






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
ImageNet预训练也会迁移非鲁棒性
ImageNet Pre-training also Transfers Non-Robustness
作者:张家明,桑基韬,易琪,杨云帆,董惠雯,于剑
单位:
北京交通大学,计算机与信息技术学院&交通数据分析与挖掘北京市重点实验室
邮箱:
jiamingzhang@bjtu.edu.cn,
jtsang@bjtu.edu.cn,
21125273@bjtu.edu.cn,
19281298@bjtu.edu.cn,
202131081024@mail.bnu.edu.cn,
jianyu@bjtu.edu.cn
论文:
https://arxiv.org/abs/2106.10989
代码和数据集:
https://github.com/jiamingzhang94/ImageNet-Pretraining-transfers-non-robustness
01
概述
在深度学习的发展过程中预训练承担了十分重要的角色,预训练技术的核心逻辑是通过在大规模数据集上进行训练从而使模型获得了强大的特征提取能力,然后在目标数据集上进行微调以获得高准确率。但是我们发现使用预训练模型在目标数据集上进行微调的方法不只会继承原始模型的优点,也会将缺点带入微调后的模型中。如图1所示,标准训练的模型和微调模型在泛化性(原始图像)上表现相似,但是进行相同强度的对抗攻击(对抗图像)之后,预训练模型相比于标准训练的模型出现了相当大的预测准确度下降,这说明存在使用预训练之后的模型鲁棒性会有下降的问题,而人们往往注重高准确度使用预训练技术而忽视了其低鲁棒性问题,但是鲁棒性对于可靠性要求更高的任务上也是很重要的问题。
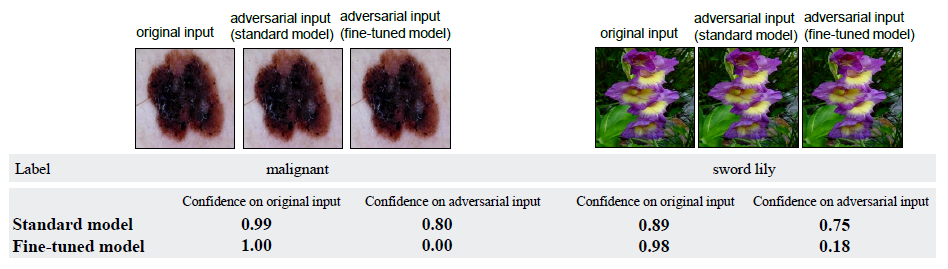
图1:标准训练的模型和在预训练模型上进行微调的模型虽然对于原始的输入表现相当(后者略强),但是对于对抗输入(添加噪声)的预测值却相差很大。
我们深入探究了使用预训练模型会使鲁棒性下降的原因,我们首先从知识的角度出发,经过微调后的预训练模型和标准训练的模型可以被认为是除了使用不同初始参数之外,训练集完全相同、模型结构完全相同的两个模型。理论上这两个模型学到的知识应该是相似的,但是我们通过实验分析发现:从知识的角度来说,经过微调的预训练模型和标准训练的模型,而经过微调后的预训练模型却与源模型(用ImageNet数据集训练出来的模型)更加相似,这说明预训练模型继承到了源模型的知识。进一步我们推测鲁棒性降低可能正是因为预训练模型继承了源模型的知识,而源模型中包含了捷径/过多利用非语义信息,标准训练得到的模型含有较少的非语义信息。