






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
以下文章来自 PaperWeekly 杨梦月:
NeurIPS 2023 接收的 Spotlight 论文“Invariant Learning via Sufficient and Necessary Cause”提出了一种在不变学习当中学习充分必要因果的解决方案。其能够在从数据中寻找不变表征的基础上,在表征中囊括更加关键的信息-预测目标的充分必要原因。本文从理论和实验的角度都证实了该方法能够在数据中有效的找到关键信息,并且在分布外泛化场景中有良好的表现。

论文标题:
Invariant Learning via Sufficient and Necessary Cause
论文地址:
https://arxiv.org/pdf/2309.12559.pdf

背景
分布外泛化(OOD Generalization)问题近年来引起了越来越多的关注。该问题的关注在训练数据和测试数据服从的分布不同的情况下,在训练数据(ID data)上学习到的模型怎样能在测试数据上也能达到较好的效果。现在分布外泛化的主流解决方案一般是学习数据中的不变表示。
比如有关 Invariant Risk Minimization [1] 的一系列工作,这些方法一般会假设数据 (比如图片)的生成过程是由因果特征 和域信息 比如环境/风格特征构成的,方法目标为通过模型推断出数据中的因果表征。
一般在分布外泛化问题中,常见的数据生成假设有以下图里的三种。在每个假设中因果信息 和数据标签 之间的关系都不会受到域(domain)信息 的干涉。为了更好的理解,在猫预测任务中,猫的身体,猫耳形状等一般被认为是因果信息,这些信息一般不会因为图片风格发生变化而产生改变。所以,在分布外泛化问题中存在一个从 因果机制不变的基本假设:.
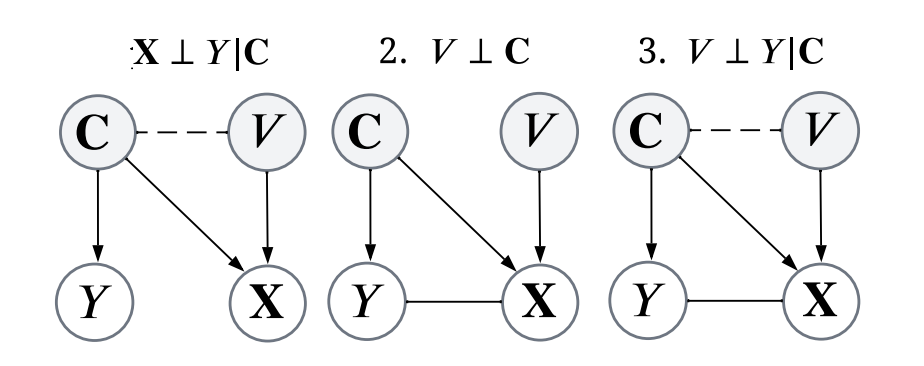
在现有的不变学习方法中,一般会以找到所有可能的因果为目标。但是也并不是所有的因果信息在泛化任务中都是最关键的,如果找到不当中关键的因果信息很有可能会误导模型导致产生错误的预测结果。比如下面的例子(图源于 bilibili 视频《你以为这是猫?》)。在这个例子当中,把尖耳当作分辨动物的原因会导致错误的预测结果。


动机
2.1 怎样的因果特征是最关键的?
我们可以考虑下面的例子。

我们有三种图片样例,预测任务为分类图片中是否有猫。每种都包含三种特征(1. 尖耳(pointy ear),2. 是否有猫爪(cat feet),3.短嘴(short mouth))。
如果我们以第一种图片(ID data)为训练数据,我们可以得到尖耳,猫爪和短嘴均为有利于分类的因果特征。但对于分布外(OOD)测试数据来说,尖耳和猫爪并不是足够好的特征。原因是在于(1)其他动物,比如狐狸,也拥有尖耳(2)图片由于风格和剪切的问题,不一定能看到猫爪。
在这个例子中,尖耳是预测猫的必要不充分条件,因为当我们知道图里有猫的时候,我们必然能知道猫有尖耳,但是如果我们看到图里有尖耳,这张图里不一定包含猫,可能是其他动物。同理,猫爪是预测猫的充分不必要条件,因为当我们看到图里有猫爪的时候,我们知道图里的动物是猫,但是一张有猫的图片不一定有猫。
所以,当我们探索学习因果信息的时候,还需要考虑这个因果信息对预测结果是不是充分且必要的,这样能够降低模型分布外泛化的风险。
在训练样本能够覆盖所有可能出现的情况时,方法不用经过特殊设计也能够很直接的找到那些最关键的特征(比如短嘴)。但是由于不一定能在训练数据中囊括所有的情况,这时就需要通过设计方法找到那些充分必要的特征。
2.2 如何定义充分必要的因果?
充分必要因果概率(probability of necessary and sufficiency),简称 PNS,定义于 Judea Pearl Causality 这本书中的第九章。PNS 的具体定义为:
定义1:[PNS] 对于变量 的两个观察取值 . 是 的充分必要因的概率为:
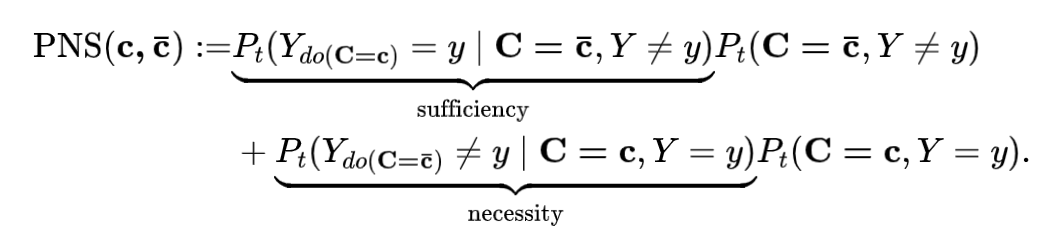
注意到,在 PNS 定义中,概率均为反事实概率。举个例子,反事实概率 的含义为当观察到 ,这时如果把 强制设置为 ,即符号 ,此时 的概率。
反事实概率很难直接计算,当满足两个条件,单调性(Monotonicity),和外生性(Exogeneity),即 是 的因时,PNS 可以直接从数据分布中计算(可识别)。

