



点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

宋世超
中国人民大学博士生
AITIME
01
引入
LLM的蓬勃发展带来了许多潜在的机遇,但是,幻觉问题却成为实际应用落地前需要克服的重要障碍。假如你是一个新闻编辑,正在用LLM撰写新闻,如果生成了如图1中示例的文本,那基本就是在帮倒忙,因为每一个词,每一个数字都还需要你重新去确认正确与否。
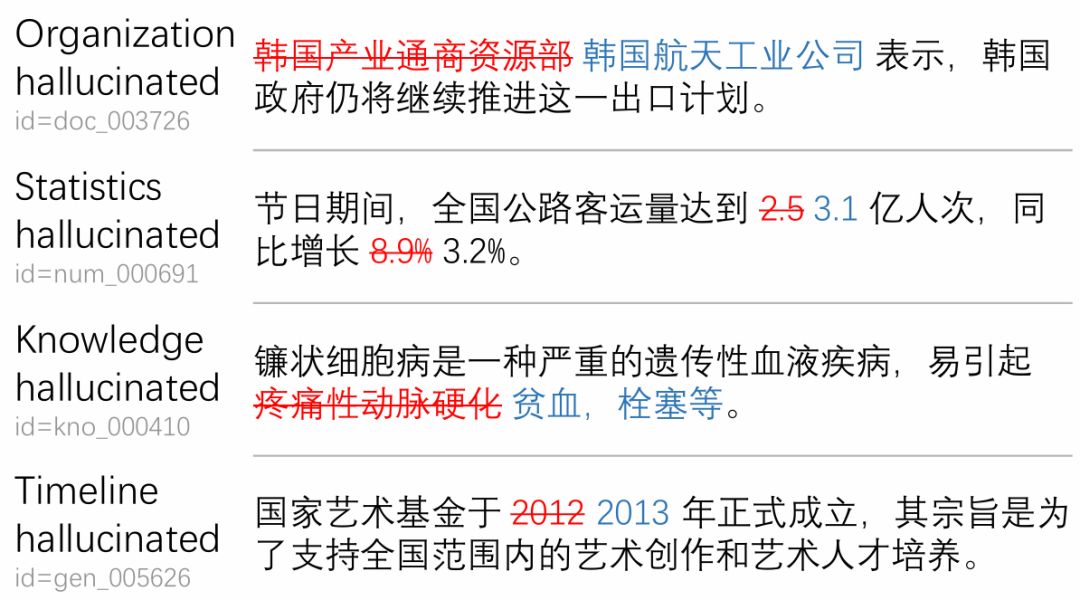
图1 一些用LLM生成新闻续写时出现的幻觉
为了有效控制幻觉,提出可信的模型固然重要,但是在那之前提出一个统一的,严格的基准同样有深远的意义。缺少这样的基准,该领域的工作则难以横向对比,良性发展。目前已经有一些比较知名的评测幻觉的基准,比如,TruthfulQA,HaluEval,HaDes等;然而这些数据集有一个严峻的问题,他们生成的评测数据集是有约束的,其评测无法反应真实的情况!下面以这三个基准为例,简单分析。还有更多相关工作,可以参考作者的总结,见图2.
注:现有的幻觉评测比较依赖于多项选择题形式,即让LLM从一些选项中选择问题Q的答案,因此大多数评测数据集需要收集正确的选项和错误的选项。
TruthfulQA:这个数据集在制作错误的选项的时候,作者明确在附录C中说到“我们直接从维基百科(或列出的来源)获取一组真实答案。然后,我们尝试覆盖这个答案的常见变体... 对于生成错误答案,我们遵循类似的过程,但通过针对[X相关的常见误解/迷信/阴谋论]进行网络搜索来扩大答案集…”。这意味着错误的/有幻觉的答案不是模型自己生成的!
