






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
平时工作学习中,训练模型时候比较重要的两个超参数是Batch size和Learning rate。在采用不同Batch size训练时候,该如何调整学习率?不同的优化器上Batch size对最佳学习率的选择是否有影响?
为了回答上面的问题,我们过往的研究做了一些调研:
2014年Alex在自己的“笔记”(https://arxiv.org/pdf/1404.5997)中记录过这样一段话:
Theory suggests that when multiplying the batch size by k, one should multiply the learning rate
by √ k to keep the variance in the gradient expectation constant.
他说理论建议学习率应该随着Batch size的平方根放缩。
但是2018 年的一份工作(https://arxiv.org/pdf/1706.02677)中指出:
To tackle this unusually large minibatch size, we employ a simple and hyper-parameter-free linear scaling rule to adjust the learning rate. While this guideline is found in earlier work [21, 4], its empirical limits are not well understood and informally we have found that it is not widely known to the research community.
Alex提到的理论似乎失传了,并且他们发现可能直接采用随着Batch size的线性放缩更合适。
就在学习率放缩率这样反复横跳的时候,2018年年底OpenAI Scaling law的序章之一(https://arxiv.org/pdf/1812.06162)中对采用SGD进行Large-Batch训练的模型行为进行了系统的理论阐述和实验验证。其中一个比较重要的结论是,SGD 优化的模型其Batch size和Learning rate的放缩率服从:
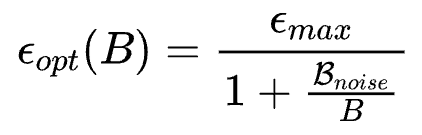
其放缩行为如下图所示:
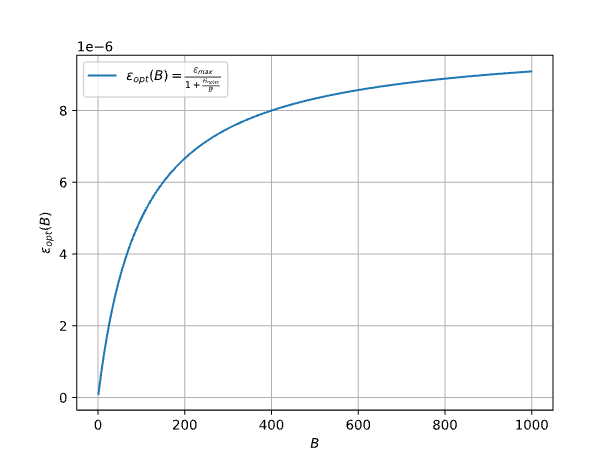
在Batch size较小的时候,学习率确实是近似与Batch size线性放缩的。但是随着Batch size变得更大,最优的学习率逐渐趋于饱和。
那么有了上述理论结果是否意味着,Batch size和Learning rate 放缩关系这个问题已经彻底解决了?似乎OpenAI文章中的一段小字预示了结论:
To tackle this unusually large minibatch size, we employ a simple and hyper-parameter-free linear scaling rule to adjust the learning rate. While this guideline is found in earlier work [21, 4], its empirical limits are not well understood and informally we have found that it is not widely known to the research community.
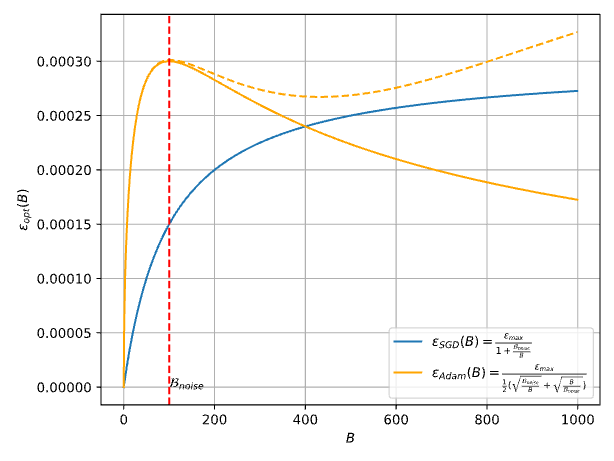
Emm...,好像Adam在实验现象和理论结论上有一些偏差,结果好坏参半。
AITIME
01
理论发现
最近我们的一份工作(Surge Phenomenon in Optimal Learning Rate and Batch Size Scaling)中


