






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

变分自编码器(VAE)是当下最流行的生成模型系列之一,它可以被用来刻画数据的分布。经典的期望最大化(EM)算法旨在学习具有隐变量的模型。本质上,VAE 和 EM 都会迭代式地优化证据下界(ELBO),从而最大化观测数据的似然。本文旨在为 VAE 和 EM 提供一种统一的视角,让具有机器学习应用经验但缺乏统计学背景的读者最快地理解 EM 和 VAE。
论文链接(已收录于AI open):https://www.aminer.cn/pub/6180f4ee6750f8536d09ba5b
1
引言
我们往往假设采样自某种底层分布的数据是独立同分布的。如果数据分布 已知,我们可以利用它生成新的数据。实际上,我们的主要目标找到一个参数为
已知,我们可以利用它生成新的数据。实际上,我们的主要目标找到一个参数为 的分布
的分布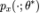 能够最好地拟合
能够最好地拟合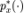 。最大似然估计(MLE)是最自然的衡量拟合性能标准,它能够最大化观测到的数据被生成的概率。
。最大似然估计(MLE)是最自然的衡量拟合性能标准,它能够最大化观测到的数据被生成的概率。
对数据的了解使我们可以采用具有隐变量 z 的模型来近似数据分布,此时只有联合分布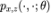 被显式定义。我们感兴趣的边缘似然
被显式定义。我们感兴趣的边缘似然 包含在 z 上的积分。图像等高维数据需要使用复杂的基于深度学习的模型,此时积分是没有解析形式,因此难以计算其积分。这正是变分推断(VI)方法(例如,VAE)旨在解决的问题。
包含在 z 上的积分。图像等高维数据需要使用复杂的基于深度学习的模型,此时积分是没有解析形式,因此难以计算其积分。这正是变分推断(VI)方法(例如,VAE)旨在解决的问题。
ELBO 是边缘似然函数对数的下界 ,我们通过引入一个额外的分布
,我们通过引入一个额外的分布 来构造 ELBO。
来构造 ELBO。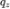 与后验概率
与后验概率 越接近,则证据下界越严格。
越接近,则证据下界越严格。
EM 算法和 VAE 都会迭代式地优化 ELBO。具体而言,它们会交替地从 和 θ 上优化 ELBO,直至收敛。区别之处在于,EM 在每一步中都会进行完美的优化,而为更加复杂的模型(例如,神经网络)设计的 VAE 通过某些近似方法执行一个梯度步。在本文中,我们将详细介绍这两种方法之间的异同之处。
和 θ 上优化 ELBO,直至收敛。区别之处在于,EM 在每一步中都会进行完美的优化,而为更加复杂的模型(例如,神经网络)设计的 VAE 通过某些近似方法执行一个梯度步。在本文中,我们将详细介绍这两种方法之间的异同之处。
2
最大似然估计
我们对满足分布的数据建模,其中 θ 是模型的参数,x 为观测到的变量,z 为隐变量。对于独立同分布的观测数据 ,我们要计算参数的最大似然估计:
,我们要计算参数的最大似然估计:

其中, 为 X 的边缘似然(即「证据」)。通常而言,我们计算「证据」的对数来处理独立同分布的数据:
为 X 的边缘似然(即「证据」)。通常而言,我们计算「证据」的对数来处理独立同分布的数据:

这样一来,完整的对数似然可以被分解为每个数据点的对数似然之和。在本文接下来的部分中,我们在分析中只考虑一个数据点的对数似然 ,然而仍然会在算法描述中考虑多个数据点。
,然而仍然会在算法描述中考虑多个数据点。
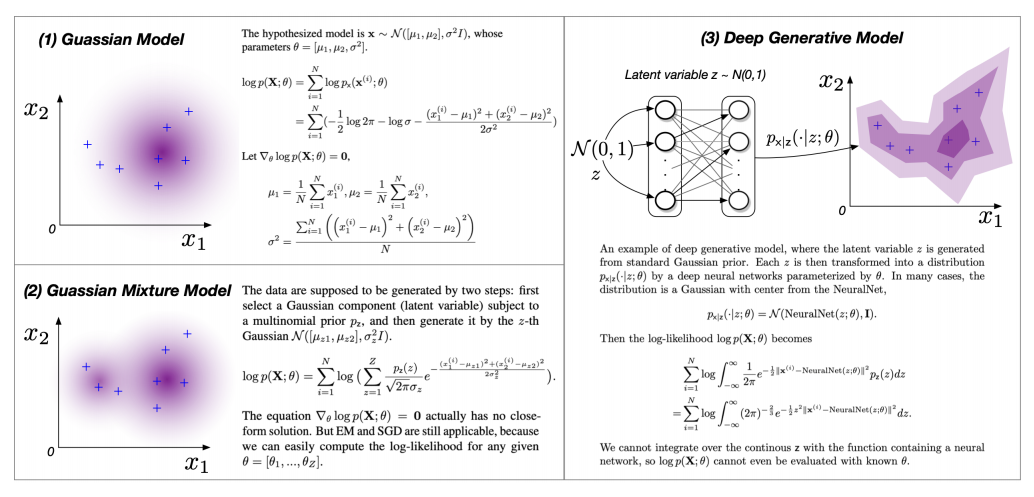
图 1:基于高斯函数的三种不同 MLE 复杂度的模型
实际上, MLE 的难度会因模型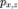 的复杂度有很大的差别。在这里,我们模型的复杂度由简单到复杂分为三个等级:
的复杂度有很大的差别。在这里,我们模型的复杂度由简单到复杂分为三个等级:
(1)等式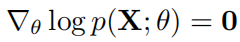 具有封闭解
具有封闭解 。在这种情况下,我们计算每个驻点
。在这种情况下,我们计算每个驻点 上的似然
上的似然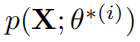 ,并求最大值。然而,当隐变量 z 存在时,
,并求最大值。然而,当隐变量 z 存在时, 包含对 z 的积分,通常使上述等式没有封闭解。
包含对 z 的积分,通常使上述等式没有封闭解。
(2)给定 ,可以估计边缘似然
,可以估计边缘似然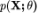 ,因此
,因此 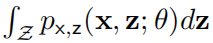 也易于计算。这种情况下,利用自动微分工具(例如,Tensorflow、Ptroech)运行梯度法
也易于计算。这种情况下,利用自动微分工具(例如,Tensorflow、Ptroech)运行梯度法
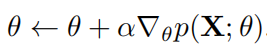
是最流行、最直接的方法。迭代地最大化 ELBO 的 EM 算法主要就是针对这个复杂度等级中的各种场景设计的,EM 算法通常是鲁棒的,可以很快收敛。
(3)边缘似然 无法被估计,因此难以计算
无法被估计,因此难以计算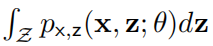 。在深度学习时代,这种情况经常发生,此时我们通过神经网络对
。在深度学习时代,这种情况经常发生,此时我们通过神经网络对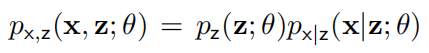 和
和 建模。VAE 主要针对的就是此类问题。
建模。VAE 主要针对的就是此类问题。
3
证据下界(ELBO)