HaluEval:它提示LLM让LLM生成参考选项,其中会用到的提示语例如“你在尝试回答一个问题时,误解了问题的背景和意图。”这样的导向是正确的吗?毕竟在真实的使用场景下,没有用户会提出这样的要求。
HaDes:这个数据集是让LLM识别出一句话中的幻觉词。然而,它在生成含有幻觉词的文本的时候却通过“随机扰动”的方法,即随机改掉一句话中的某些词,让它成为幻觉词。
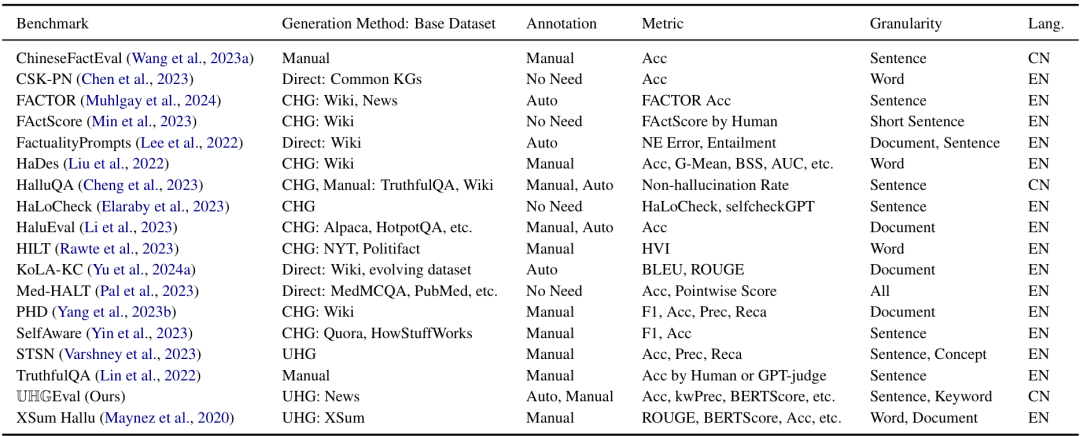
图2 相关工作总结
除了约束性问题,现有的工作大多聚焦在英语幻觉问题的评估上,忽视了中文NLP社区的需要。据论文所述,唯二的两项中文领域的工作,复旦大学的HalluQA和上海交通大学的ChineseFactEval才分别只有450条,和125条数据项,数据量过小,并且均是有约束的。
面临上述问题,中国人民大学,上海算法创新研究院,以及新华社媒体融合生产技术与系统国家重点实验室联合推出了UHGEval,一个包含5000+数据项的,且无约束的幻觉评测基准。

UHGEval: Benchmarking the Hallucination of Chinese Large Language Models via Unconstrained Generation
论文地址:https://arxiv.org/abs/2311.15296
项目地址:https://iaar-shanghai.github.io/UHGEval/
出版物:ACL 2024
此外,有意思的是,UHGEval这篇文章之后,卡耐基梅隆大学的研究者也关注到了约束性问题,发表了《HaluEval-Wild: Evaluating Hallucinations of Language Models in the Wild》,这篇工作也强调了无约束的在真实世界的评测的重要性,并引用了UHGEval。尽管这是个关注无约束问题的优质工作,但是仍然聚焦英文数据集,中文数据集仍然缺少。
AITIME
02
基准数据集构造
UHGEval简单的思路是说,让LLM进行无约束自由的续写,然后由GPT-4和人工联合标注出有问题的部分作为有幻觉的文本。接着让待评测LLM去判断这些幻觉的存在与否。数据集的生成主要由四个步骤构成(如图3的步骤1到4)。
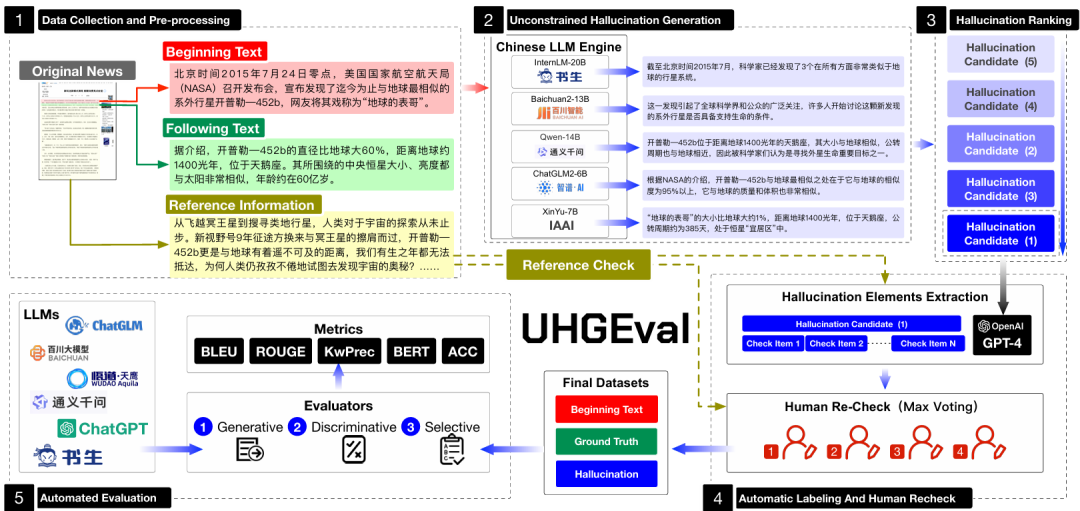