进一步,我们想知道微调后的预训练模型到底是否利用了过多的非语义信息、利用了怎样的非语义信息以及标准训练得到模型是否含有较少的非语义信息,于是我们借用通用对抗噪声这一工具来进行可视化。通用对抗噪声是一种固定的图像噪声,而对于目标模型来说,几乎任意的图像加上这种固定的噪声都会使模型识别出错,所以通用对抗噪声可以被认为是一种模型所认为的“强图像特征”,强大到足以使模型忽略原始图像中的其它所有特征而只依赖此特征。我们分别提取出了标准训练模型与预训练模型的通用对抗噪声并将其可视化,结果表明标准训练模型中的通用对抗噪声含有更多人类所能理解的语义信息,而预训练模型的通用对抗噪声几乎全部是人类无法理解的非语义信息,这说明这两个模型在进行推理时使用的特征偏好有相当大的不同,进一步证实了预训练模型利用了过多的非语义特征。最后,通过对于模型所形成的特征空间的陡峭度的不同,我们提出了一种非常简单的提升鲁棒性的解决方案。
总的来说,本文的主要逻辑如下:1)ImageNet预训练是一种常用而且经典的技术,特别是当训练数据缺乏的时候;2)但是我们发现它在提升泛化性的同时也降低的鲁棒性,进而我们探究了造成这一现象的原因;3)我们通过知识评估工具SVCCA和UAP发现了微调模型中的非鲁棒性源于预训练模型;4)进而,我们发现模型的容量和源任务与目标任务的差异是导致鲁棒性下降的因素。
02
ImageNet预训练并不鲁棒
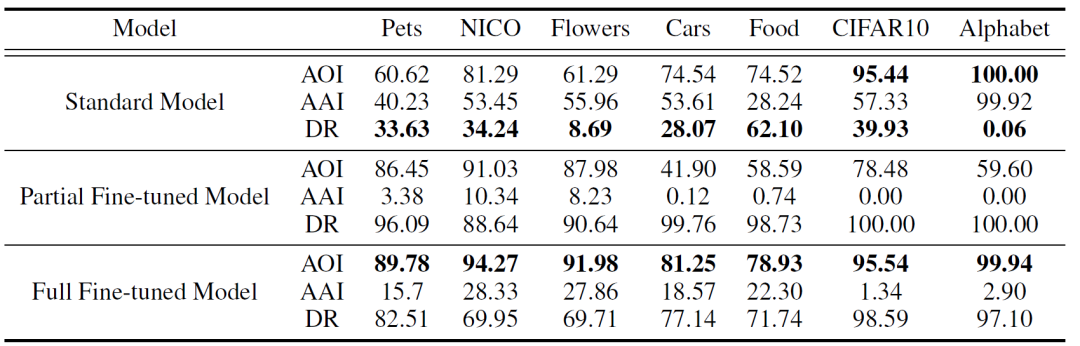
表1:标准模型(Standard Model)、部分微调模型(Partial Fine-tuned Model)和完全微调模型(Full Fine-tuned Model)之间的泛化性和鲁棒性比较。对于每个模型,我们报告了原始输入的准确性(AOI),对抗性输入的准确性(AAI),以及下降率(DR)。
我们首先在7个数据集上进行了鲁棒性实验。我们使用的评估指标是原始输入的准确性accuracy of original inputs (AOI),对抗性输入的准确性accuracy of adversarial inputs (AAI) 和下降率decline ratio (DR)。其中DR = (AOI-AAI)/AOI。我们对三种模型进行了对比,依次是从头训练的标准模型(Standard Model)、只微调全连接分类层的部分微调模型(Partial Fine-tuned Model)和微调全部网络层的完全微调模型(Full Fine-tuned Model)。如表1所示,(1) 对于大多数数据集,微调模型通常比标准模型取得更好的泛化能力(AOI),但鲁棒性(AAI和DR)更差。这表明,预训练不仅提高了识别目标任务原始输入的能力,而且还转移了非鲁棒性,使微调模型对对抗噪声更加敏感。