方法
为了使模型可以更好的找到拥有更高 PNS 值的表征,我们在文章中提出了一种新的目标函数-PNS risk。通过降低 PNS risk,达到学习充分必要的因果表征的目的。PNS risk 定义为:
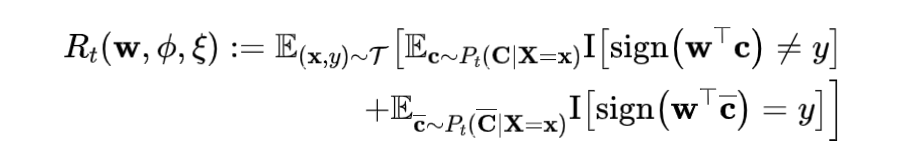
PNS Risk 的定义是受到 PNS 定义直接启发得到的,我们将其中的两项分别写为 。考虑到 PNS 的可识别性需要由 Monotonicity 和 Exogeneity 来保证,所以对这两个性质能否满足做了进一步的探讨。
3.1 如何满足Monotonicity
首先,定义 Monotonicity 度量 risk 为下面的形式。
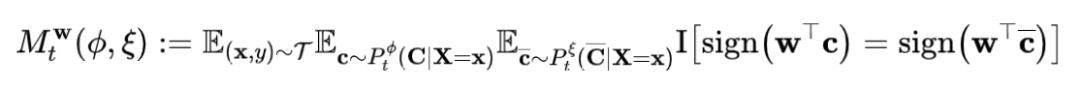
我们发现,PNS risk 可以直接分解成 Monotonicity 度量和 SF,NC 的表达式。
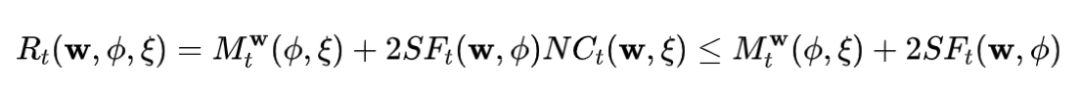
所以我们可以通过在优化过程中直接优化该项来显式的使表征满足 Monotonicity。
3.2 如何满足Exogeneity?
Exogeneity的满足表示我们找到的表征里包含了 Y 的因信息(不一定是充分且必要的因)。如果方法能够寻找在因果图中的不变表征,那么这一条件就能满足。我们讨论了三种情况,分别对应图 1 中的三种因果假设。
对于假设 1 来说,优化目标函数(PNS risk)可以直接满足寻找不变表征的需求,不需要引入额外的域信息(变量 V)。对于假设 2 来说,需要额外引入域信息,增加 Maximum Mean Discrepancy (MMD) 的约束项在目标函数中,来降低表征和域选择之间的关联性。假设 3 也是 IRM 方法的因果假设,在这样的因果假设下学习不变表征需要在目标函数中引入 IRM 方法当中的惩罚项。该讨论可以具体参考文章中的 4.1 章。
3.3 最终的优化目标
由于在实际场景中,因果变量 具有较大的取值范围,并且有非常多 和 的关联函数形式。并不是在所有情况下都能得到有意义的 PNS risk,所以我们需要讨论数据在什么情况下优化 PNS risk 能够帮助表征的学习。我们假设因果变量 在一个微小的扰动下,不会改变其对 的预测结果,在这种情况下,PNS 值的估计是有意义的。所以我们假设预测场景中存在语义可分性,在该假设中,我们表达了一个性质-对于不同的 的取值 来说,其对应的因果变量 的取值之间需要有一定的差别。具体为:
假设4.1(-语义可分性). 变量 是 -语义可分的,仅当对于任意的 和 ,都存在:.
不满足语义可分性的表征对应的 PNS 值不能用来反应真实的 PNS 值,因为对表征的一个微小的扰动就会导致 PNS 值发生较大的变化。
我们还对 PNS risk 做了泛化分析,关联了训练数据上的 PNS risk 和测试域上的 PNS risk。理论支持我们通过在训练数据上优化相关的 risk( 等)而得到更好的测试域上的 PNS risk( 等)。详细内容可参见原文。最终方法的优化目标为:
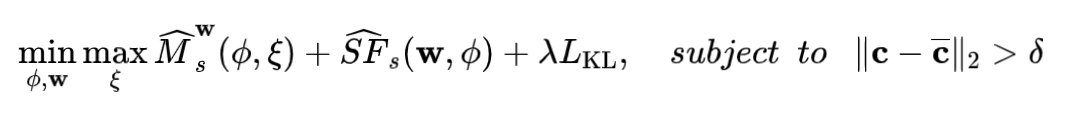
其中 项为 的表征的先验分布和后验分布之间的 KL 散度。对于图 1 中的因果假设 2 和 3 来说,需要增加额外的惩罚项以满足不变表征的学习。