图 3 UHGEval基准的制作流程
步骤一:数据收集和预处理。该阶段使用数万条来自中文权威新闻网站,新华网的原始新闻作为数据集来源,并将其分为开头部分,续文部分以及参考信息。开头部分被用作待续写的文本,续文部分是续写的正样例,参考信息被用来视作后续标注和评估的参考。该阶段同时还包括新闻类别的细分方案和数据筛选过程。
步骤二:无约束幻觉生成。生成内容是作者工作最大的特色。与其他同类工作不同,UHGEval一方面使用5个LLM同时生成多个候选幻觉续写,以提高幻觉的多样性,避免单模型造成的评测偏见;另一方面,在具体生成文本时,不约束生成内容一定包含幻觉,也不指定生成幻觉类型,而让模型自由生成,在后续标注阶段再确定是否真正有幻觉,有幻觉就标注出来,没有就扔掉。具体来说,生成内容时,模型提示词减少指令以至于不适用指令,而直接将待续写的开头部分输给大模型,以得到最后的候选续写。如此一来,这两方面共同构成了模型和提示无约束的候选幻觉生成。
步骤三:续写排名。对于前面生成的5个候选幻觉文本,UHGEval从文本流畅性和幻觉发生可能性两个维度进行排名。之所以要进行排名是因为目标候选幻觉文本应当满足”看起来很像真的(流畅性高)而实则存在幻觉(幻觉发生可能性高)“的特征。UHGEval使用自研的奖励模型(reward model)来评价续写的流畅性,使用提出的kwPrec指标来评价续写发生幻觉的可能性。通过排名,最终会筛选出一个较为流畅,同时较为可能发生幻觉的目标候选续写文本。
步骤四:自动标注和人工复检。有了高达上万条的候选续写文本,为了筛选出真正存在幻觉的文本,UHGEval提出了基于关键词的标注方案。在该阶段由GPT4进行关键词粒度的标注(关键词是否存在幻觉,若存在原因是什么),由人工判断GPT4标注的是否准确,最终只保留人工认为GPT4标注准确且存在幻觉关键词的续写文本,以构成最终数据集。这样的标注方案实现了成本和标注准确性上的平衡。
这样下来,就得到总计5000+数据项的数据集,一个示例的数据样例如图4所示。其中,realContinuation和hallucinatedContinuation分别是没有幻觉和有幻觉的续写。对于有幻觉的续写,allKeywords还提供了幻觉词的标注和错误原因。

图4 一个实例数据
AITIME
03
实验
