ)=21i=1∑m(yi−fθ(xi))2θminJ(i)(θ)(式7)
优化过程:
根据整个批量数据的梯度更新参数,
θ
n
e
w
⟸
θ
o
l
d
−
η
∂
J
(
i
)
(
θ
)
∂
θ
\theta_{new}\Longleftarrow\theta_{old}-\eta\cfrac{\partial{J^{(i)}(\theta)}}{\partial{\theta}}
θnew⟸θold−η∂θ∂J(i)(θ)
∂
J
(
i
)
(
θ
)
∂
θ
=
−
(
(
y
i
−
f
θ
(
x
i
)
)
∂
f
θ
(
x
i
)
∂
θ
)
(式8)
\cfrac{\partial{J^{(i)}(\theta)}}{\partial{\theta}}=-((y_i-f_{\theta(x_i)})\cfrac{\partial{f_{\theta}(x_i)}}{\partial{\theta}})\tag{式8}
∂θ∂J(i)(θ)=−((yi−fθ(xi))∂θ∂fθ(xi))(式8)
=
−
(
y
i
−
f
θ
(
x
i
)
)
x
i
(式9)
=-(y_i-f_{\theta}(x_i))x_i\tag{式9}
=−(yi−fθ(xi))xi(式9)
θ
n
e
w
=
θ
o
l
d
+
η
(
y
i
−
f
θ
(
x
i
)
)
x
i
(式10)
\theta_{new}=\theta_{old}+\eta(y_i-f_{\theta}(x_i))x_i\tag{式10}
θnew=θold+η(yi−fθ(xi))xi(式10)
对比批量梯度下降:
随机梯度下降可以实现更快的更新参数,但是学习中会有不确定性或震荡现象。
四、小批量梯度下降
(1)思想:
批量梯度下降和随机梯度下降的结合。
(2)训练步骤:
- 将整个训练集分成
k
k
k个小批量(mini-batches)
{ 1 , 2 , 3 , ⋯ , k } \{1,2,3,\cdots,k\} {1,2,3,⋯,k} - 对于每一个小批量
k
k
k,做一步批量下降来降低
J ( k ) ( θ ) = 1 2 N k ∑ i = 1 N k ( y i − f θ ( x i ) ) 2 J^{(k)}(\theta)=\cfrac{1}{2N_k}\sum_{i=1}^{N_k}(y_i-f_{\theta}(x_i))^2 J(k)(θ)=2Nk1i=1∑Nk(yi−fθ(xi))2 - 对于每一个小批量,更新参数 θ n e w = θ o l d − η ∂ J ( k ) ( θ ) ∂ θ \theta_{new}=\theta_{old}-\eta\cfrac{\partial{J^{(k)}(\theta)}}{\partial{\theta}} θnew=θold−η∂θ∂J(k)(θ)
优点:
结合了批量梯度下降和随机梯度下降的优点:
∗
批
量
梯
度
下
降
的
优
秀
的
稳
定
性
\qquad{* 批量梯度下降的优秀的稳定性}
∗批量梯度下降的优秀的稳定性
∗
随
机
梯
度
下
降
的
快
速
更
新
\qquad{* 随机梯度下降的快速更新}
∗随机梯度下降的快速更新
小批量梯度下降很容易做并行化
∗
将
每
个
小
批
量
数
据
进
一
步
切
分
,
每
个
线
程
分
别
计
算
梯
度
,
最
后
再
加
和
这
些
梯
度
\qquad{* 将每个小批量数据进一步切分,每个线程分别计算梯度,最后再加和这些梯度}
∗将每个小批量数据进一步切分,每个线程分别计算梯度,最后再加和这些梯度
图示如下:
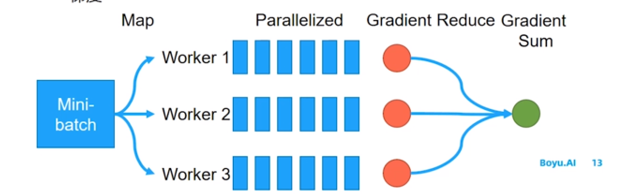
在实际应用中,小批量随机梯度下降法有收敛快、计算开销小的优点,因此逐渐成为大规模的机器学习中的主要优化算法。
好了,至此就说完了梯度下降的基本原理。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