AITIME
02
验证理论
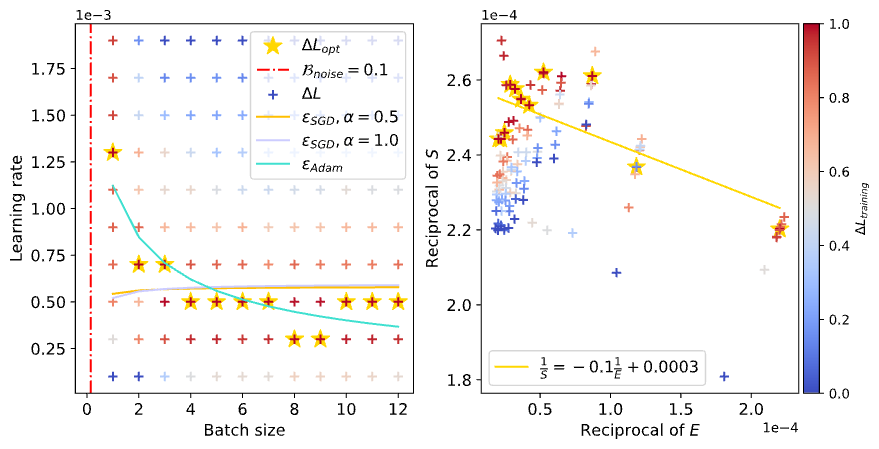
通过网格搜索可以观察到不同Batch size和Learning rate配置下Loss下降的快慢(下图中颜色越红,下降越快),如果理论正确的话,利用理论公式推算的Scaling law曲线应该可以尽可能的穿过图中红色区域:

AITIME
03
观测「浪涌现象」
使用和上一节相同方式,画出训练过程中不同Loss水平的Scaling law曲线,并观察「浪尖」的变化:
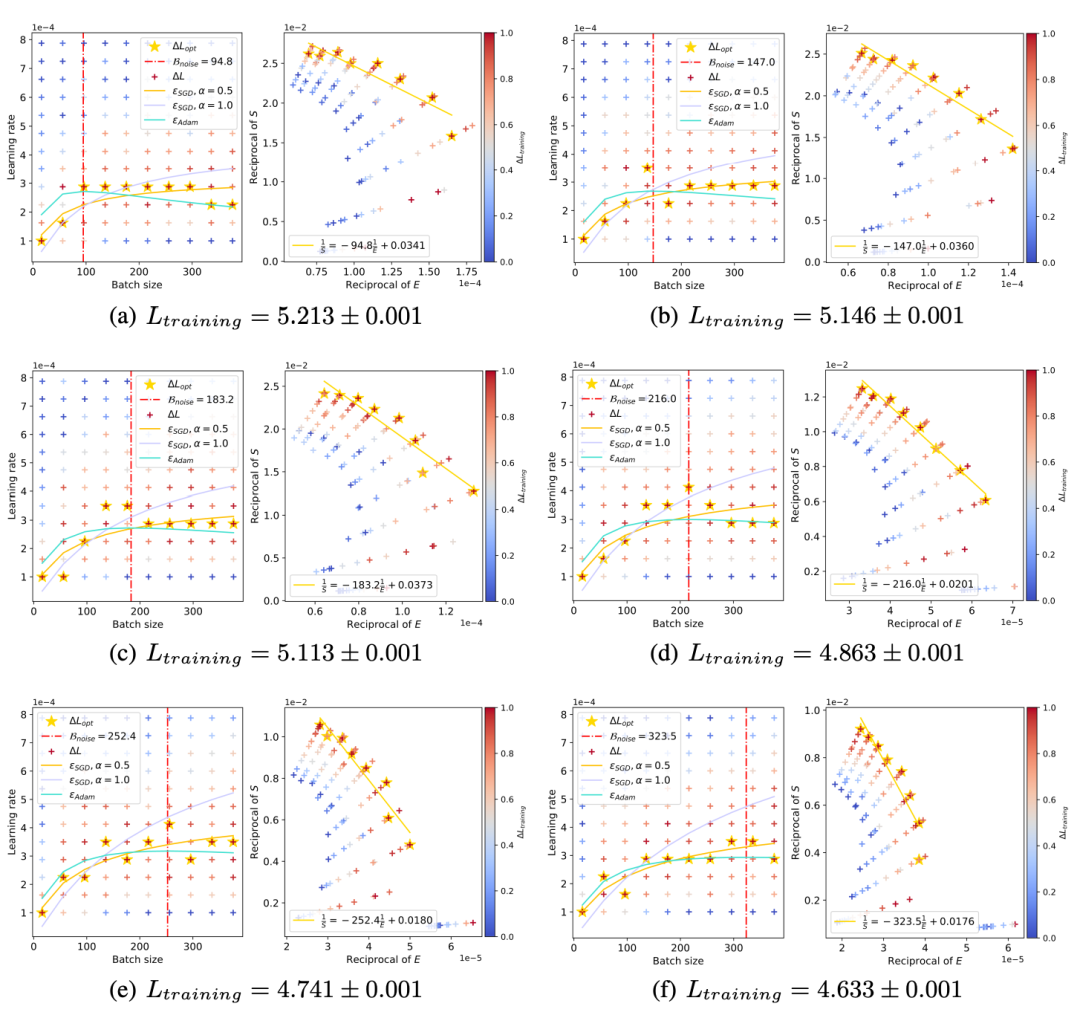
可以看到,随着训练Loss的降低,「浪尖」确实在逐渐向右也就是更大Batch size的方向移动。
AITIME
04
额外的想法

往期精彩文章推荐

论文解读 | CVPR2024:Sherpa3D:通过粗略的3D先验提升高保真文本到3D生成
记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1800多位海内外讲者,举办了逾600场活动,超700万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 查看更多!
















 44
44

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









