






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
 点击 阅读原文 观看作者视频讲解!
点击 阅读原文 观看作者视频讲解!
ECCV'24公布的中稿结果中,本届共有2395篇文章被接收,录用率低于20%。由清华大学、无问芯穹、微软、加州大学圣芭芭拉分校和上海交通大学研究团队合作的《MixDQ: Memory-Efficient Few-Step Text-to-Image Diffusion Models with Metric-Decoupled Mixed Precision Quantization》中稿!

MixDQ:一种面向少步扩散模型的混合比特量化方案。
MixDQ分析定位了“少步扩散模型量化”的独特问题,并提出针对性解决方案。
针对少步生成模型,在现有量化方案在W8A8损失严重的情况下,MixDQ在能够实现多方面指标(图像质量,文图吻合,人为偏好)无损的W8A8量化,W4A8无明显视觉损失。
实现了高效的INT8 GPU算子,以实现实际的显存与延迟优化,并将模型开源为Huggingface Pipeline,通过几行代码即可调用。

图注:《MixDQ: Memory-Efficient Few-Step Text-to-Image Diffusion Models with Metric-Decoupled Mixed Precision Quantization》(简称MixDQ)
论文标题:MixDQ: Memory-Efficient Few-Step Text-to-Image Diffusion Models with Metric-Decoupled Mixed Precision Quantization
论文链接:https://arxiv.org/abs/2405.17873
Project page: https://a-suozhang.xyz/mixdq.github.io/
Huggingface Pipeline: https://huggingface.co/nics-efc/MixDQ

图注:《MixDQ: Memory-Efficient Few-Step Text-to-Image Diffusion Models with Metric-Decoupled Mixed Precision Quantization》(简称MixDQ)
引言
近年来,扩散模型(Diffusion Model)在视觉生成领域取得了显著的进展,Stable Diffusion模型能够依据文本信息生成高度拟真且美观的图像,“AI绘图”也在各领域成为了热门话题。然而,由于文生图大模型具有巨大的参数规模(Stable Diffusion XL: 3.5B, 35亿参数)与扩散模型循环迭代式的推理特点(单次生成图片需要对大模型进行数十次推理),其运行的硬件资源消耗十分巨大,对其实际应用带来了巨大挑战。
在扩散模型效率优化的算法研究中,“少步数”生成模型近期成为热点研究话题,通过减少扩散模型中的迭代步数,以减少计算代价,可实现相较原本方法十余倍的延迟加速。LCM[1] 首先实现2~8步的图像生成,SDXL-turbo[2] 模型更是将生成步数减少到了单步。少步数生成模型,解决了模型的延迟痛点,目前在RTX3090上推理一次单步生成模型仅需要不到1s,但是,模型的显存开销仍然显著。SDXL模型生成单张图片所需要的显存为约9GB(FP16模式,采用FlashAttention),超过了许多桌面级GPU的显存容量(如RTX4070,8GB)。

图注:SDXL模型生成单张图片所需显存超出桌面级GPU显存容量
低比特量化是一种被广泛使用的减少模型计算存储开销的方法,通过将原本高精度浮点(FP32/FP16)的模型全权重与激活值 (Weight and Activation, 简称W&A),转化为低比特定点数(INT8/INT4),可以显著减少模型显存开销与计算复杂度。为解决扩散模型的显存瓶颈,来自清华大学电子工程系、无问芯穹、微软、加州大学圣芭芭拉分校和上海交通大学研究团队,提出了一种新颖的扩散模型低比特量化方法:《MixDQ: Memory-Efficient Few-Step Text-to-Image Diffusion Models with Metric-Decoupled Mixed Precision Quantization 》。这项工作中,研究人员分析了少步数生成模型低比特量化的挑战,并提出了一种面向少步扩散模型的混合比特自动化设计方案:MixDQ,在现有量化方案在W8A8失败的情况下,实现了无损的W5A8量化。将扩散模型中U-Net的显存开销降低3.4倍,端到端延迟提速约1.5x,让文生图大模型“更小更快”,能够在各种小存储终端设备上被应用起来。

