






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

本研究旨在理解和改进针对机器翻译任务的序列到序列的预训练,特别是预训练解码器的研究。
我们发现序列到序列的预训练对机器翻译任务来说是一把双刃剑:一方面这个模块可以提高翻译模型的译文的准确性和多样性;另一方面,由于预训练和下游微调任务的不同,预训练解码器会引入生成风格的偏移以及过度自信的问题,从而限制模型性能。
基于此,本工作提出了两个简洁有效的方法:领域内预训练和输入自适应。实验表明,我们的方法可以有效的提高模型性能和鲁棒性。
本期AI TIME PhD直播间,我们邀请到香港中文大学计算机系博士生——王文轩,为我们带来报告分享《理解和改进针对机器翻译任务的序列到序列预训练》。

王文轩:
香港中文大学计算机系博士研究生,师从Dr. Michael Lyu吕荣聪教授。主要研究方向是机器翻译等自然语言处理模型的可靠性。
我们经研究发现,预训练对于机器翻译任务而言是把双刃剑,一方面它可以提高机器翻译的性能,包括降低错误和提升翻译的多样性。
但同时,我们也发现了一些它的坏处,一个是数据的gap会导致翻译过程中发生迁移问题,从而影响最终的效果;另一个是预训练和下游任务目标的不同,会导致预训练模型在fine-tuning中遇到问题。基于此,我们提出了两种简单有效的方法,其中一种是加入一些noise。
Motivation
●Multilingual Pre-training for Neural Machine Translation
预训练在自然语言处理任务上的火爆,使其常常被用来提高下游任务的性能。

经过预训练后,在下游任务中的自然语言处理就能够达到一个很好的效果。但是对于机器翻译来说,存在一个gap。
对于自然语言理解模型,有一个encoder就可以了;但是对于机器翻译来说,我们需要一个encoder和一个decoder。

●How much does the jointly pretrained decoder matter?
在本研究之中,我们想办法去理解这种decoder的作用。
Understanding
● Inpact on translation performance.

如上图,我们load了不同的组件,如预训练后的encoder和decoder我们也有一些新的发现,比如预训练encoder比预训练decoder的效果更明显;
尽管如此,预训练的decoder如果load进去也能进一步的提升翻译性能,但是这个性能在下游任务是高资源的时候并不明显。我们在下面挑选了一些case来展示:

首先,我们发现用了预训练decoder的模型很容易生成高质量翻译的,不过其会每次进行调整顺序,导致容错较低。其次,在低资源的fine-tuning上,如果漏掉decoder会显著减少翻译的错误。
基于以上两点发现,我们进行了详细的实验。
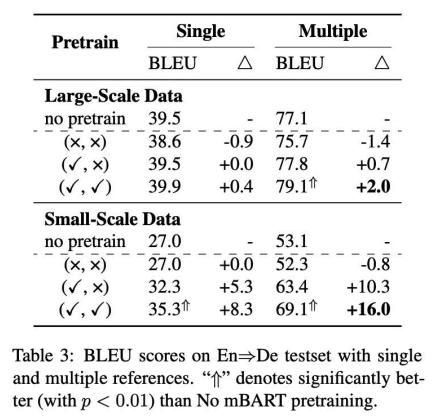
我们将multiple reference作为测试集来衡量模型的性能,通过这种multiple reference evalution,我们可以显著的提升模型的性能。对于降低错误,我们组织了一个详尽的human evalution,然后发现继承decoder之后可以显著的降低翻译错误。
上述介绍的都是Seq2Seq pretraining的好处,下面我们介绍一下因为上游pretrain任务和下游机器翻译任务的不同而在后续可能导致的问题。
● domain discrepancy
● objective discrepancy
首先,我们来看domain的不同。
■ Domain Discrepancy
◆ lexical Distribution in Training Data
◆ a clear difference between WMT news data and CC data.
◆ a domain shift from pretraining to finetuning.
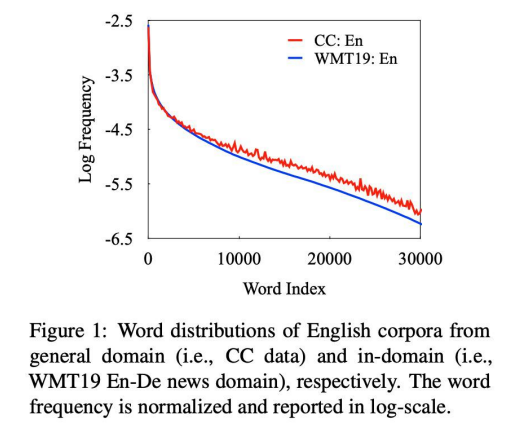
我们来衡量了这种domain gap,并画出了词的分布。上图显示,越往右则会发现词频越少。CC data和WMT data分布的不同在尾部越发的明显。预训练和下游任务是有一个domain gap的。
刚刚我们分析的是训练集,接下来我们通过一个分类器来证明对WMT来说,其训练集和测试集是同分布的。方法是我们训练了一个WMT data的训练集和CC data的二分类,来对我们的测试集进行分类。
我们发现,大部分的数据都被分到了WMT,也就是说WMT的测试集是更像WMT的训练集的。也就是说,当我们下游在测试时,预训练和测试集其实是有一个domain gap的。