(2)在两种预训练设置中,完全微调始终比部分微调设置获得更好的鲁棒性和泛化性。这表明,在实际应用中采用预训练时,完全微调是最好的,以减轻鲁棒性的下降。(3) 对于CIFAR10和Alphabet,当在目标数据集上训练的标准模型已经实现了良好的AOI时,预训练对泛化的改善是微不足道的(甚至在CIFAR10上进行部分微调时,AOI下降),但对鲁棒性造成了非常严重的损害。在这种观点下,预训练非但没有改善微调模型,反而起到了毒化模型的作用(模型在遇到正常输入时表现正常,但对于某些特定的输入,异常的模式被激活)。这进一步说明了任意采用预训练的风险,以及探索预训练在后续目标任务中表现的影响因素的必要性。
03
微调模型和标准模型的不同
3.1 知识衡量
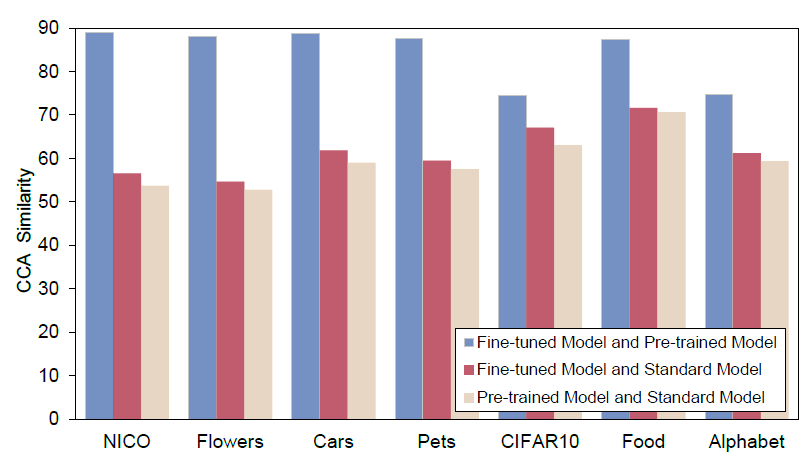
图2:不同模型之间的CCA相似度,值越大代表两个模型越相似。
为了理解微调模型和标准模型之间的性能差异,我们以CCA相似度为工具,对两者所学到的知识进行了衡量。微调模型和标准模型可以被看做两个初始化不同但是训练过程相同的模型(在同一个目标数据集上进行微调),但是通过图2我们可以发现,微调模型与预训练模型的相似度远比微调模型和标准模型的相似度要高。这反映了微调模型中的网络参数并没有发生大幅度的变化,也证明了微调模型的大部分知识其实是来源于预训练模型之中的。
3.2 非鲁棒特征
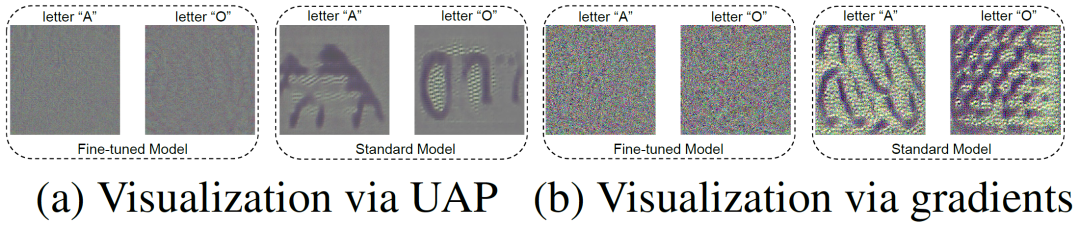
图3:对于英文字母A和英文字母O的不同的可视化结果。
为了能更好的理解微调模型从预训练模型中学到的“知识”到底是什么,我们对特征进行了可视化。这里我们除了用到了经典的使用梯度的可视化工具之外,还使用了UAP。UAP指的是通用对抗噪声,它本身属于一种图像无关的对抗噪声,也就是对于任意的图像被UAP扰动之后都可以愚弄模型。但也正是因为这种不依赖于原始图像中特征的特点,我们认为UAP中本身就包含了“强大的”特征,这种强大指的是在模型看来拥有最高的特征优先级,所以UAP也可以被理解为模型进行识别所依赖的特征。举个例子,如果任何一张图像添加上英文字母“A”的UAP之后都会被模型识别为字母“A”,那么我们就可以认为这张英文字母“A”的UAP其中包含了模型所认为的“强大的”字母“A”的特征。如图3所示,我们可以发现标准模型所利用的特征包含了更多的语义信息,相比于微调模型。这从可视化的角度说明了微调模型使用了更多人类所无法理解的非语义特征。
04
源自于预训练模型的非鲁棒性

表2:模型容量对于鲁棒性的影响。
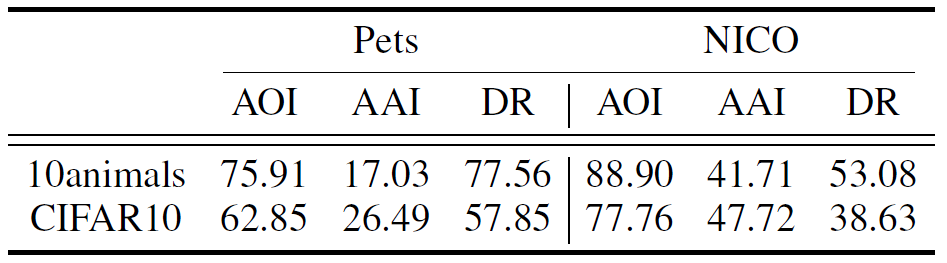
表3:源任务难度对于鲁棒性的影响。