少步数扩散模型显著减少了迭代步数,提升了执行效率。然而,这也使得它对量化更加敏感。如下图所示,应用同样的基线量化方案Q-Diffusion,30步的SDXL模型在能够生成正常的图片,然而针对更少步的SDXL-turbo,图片视觉效果损失明显,在1步时图像更是变得模糊且扭曲,有时还会出现完全崩溃的情况(如下图中带粉色噪声的北极熊)。因此,针对少步数扩散模型设计量化方法更具挑战。除了图像质量的损失之外,文生图任务的另一重要评估指标为“文图吻合度”,即生成的图像是否如实的遵从了文本描述。如下图,量化后模型产生的图片都产生了与全精度模型较大的差异,有时甚至会完全违背文本描述。这指出了,当前文生图模型量化方法对文图吻合度的保持有待改进。

图注:量化后模型生成的图片与全精度模型、文本描述的差异
本文对少步模型量化失败的原因进行了系统实验分析,并得到了以下结论:
(1)神经网络模型中不同层的量化敏感性存在着高度差异,量化实际上被少部分“极端敏感”的层所瓶颈。
(2)现有的量化敏感性分析方法,未区分量化对“图像质量”与“图像内容”,而导致准确度不足。
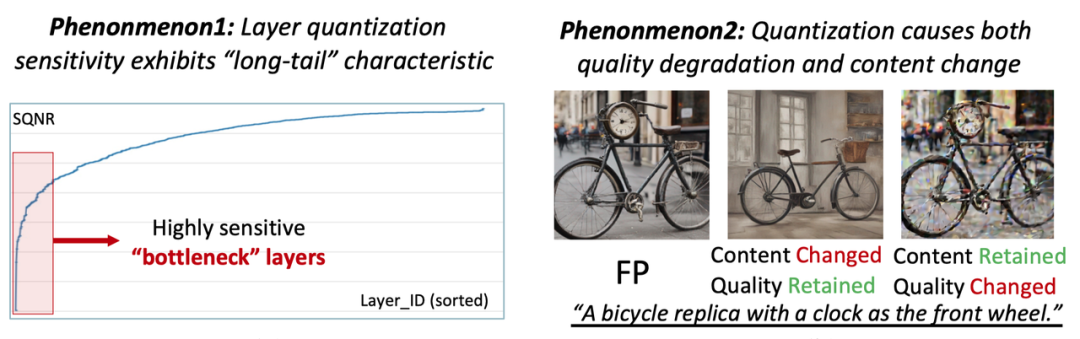
图注:量化过程中的两个现象
受上述观察所启发,本文提出采用混合精度量化以解决“量化被少数极端敏感层所瓶颈”的问题,通过给这些特定层赋予更高的位宽,可以在保持量化性能的前提下,实现模型其他部分的低比特量化,获得硬件资源节省。
针对“如何准确识别出量化敏感层”的问题:
(1)本文考虑了现有方案对量化敏感性估计的不足,并提出了一种“指标解耦”的方案,来分别对量化对图像质量与内容的影响进行分析,以准确得到量化的敏感性。
(2)将混合比特位宽的分配定义为了一个整数规划问题,并高效自动化完成求解。
(3)针对特别敏感的文本特征量化,本文识别出了量化被“句首令牌”(Begin-of-Sentence Token)离群值所影响的关键问题,并提出了一种BOS-aware的量化方案,有效解决了该问题。
采用以上方案,MixDQ可以在几乎无损的情况下实现W5A8的量化,可获得约3.4x的显存优化,与1.5x的延迟优化。
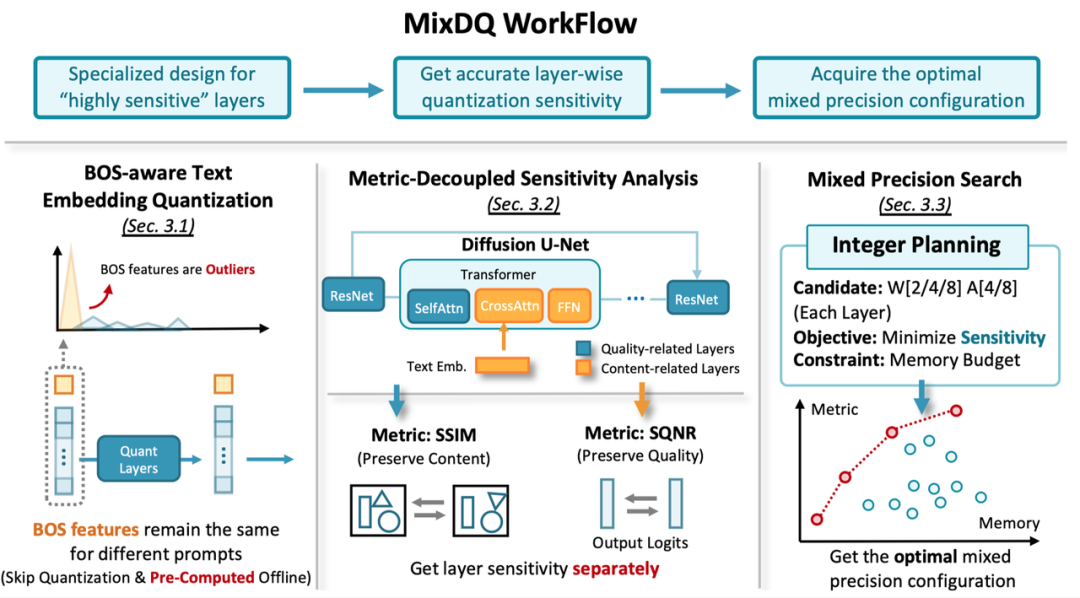
图注:MixDQ工作流程

