







 点击蓝字关注我们AI TIME欢迎每一位AI爱好者的加入!对神经网络进行低精度量化,尤其是混合精度量化,是提升神经网络部署效率的重要方法之一。然而,如何让神经网络适应低精度的表示,如何选取最合适的量化精度,依然存在很多没有解决的问题。本报告将从两方面探讨低精度神经网络的训练方法。为了获得最优的量化精度,我们提出了BSQ比特稀疏量化算法,使模型能在训练过程中自发得到合适的混...
点击蓝字关注我们AI TIME欢迎每一位AI爱好者的加入!对神经网络进行低精度量化,尤其是混合精度量化,是提升神经网络部署效率的重要方法之一。然而,如何让神经网络适应低精度的表示,如何选取最合适的量化精度,依然存在很多没有解决的问题。本报告将从两方面探讨低精度神经网络的训练方法。为了获得最优的量化精度,我们提出了BSQ比特稀疏量化算法,使模型能在训练过程中自发得到合适的混...
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

对神经网络进行低精度量化,尤其是混合精度量化,是提升神经网络部署效率的重要方法之一。然而,如何让神经网络适应低精度的表示,如何选取最合适的量化精度,依然存在很多没有解决的问题。
本报告将从两方面探讨低精度神经网络的训练方法。为了获得最优的量化精度,我们提出了BSQ比特稀疏量化算法,使模型能在训练过程中自发得到合适的混合精度。
为了使模型更适应量化带来的性能影响,我们进一步提出了用权值鲁棒性描述模型泛化能力和低精度表现的理论模型,并依据此模型提出HERO训练算法以提升模型的权值鲁棒性,进而获得泛化能力强且对低精度量化鲁棒的模型。两种方法为获得更高效且性能更好得神经网络模型提供了可能性。
本期AI TIME PhD直播间,我们邀请到杜克大学电子与计算机工程系博士——杨幻睿,为我们带来报告分享《面向低精度量化的神经网络训练算法》。

杨幻睿:
本科毕业于清华大学电子工程系,博士毕业于杜克大学电子与计算机工程系,师从李海和陈怡然老师。博士毕业后,杨幻睿将加入加州大学伯克利分校从事博士后研究。杨幻睿的主要研究方向为提升深度学习模型的运行效率和鲁棒性。
今天要介绍的研究主要是关于高效深度学习的问题。我们发现随着深度学习的发展,学者们提出了越来越多神经网络的模型。在追求更高的模型性能的过程中,新提出的神经网络架构所占用的参数量需要的计算量都在逐渐提高。
Challenges of DNN from Efficiency Perspective
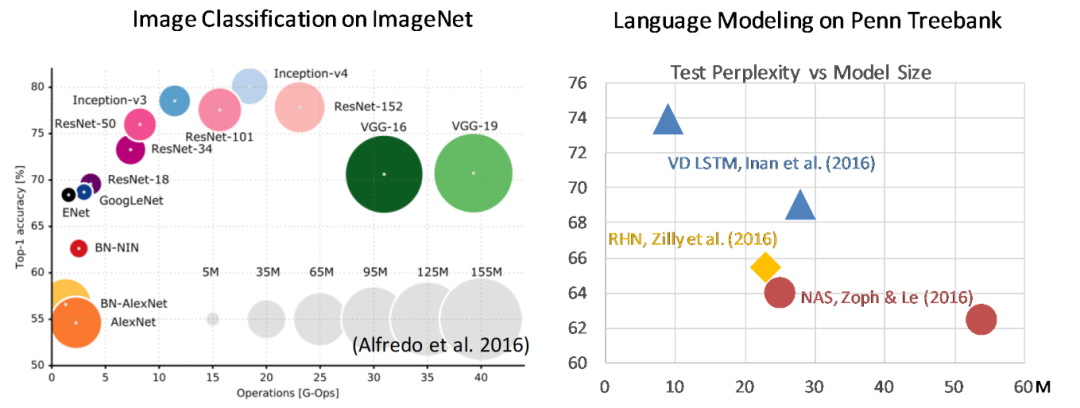
上图所示的还是一些相对较早的模型,我们现在用的transformer、Bert模型在取得更好性能的同时,都使用了更高的参数量与计算量。
尽管深度学习模型如今发展迅速,但如果我们想把模型用在实际场景之中,就要考虑在很多硬件设备上的计算能力是受限的。为了能够更好的将深度学习模型部署到现实世界当中,我们必须对这些高性能的模型进行压缩和加速。
Efficiency Improvement for DNN Models
• Pruning
• Set weight element to zero
• Save storage and computation (structural pruning)
• Low-rank factorization
• Decompose layer into low-rank matrix multiplications
• Keep input/output dimensions, suitable for complex architecture
• Quantization
• Represent weights/activations in fixed-point representation
• Reduce memory size, friendly to hardware deployment
目前主流的针对人工设计的模型的压缩加速方式大致分为3种。第一种是剪枝,既将一些权重设为0使其可以通过编码的方式减少一定程度的存储量。跟进一步可以通过结构化剪枝的方式直接减小模型参数的维度,实现计算量的减少。
第二种方法是对模型做低秩的分解,即把一个卷积层分解成两个或多个低秩的矩阵相乘。这样我们就可以在保留原始模型输入输出维度的基础上进一步缩小模型的计算量。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 14
14











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