实验设置。作者对GPT3.5-Turbo,GPT4-0613,GPT4-1106,ChatGLM2-6B,Xinyu-7B,Xinyu2-70B,InternLM-20B,Baichuan2-13B,Baichuan2-53B,Qwen14B,Aquila2-34B共计11个模型进行了评测。对这些模型进行了生成式评测(根据开头自由续写,评价续写和参考信息的关联性),判别式评测(提供正确续写,或幻觉续写,让LLM判断是否存在幻觉),和选择式评测(同时提供正确续写和幻觉续写,让LLM选择正确的文本)。
实验框架。为了实现多种形式,多种模型下,大规模的评测,作者提出了一个完整的且能保证实验数据安全,便于拓展,且易于使用的评测框架,方便其他人使用(该框架目前还提供支持能够进行TruthfulQA,HaluEval,HalluQA等基准的评测)。框架包括依赖层,评测器层,核心层和界面层四层,如图5所示。
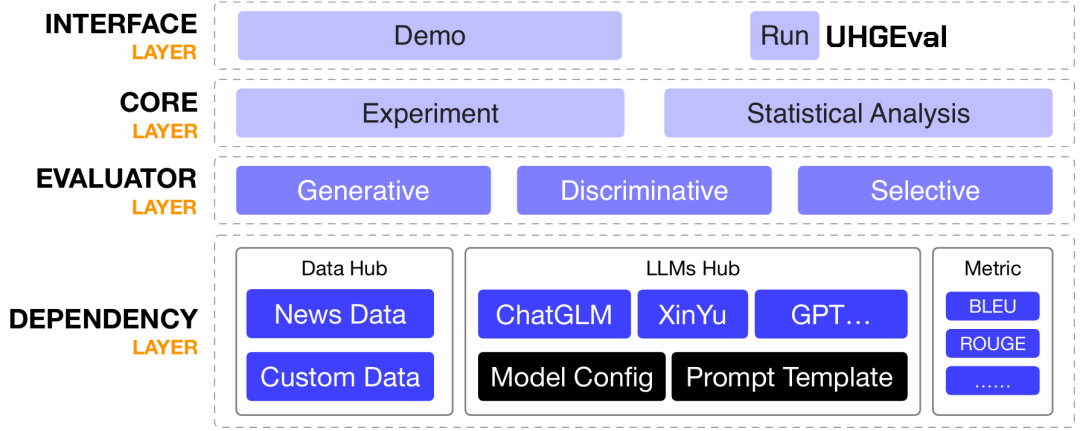
图5 评测框架
结果分析。文章从三个不同的评测器,对11个大模型展开了详尽的实验分析,一些结果如图6所示。文中提到的观点例如,“领域模型能够在特定场景胜过通用模型”,“GPT系列模型的确存在跷跷板效应”,“基于关键词的幻觉检测比基于句子的幻觉检测更可靠”等。此外,文章还讨论了各种评测器的难易度,优缺点,适用场景等。
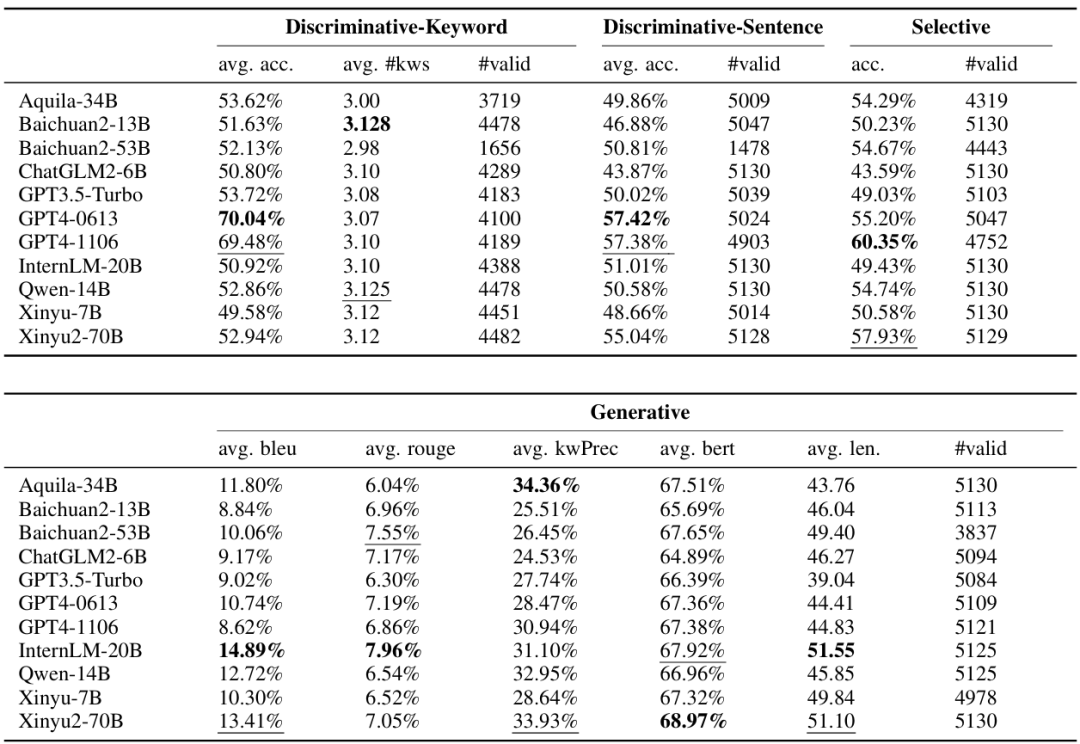
图6 评测结果
AITIME
04
总结
这份工作是一个非常有价值的Resource工作,对促进中文NLP的发展非常有益。中文NLP的建设亟需AI学者的共同建设,近来中文社区提出的一些大模型也开始在国际社区中崭露头角,像UHGEval的工作需要越来越多。
往期精彩文章推荐
记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1800多位海内外讲者,举办了逾600场活动,超700万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 观看作者直播讲解回放!


















 5
5

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