为了在具体硬件上验证MixDQ量化方案的实际效率优化,针对Nvidia GPU,基于CUTLASS库开发了低比特量化算子,实现了SDXL-turbo量化模型的端到端推理。经过GPU实测,在多种量化位宽配置方案下,MixDQ能获得显著的显存与延迟优化结果。优化后的MixDQ-SDXL-turbo模型已封装为Huggingface Pipeline,以供用户一键实例化并调用。

图注:MixDQ-SDXL-turbo模型封装及调用展示
具体来说,如下图所示,MixDQ的4/8比特权重量化,可实现1.87x与3.03x的权重显存占用量优化,原本需要5.2GB存储的SDXL模型权重,经过W4优化后仅需不足2G,整个推理流程的显存占用也从8GB减少至4.5GB。当权重与激活值均被量化至INT8时,针对可量化层,MixDQ的高效量化算子实现,相比FP16版本能获得1.97x的延迟加速,考虑量化与反量化操作的额外开销,仍能获得1.45x的端到端延迟优化。INT4的量化算子仍在开发中,预期可获得更高的端到端延迟优化。
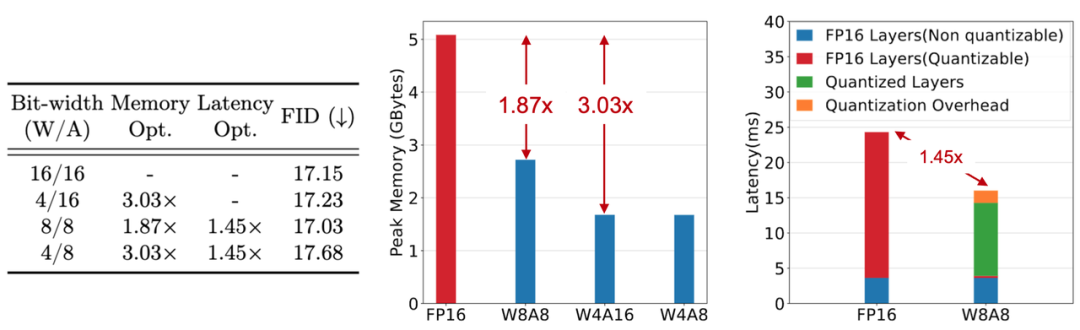
图注:MixDQ在不同比特宽度配置对内存和延迟的影响
对比现有的其他部署优化工具的量化加速方案,MixDQ是第一个实现了少步数生成模型的量化实际显存与延迟优化的方案,且保持了生成效果与FP16几乎完全一致。其余现有方案除Nvidia未开源的TensorRT量化方案外,均不能实现延迟加速,或造成明显生成质量劣化。Nvidia方案所采用的Q-Diffusion算法方案,如上文所述,在应用到少步生成时会带来明显的性能损失,因此并不能直接兼容少步生成。
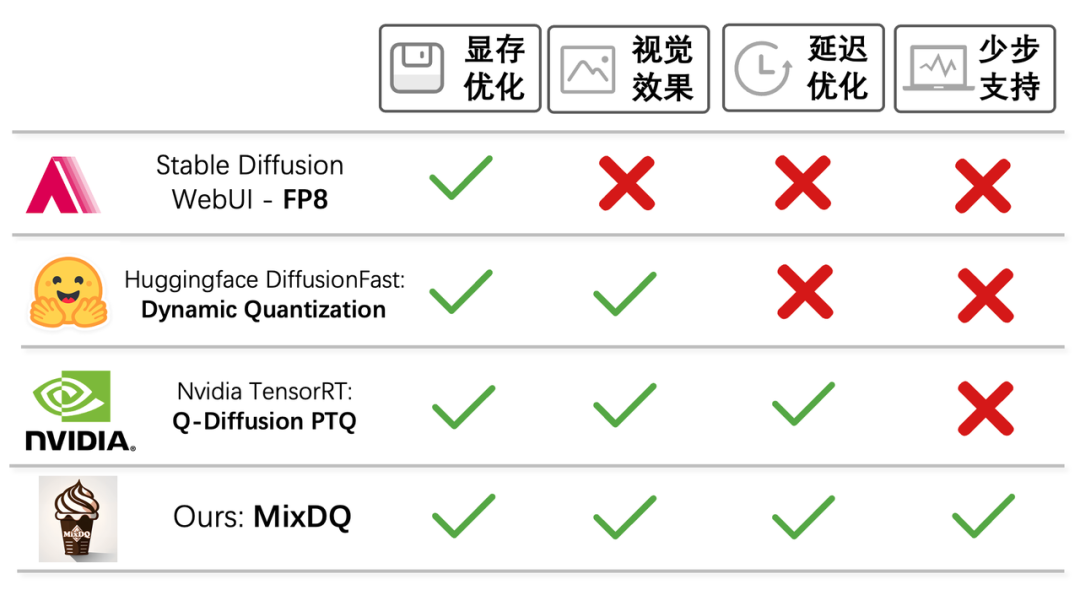
图注:MixDQ与其他部署优化工具的量化加速方案对比
此外,模型的低比特量化利用了模型数值精度上的冗余性(FP->INT),与大多数其他维度算法与部署优化方案正交。低比特量化优化方法具有较高的兼容性与可拓展性,可以和其他优化方案组合使用(如算法侧模型架构优化,部署侧的算子与计算图优化方案,如Stable-fast,OneDiffusion等等),以获得更好的效率优化。