既然微调模型的非鲁棒性是来自于预训练模型,那么到底是什么因素导致的?我们从模型容量和源任务难度这两个角度进行了探究。表2展示了不同容量的模型的结果,随着模型容量的增大,鲁棒性也越来越高。而源任务难度则相对复杂一些,我们使用了一个ImageNet的子集10animals和CIFAR10作为源数据集而进行对比,如表3所示,我们可以发现以10animals这种更难的数据集作为源任务虽然可以得出更好的泛化性,但是也导致了更差的鲁棒性。
05
一个简单的解决方案
最后,我们利用特征空间的陡峭度提出了一种非常简单的提升预训练过程鲁棒性的解决方案,其中我们使用了Local Lipschitzness来衡量特征空间的陡峭度:
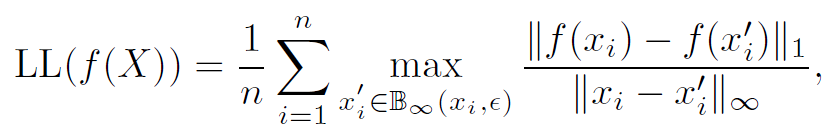
我们观察到对于相同的任务和模型结构,标准模型和微调模型的Local Lipschitzness值相差很大,前者小而后者大。于是,我们提出了一种方法叫做Discrepancy Mitigating (DM)来减小微调过程中的Local Lipschitzness值:
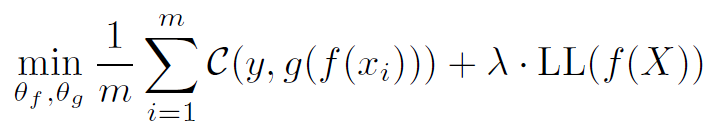
我们在7个数据集上进行了实验,ResNet-18的结果如表4所示。
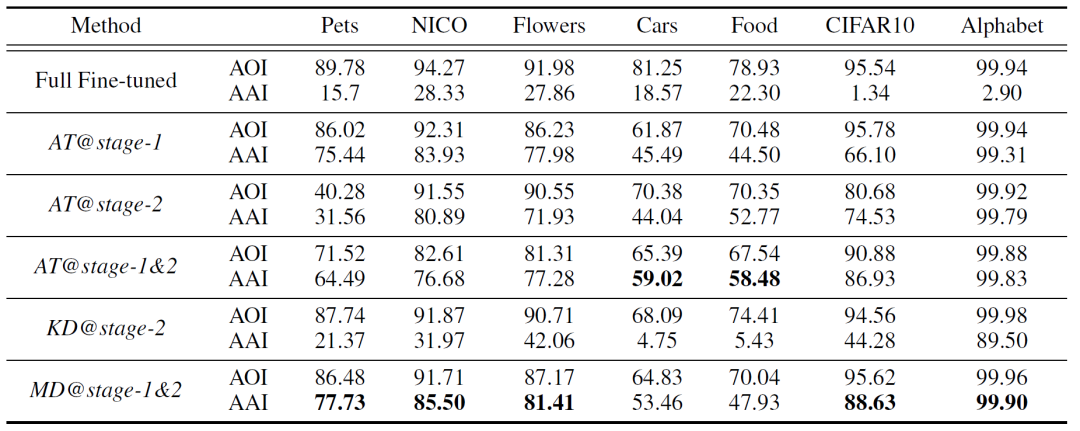
表4:DM与基线方法的比较。
需要注意的是,这个简单的方法几乎可以在所有的数据集上得到最佳的鲁棒性效果。
06
讨论
本文虽然只研究了ImageNet的预训练,但是同样至关重要的是研究其他迁移学习的可靠性,如知识蒸馏和域适应。一个特别的例子是迭代式的迁移学习中的不可靠性积累。比如,越来越多的人试图通过预训练好的模型来进行自动标注数据,然后这些数据被用来训练下一个模型。由于很难分辨数据是由人类还是由模型标记的,因此存在着将伪标签从一个模型迭代到另一个模型的风险。如果没有人类的干预来纠正潜在的错误知识,知识在模型之间的不断转移很可能导致社会学中所谓的 "回音室 "情况。正如在这项工作中所观察到的,一次知识转移就会导致相当大的可靠性问题,而反复的转移可能会导致灾难性的结果。总之,仍有许多工作要探索非可靠性转移背后的机制,我们正在努力开发更可靠的迁移学习。
E
N
D
文案:张家明
排版:辛梓源
审核:赵宪
责任编辑:桑基韬
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了900多位海内外讲者,举办了逾450场活动,超500万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看回放!


















 131
131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