上游任务和下游任务的目标函数也是不同的。
■ Objective Discrepancy
● NMT learns to translate a sentence from one language to another
● Seq2Seq pretraining learns to reconstruct the input sentence
上游任务主要是生成任务,下游任务主要是翻译任务。下面,我们通过对模型表现进行分析来展示目标函数的不同导致的影响。
●model uncertainty: compute the average probability at each time step
● jointly pretraining decoder significantly improves model certainty after the first few time steps
● jointly pretraining decoder leads to a improvement of certainties, suggesting that the pretrained decoder tends to induce the over-estimation issue of NMT model

上图展示了对average probability的计算,如果我们有了预训练decoder,模型也会更相信自己生成了什么。
我们做了两组实验:一组是让模型生成reference,一组是让模型生成错误的instructor。我们发现如果load了decoder,对模型也会出现over estimation的问题。
● Hallucination under Perturbation.
● evaluate the model’s tendency of generating hallucination under noisy input
● jointly pretraining decoder is less robust to perturbed inputs and produces more hallucinations

我们衡量了一下模型出现幻觉的比例,对模型进行扰动来看hallucination的变化。我们发现加入预训练decoder后,hallucination的现象是明显加重的,体现在BLEU的下降与hallucination次数增多。
● beam search problem
● jointly pretraining decoder suffers from more serious beam search degradation problem
● larger beam size introduces more copying tokens than the other model variants.

另一个over estimation的后果就是beam search problem。当模型把beam search开大的时候,更容易出现性能下降。我们发现在使用decoder之后,模型性能的下降会更多。
Improving
接下来,我们提出了两种简单有效的方法来解决上述问题。
● In-domain pretraining
■ continue the training of mBART on the in-domain monolingual data.
■mask 35% of the words in each sentence by random sampling a span length according to a Poisson distribution.
● Input Adaptation in Finetuning.
■ add noises (e.g., mask, delete,permute) to the source sentences during finetuning, and keep target sentences as original ones.
■ we add noises to 10% of the words in each source sentence, and combine the noisy data with the clean data by the ratio of 1:9, which are used to finetune the pretraining model.

实验结果如上图所示,
● In-domain pretraining可以显著的提升翻译质量
● Input adaptation在保证翻译质量的同时可以显著地增加模型鲁棒性
● 两种方法同时使用可以既提升翻译性能,又增加模型的鲁棒性。
下面,我们做了一系列分析来证明我们的方法可以用来解决上述问题。
● Narrowing Domain Gap.
■ calculate the word accuracy of the translation outputs by the compare- mt.
■ the improvements on low-frequency words are the major reason for the performance gains of in-domain pretraining
■ confirm our hypothesis that in-domain pretraining can narrow the domain gap with

我们发现,在减小Domain Gap的过程中,我们的提升都来自low-frequency即尾部的提升,一定程度上我们减小了尾部的gap。
接下来,我们来看下我们的方法缓解Over-Estimation和Beam Search问题上的应用。
● Alleviating Over-Estimation
■ our approach successfully alleviates the over-estimation issue of general pretraining in both the groundtruth and distractor scenarios

● Mitigating Beam Search Degradation.
■ the input adaptation approach can noticeably reduce the performance decline when using a larger

Conclusion
● 我们发现了Seq2Seq pretraining一种针对机器翻译任务的序列到序列预训练,也是一把双刃剑:
■ 一方面,它帮助模型有更好的翻译性能
■ 另一方面,由于预训练与下游翻译任务的gap,domain discrepancy限制了模型的性能,objective discrepancy可能使得模型出现over estimation的问题。
● 我们针对上述问题提出了两种简单而有效的方法,in-domain pretraining 和input adaptation 有效缓解上述问题。
提
醒
论文题目:
Understanding and Improving Sequence-to-Sequence Pretraining for Neural Machine Translation
论文链接:
https://arxiv.org/pdf/2203.08442.pdf
点击“阅读原文”,即可观看本场回放
整理:林 则
作者:王文轩
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了700多位海内外讲者,举办了逾300场活动,超260万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看回放!
















 46
46











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