低比特量化采用了更低的数据位宽,相比浮点模型存在着计算误差。为了验证量化后模型的生成效果,本文采取了多种不同的评估指标,从不同方面验证了MixDQ量化模型生成结果与浮点模型的一致性。FID(Fréchet inception distance)衡量了两组图片在特征空间的距离,是验证图像生成模型图片“保真度”(Fidelity,即图像质量)的常用指标。CLIPScore(CLIP)常被用于衡量文生图模型的“文图吻合性”。ImageReward(IR)则是采集了大规模人类的真实判断训练而成的,涵盖多角度的图像质量预测器。如下表所示,MixDQ在W8A8时获得了比FP16可比甚至更好的生成质量,在W5A8时,仅损失了0.1的FID,0.0025的CLIPScore,0.03的ImageReward。显著的优于基线方案,在W8A8时已经基本失效。
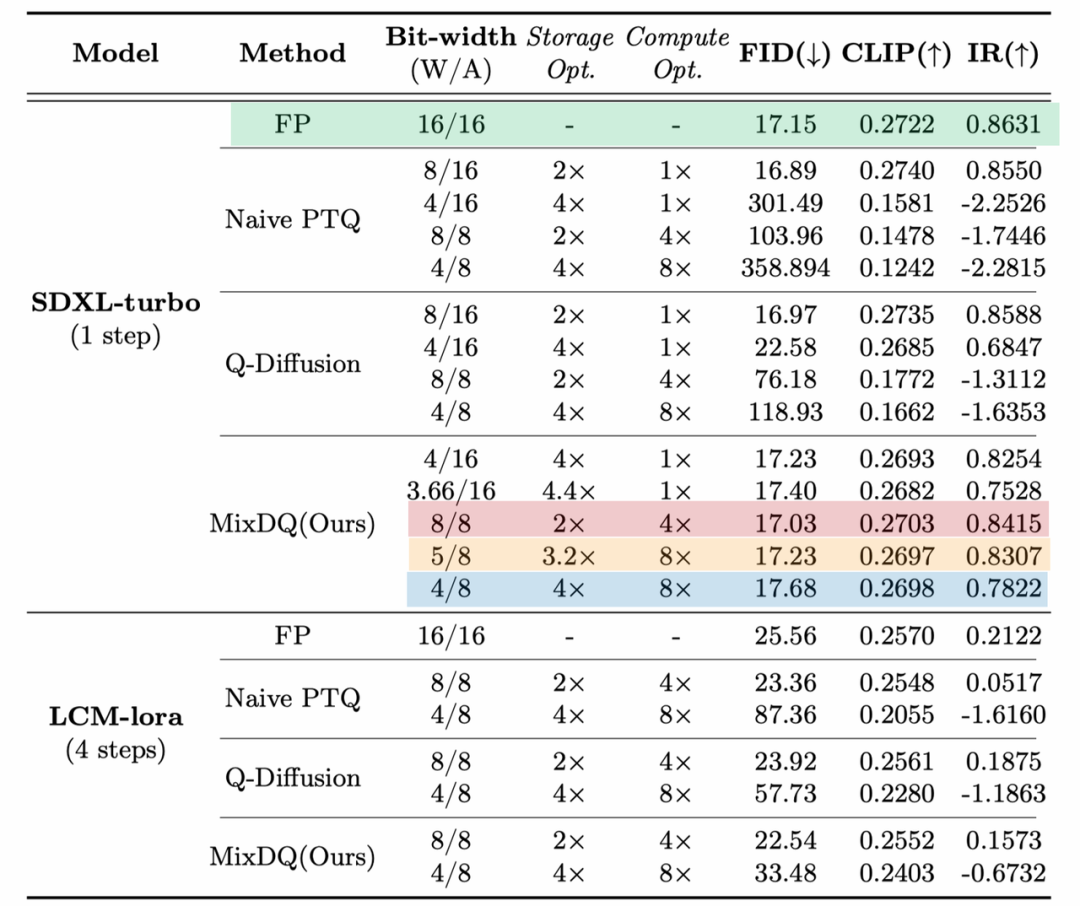
图注:使用不同评估指标验证MixDQ量化模型与浮点模型的一致性
下图具体的展示了定量指标与视觉效果之间的关联性,可以看到MixDQ-W4A8所生成的图片视觉上与FP模型无显著区别,而基线方案(Q-Diffusion,MinMax)在W8A8时已经出现了较为明显的视觉效果劣化,FID也显著增加(FID越低越好,W8A8 Q-Diffusion FID增加60,W4A8 MixDQ FID仅增加1)。
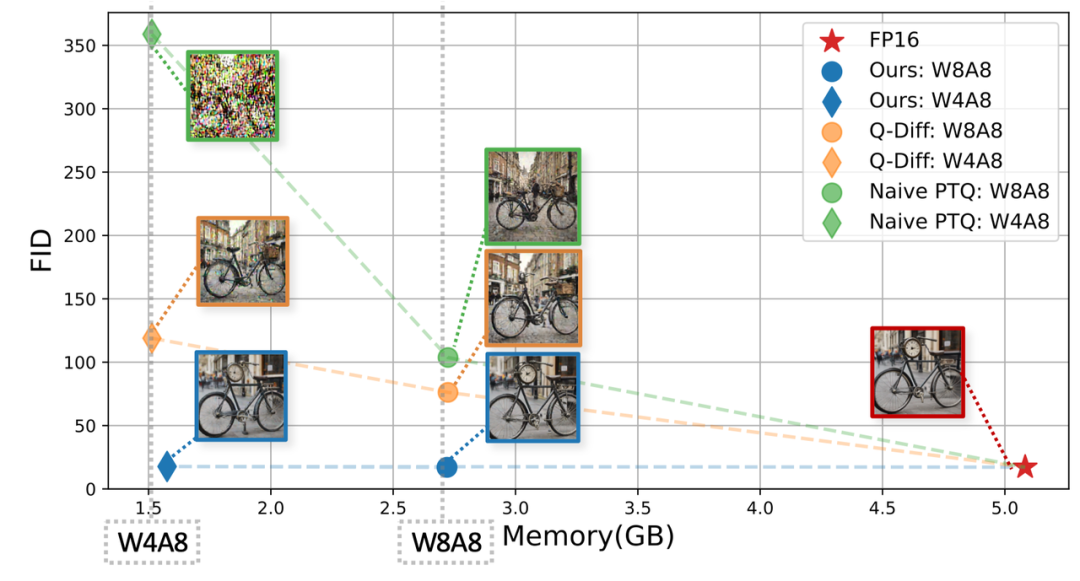
图注:定量指标与视觉效果之间的关联性
各种量化方案的生成结果展示如下,如下图所示,基线量化方法不仅造成了明显的视觉效果劣化(模糊,噪点),还造成了生成内容的大幅度变化。在大部分例子中,变化之后的图像内容已经不能符合文本的描述,造成“文图吻合度”的显著降低。而MixDQ W4A8之后的结果,仍然和全精度方案的图像基本一致,人眼难以分辨其差异。

图注:各种量化方案生成结果展示
总结与未来指引
本文提出了MixDQ,一种面向文生图扩散模型的混合比特低比特量化方案。本文分析并识别出了少步数扩散模型量化失败的关键问题,并且提出了“指标解耦”的量化敏感性分析与位宽分配方案。能够在保持生成质量的前提下,显著减少模型的计算与存储消耗。论文通过敏感度分析,提供了基于U-Net的Stable Diffusion文生图模型各类层较准确敏感性,可指引后续低比特量化方法设计。此外,本文所提出的“指标解耦”的分析思想也可被广泛应用于除低比特量化之外的扩散模型设计中。

[1] Luo, Simian, et al. "Latent consistency models: Synthesizing high-resolution images with few-step inference." arXiv preprint arXiv:2310.04378 (2023).
[2] Sauer, Axel, et al. "Adversarial diffusion distillation." arXiv preprint arXiv:2311.17042 (2023).
往期精彩文章推荐

关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾700场活动,超800万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 观看作者视频讲解!
















 67
67

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