ELBO 是本文最核心的概念之一,它是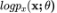 的下界。我们通过引入一个额外的隐变量空间 Z 上的的分布来构建 ELBO。可以是任意选择的分布,但它会议影响 ELBO 的严格程度。
的下界。我们通过引入一个额外的隐变量空间 Z 上的的分布来构建 ELBO。可以是任意选择的分布,但它会议影响 ELBO 的严格程度。
令观测数据点为 x,我们可以通过分解 推导出 ELBO:
推导出 ELBO:
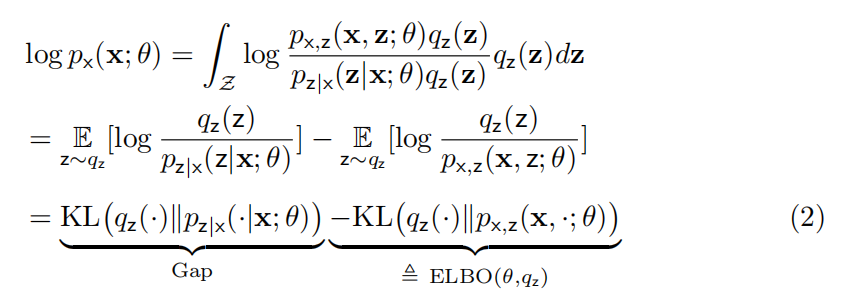
其中,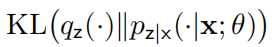 衡量了和隐变量的后验概率
衡量了和隐变量的后验概率 之间的相似度。
之间的相似度。
此外,我们还可以基于 Jensen 不等式推导出 ELBO:
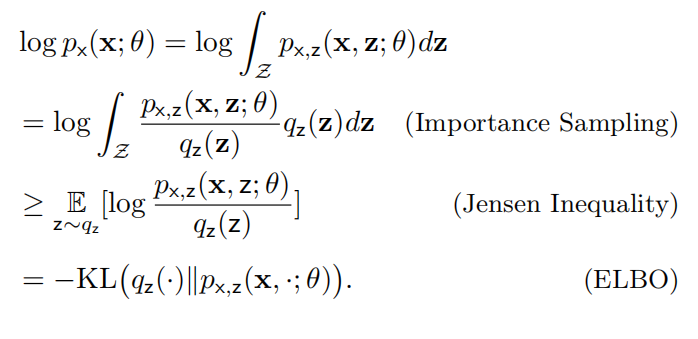
请注意,ELBO 可以被进一步分解为下面的形式:
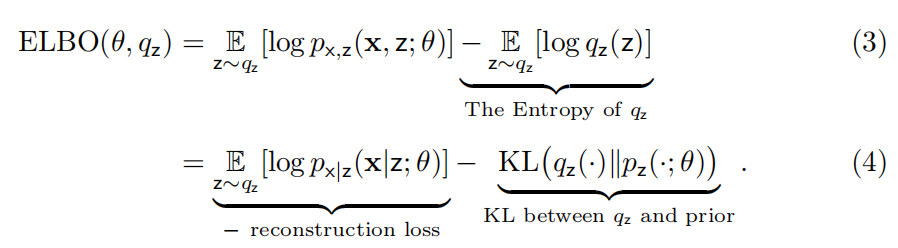
ELBO 为我们提供了一种找到最大似然,或近似最大似然的新方法:
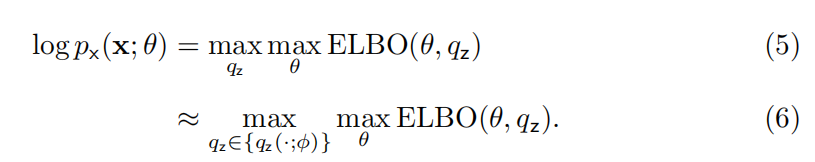
公式(5)解释了 ELBO 如何最大化似然。公式(6)说明,我们可以从简单的分布族中挑选,从而近似似然,同时保证了 ELBO 易于计算。
4
期望最大算法
EM 算法已经被成功地用来学习许多著名的模型(例如,高斯混合算法——GMM 和隐马尔科夫模型 HMM),它被视为 20 世纪最重要的算法之一。EM 算法是针对 的坐标上升算法。
的坐标上升算法。
(E 步)首先,我们固定 θ,在上优化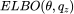 。由公式(2)我们可以得出:
。由公式(2)我们可以得出:
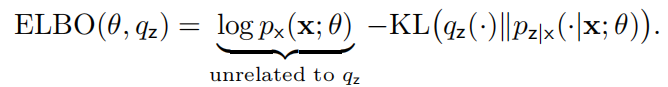
对于给定的 θ,我们将令 ELBO 最大化的 定义为:
定义为:
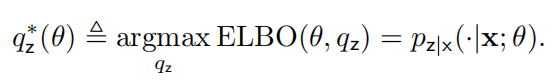
(M 步)接下来,我们固定 ,在 θ 上优化 ELBO。假设当前的旧参数为
,在 θ 上优化 ELBO。假设当前的旧参数为 ,我们将
,我们将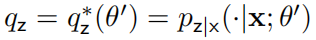 代入
代入 ,目标是找到:
,目标是找到:

我们可以将公式(3)分解为:

其中,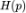 为分布 p 的熵。我们定义:
为分布 p 的熵。我们定义:
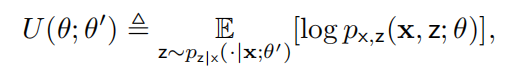
则最优的新参数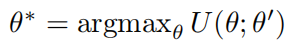
以上的 E 步和 M 步会迭代重复直至收敛。整体的算法流程如下:

相较于梯度法,EM 算法的优点在于其单调收敛性、低计算开销,它在一些重要的模型上有出色的性能。EM 算法天然地满足概率约束。然而,EM 算法要求后验概率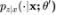 易于计算,且容易计算
易于计算,且容易计算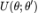 最大值。然而,上述要求对于复杂模型是十分苛刻的。
最大值。然而,上述要求对于复杂模型是十分苛刻的。
5
变分 EM、MCEM、 Generalized EM
若
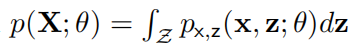 难以计算,则无法估计后验概率
难以计算,则无法估计后验概率 。变分 EM 是一种替代方案,它通过一个简单的分布替换后验概率。例如,在平均场方法中,每个维度上的分量都是独立的,即:
。变分 EM 是一种替代方案,它通过一个简单的分布替换后验概率。例如,在平均场方法中,每个维度上的分量都是独立的,即:
若
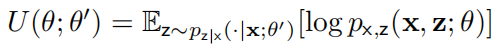 无法被简化为解析形式,我们可以进行蒙特卡洛近似,即 MCEM 算法:
无法被简化为解析形式,我们可以进行蒙特卡洛近似,即 MCEM 算法:
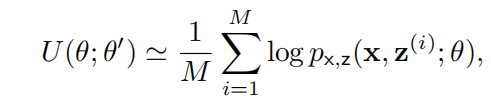
其中,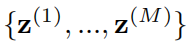 采样自
采样自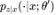
当我们无法直接得到
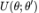 的最大值时,Generalized EM 会转而执行一个能够提升 ELBO 的步骤(例如,梯度步)。
的最大值时,Generalized EM 会转而执行一个能够提升 ELBO 的步骤(例如,梯度步)。
6
变分自编码器
假设某个模型满足以下要求:
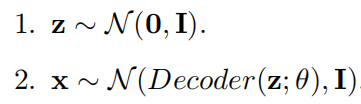
其中,Decoder 编码器为神经网络。那么估计这种模型的参数是图 1 中最困难的情况。由于神经网络的存在,我们会遇到第五章中的第三种情况。如果我们将变分 EM、MCEM、Generalized EM 结合起来,就可以得到 VAE 模型。实际上,VAE 可以看做对 EM 算法的扩展。
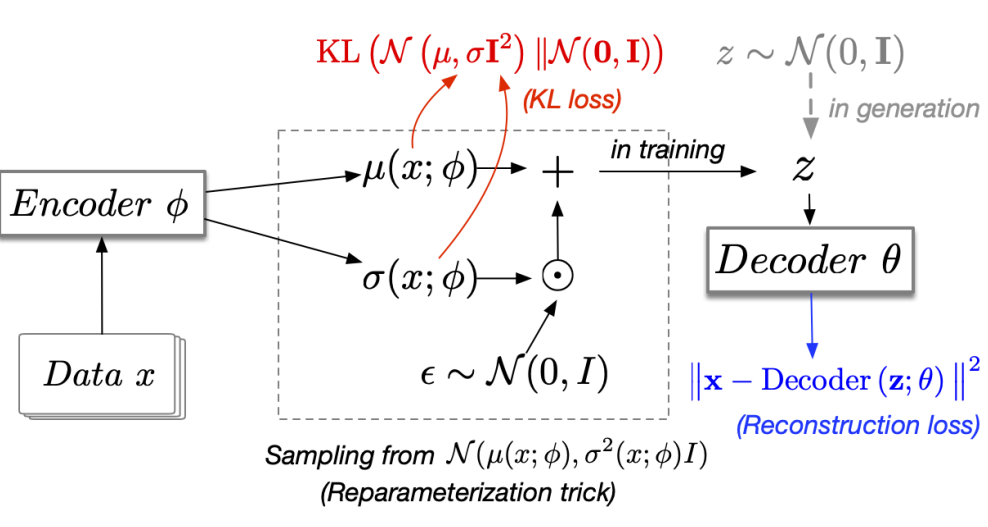
图 2:变分自编码器
在训练编码器和解码器的过程中,我们从后验概率 中采样隐变量 z。然而,在生成时,我们从先验概率
中采样隐变量 z。然而,在生成时,我们从先验概率 中采样隐变量 z。
中采样隐变量 z。
VAE 与变分 EM 的联系
VAE 中的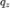 是一种各向同性高斯分布,我们可以通过另一个神经网络编码器来生成均值和方差:
是一种各向同性高斯分布,我们可以通过另一个神经网络编码器来生成均值和方差:
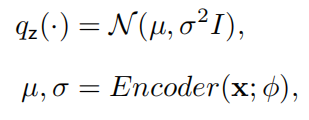
其中,μ 和 σ 为向量。在传统的变分 EM 算法中,我们需要找到最优的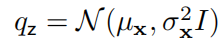 来为每个观测到的数据点 x 最大化
来为每个观测到的数据点 x 最大化 。VAE 使用了一种平摊变分推断(AVI)技巧,其中
。VAE 使用了一种平摊变分推断(AVI)技巧,其中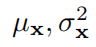 为编码器的输出,不同的数据点
为编码器的输出,不同的数据点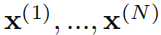 共享参数。AVI 技巧为了训练效率牺牲了部分的空间。
共享参数。AVI 技巧为了训练效率牺牲了部分的空间。
VAE 与 MCEM 和 Generalized EM 的关系
Generalized EM 认为我们无需在 E 步或 M 步中最大化 ELBO。我们可以通过 SGD 来优化和,尽管这样相较于传统的 EM 算法需要更多步运算。根据公式(4),我们有:

接着,我们通过梯度法优化
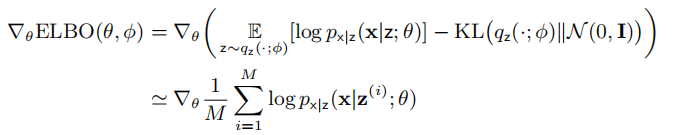
请注意,根据模型的定义,
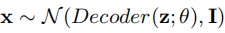

我们通过反向传播根据重构损失 得到 θ 的梯度,即观测数据 x 和模型输出
得到 θ 的梯度,即观测数据 x 和模型输出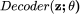 之间的均方误差。
之间的均方误差。
然而,由于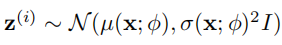 ,我们无法在计算
,我们无法在计算 的梯度时将
的梯度时将 视为常量,即采样分布依赖于
视为常量,即采样分布依赖于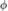 。
。
所以,我们需要进行重参数化处理,通过可微的操作将无关分布中采样得到的样本投影为目标分布 中。在 VAE中,我们通过
中。在 VAE中,我们通过
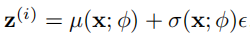 生成
生成 。
。
此时,ELBO 的梯度为:
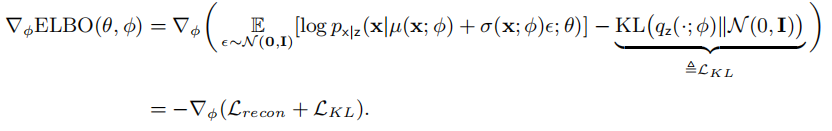
其中, 是两个各向同性高斯分布之间的 KL 散度,其解析解为:
是两个各向同性高斯分布之间的 KL 散度,其解析解为:

VAE 算法的流程如下:

7
VAE 的前沿研究话题
(1)VAE 中的解耦
VAE 和普通的自编码器之间的最大差别在于隐变量具有先验。VAE 需要最小化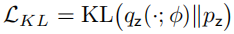 ,因此限制了 z 的空间。同时,VAE 也需要在模型中最大化训练数据 x 的对数似然。在这两个目标的作用下,VAE 通过学习使 z 称为 x 的最高效的表征,即 z 被解耦到不同的维度上。VAE 的简单变体 β-VAE 为 KL 损失引入了一个大于 1 的放缩因子,从而提升解耦的重要性。
,因此限制了 z 的空间。同时,VAE 也需要在模型中最大化训练数据 x 的对数似然。在这两个目标的作用下,VAE 通过学习使 z 称为 x 的最高效的表征,即 z 被解耦到不同的维度上。VAE 的简单变体 β-VAE 为 KL 损失引入了一个大于 1 的放缩因子,从而提升解耦的重要性。
(2)正向 vs 逆向 KL 散度
基于最大似然估计的生成模型实际上是在最小化正向 KL 散度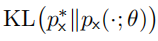 。此类方法的缺点在于,如果我们使用模型生成样本(例如,图片),其保真度较低,这是因为这类方法只会迫使模型为真实样本赋予高似然,但会忽视
。此类方法的缺点在于,如果我们使用模型生成样本(例如,图片),其保真度较低,这是因为这类方法只会迫使模型为真实样本赋予高似然,但会忽视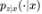 较低的区域 Z。从这些区域采样得到的样本 z 仍然可以被映射到具有较低
较低的区域 Z。从这些区域采样得到的样本 z 仍然可以被映射到具有较低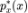 的 x 上。近期,许多工作(例如,VQ-VAE)将 VAE 与自回归模型结合,成功地提升了保真度。利用大规模文本-图像对预训练的 CogView 将 VQ-VAE 扩展到了图文生成领域。
的 x 上。近期,许多工作(例如,VQ-VAE)将 VAE 与自回归模型结合,成功地提升了保真度。利用大规模文本-图像对预训练的 CogView 将 VQ-VAE 扩展到了图文生成领域。
对抗生成网络(GAN)是另一种流形的生成模型,它通过对抗学习最小化 JS 散度。JS 散度是正向 KL 和逆向 KL 散度的结合。实际上,我们在函数空间中无法对生成器进行完美的优化,因此模型更加关注逆 KL 散度。逆 KL 损失倾向于在具有较高的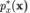 的区域生成样本,这使得生成的样本相较于正向 KL 散度更加逼真,但是这种模型也会导致模式崩溃现象,即生成过程无法覆盖数据分布的所有模式。
的区域生成样本,这使得生成的样本相较于正向 KL 散度更加逼真,但是这种模型也会导致模式崩溃现象,即生成过程无法覆盖数据分布的所有模式。
关于AI Open
AI Open是一个可自由访问的平台,所有文章都永久免费提供给所有人阅读和下载。该期刊专注于分享关于人工智能理论及其应用的可行性知识和前瞻性观点,欢迎关于人工智能及其应用的所有方面的研究文章、综述、评论文章、观点、短篇交流和技术说明。AI Open将作为中国面向国际人工智能学术、产业界的交流渠道,传播人工智能的最新理论、技术与应用创新,提高我国人工智能的学术水平和国际影响力。AI Open目前已被DOAJ收录,目前累计下载量已经达到6w+,乐观预计1年内能进入SCI。
AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你!
请将简历等信息发至yun.he@aminer.cn!
微信联系:AITIME_HY
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注

点击 阅读原味 查看论文原文
















 1
1











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