实验
在实验部分我们做了以下讨论。
1. 在模拟数据上验证了是否能在数据中学到充分必要因;
2. 在真实的 OOD 数据上验证了方法是否能做到较好的分布外泛化。
4.1 模拟数据
我们按照图 1 中的因果假设 1 来设计模拟数据。特征 X 中包含了分别带有充分性,必要性,充分必要性的因果信息,以及带有假相关性的域信息。实验结果如下图所示:
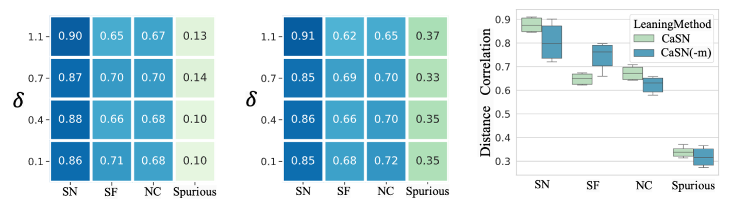
实验统计了学到的表征和各个因果信息以及假相关信息之间的距离相关系数,结果显示,我们的方法 CaSN 能够有效的识别出充分必要因(SN)信息。如果去掉 Monotonicity 组件的话,CaSN 将有很多时候混淆充分必要因(SN)和充分因(SF)。在朝参数 升高的时候,CaSN 会有更好的性能,这是因为符合 语义可分性。
4.2 OOD数据
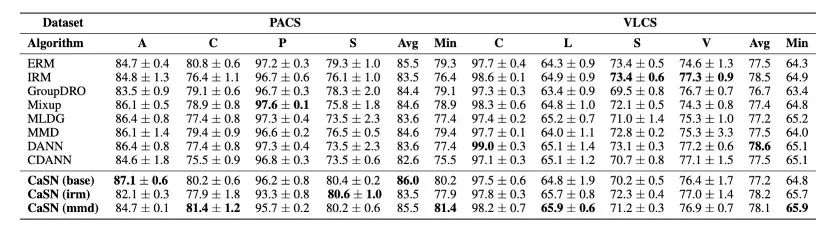
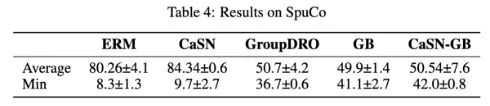
我们在 DomainBed 和 SupCo 提供的 benchmark 和代码进行了实验,实验数据包含 PACS 和 VLCS 以及 SupCoAnimals,实验结果如表格所示。我们的方法在 OOD 泛化以及含有假相关性的场景都有不错的表现。

总结和展望
本文阐述了在分布外泛化场景里充分必要性的因果学习的动机,以及提出了一种方法能够有效的学习到观察数据当中的充分必要因果表征,并在分布外泛化场景具有一定的效果。未来我们还将在因果假设,更多形式的预测方程上做进一步的探索。
由于篇幅原因,我们省略了很多文章细节,感兴趣的同学可以参考原文,如有疑问以及关于文章内容的交流可以联系文章作者杨梦月(邮箱:mengyue.yang.20@ucl.ac.uk)。

参考文献
[1] Arjovsky, Martin, et al. "Invariant risk minimization." arXiv preprint arXiv:1907.02893 (2019).
[2] Pearl, Judea. Causality. Cambridge university press, 2009.
提
醒
点击“阅读原文”跳转至1:37:42
可以查看回放哦!
往期精彩文章推荐

关注我们 记得星标
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1400多位海内外讲者,举办了逾600场活动,超600万人次观看。

我知道你
在看
哦
~

点击 阅读原文 跳转至“1:37:42”查看回放!
















 35
35

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









