






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

点击 阅读原文 观看作者讲解回放!
个人信息
作者:刘瑷玮,清华大学博士生
内容简介
文本水印技术在检测大型语言模型(LLM)输出以及防止其滥用方面取得了显著进展。当前的水印技术具有高可检测性、对文本质量影响小以及对文本编辑具有鲁棒性等特点。然而,目前的研究缺乏对LLM服务中水印技术不可感知性的探讨。这一点至关重要,因为LLM提供商可能不希望在现实场景中透露水印的存在,因为这可能会降低用户使用服务的意愿,并使水印更容易受到攻击。
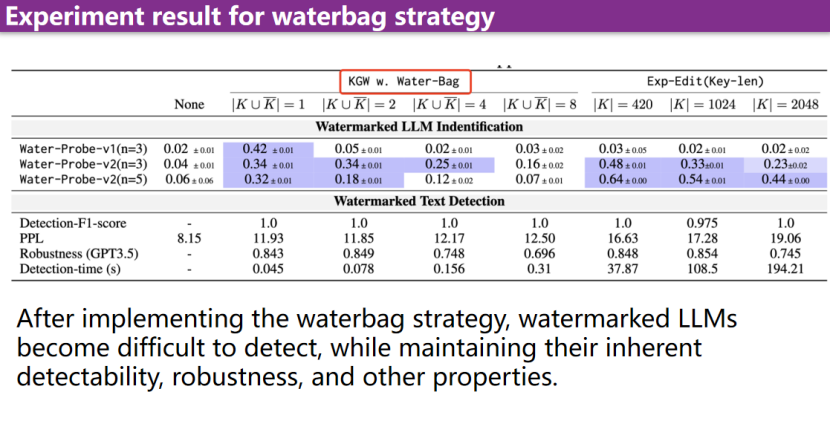
本研究调查了水印LLM的不可感知性。我们设计了一种名为Water-Probe的统一识别方法,通过精心设计的提示来识别LLM中的各种水印。我们的主要动机是,当前的水印LLM在相同的水印密钥下会暴露出一致的偏差,导致在不同水印密钥下提示之间的差异呈现出相似性。实验表明,几乎所有的主流水印算法都可以通过我们精心设计的提示轻松识别,而Water-Probe对非水印LLM的误报率极低。最后,我们提出,增强水印LLM不可感知性的关键在于增加水印密钥选择的随机性。基于此,我们引入了Water-Bag策略,通过合并多个水印密钥,显著提高了水印的不可感知性。
论文地址:
https://github.com/THU-BPM/Watermarked_LLM_Identification
Background Watermark For LLMs
当前,大模型能够迅速生成大量文本,但这种能力也可能带来负面影响,例如快速生成虚假新闻和有害信息。在此背景下,本文希望对通过大模型生成的文本进行检测和追踪。为了应对这一挑战,有两种主要的检测方法:主动水印检测和被动生成后检测 。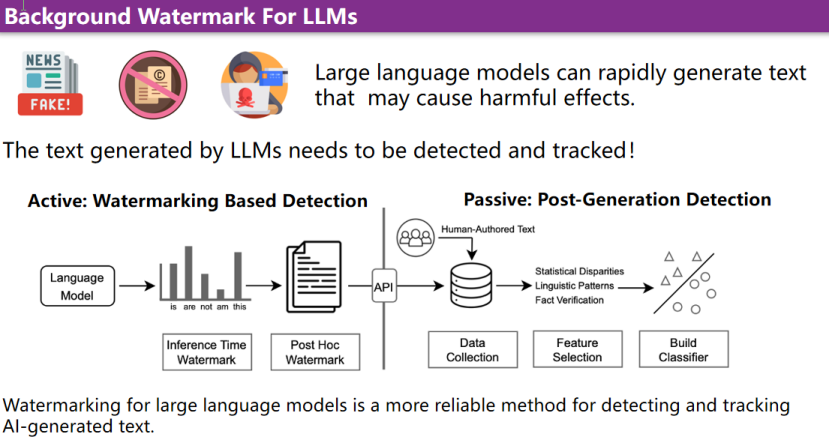
主动水印检测方法在生成过程中,通过在文本中嵌入特定的可检测特征来标记AI生成的内容,这种方法更可靠且高效。水印可以在推理时添加,也可以在生成后进行处理。
相比之下,被动检测方法则是在生成后通过统计差异、语言模式分析和事实验证等方式进行识别,这种方式虽然也可行,但相对于水印检测来说可靠性较低。综上分析,目前的主流检测方式是主动的文本水印方法。
水印文本的使用实际上有着悠久的历史。其起源可以追溯到古希腊时期,当时有对文本进行水印的研究。然而,在大模型出现之前,更多采用的是format base方法,例如嵌入Unicode特征、修改词汇和语法结构来实现水印。自2022年以来,由于大模型的兴起,水印技术也迎来了文艺复兴。在此之前的水印处理主要是提供一份文本,对其进行修改并加入水印。但随着大模型的出现,人们更倾向于直接让模型生成的文本本身就带有水印,而不是先生成文本然后再做修改。

What is an LLM Text Watermarking
目前,存在一系列方法。当前主要的方法焦点集中在修改模型前的逻辑,或者修改生成下一个token的方式上。水印生成分为两个阶段。首先,通过提供一个水印的key和一个输入,可以生成一个带有水印的文本。其次,在检测阶段,仅需提供一个key和待检测的文本,即可判断该文本是否有水印。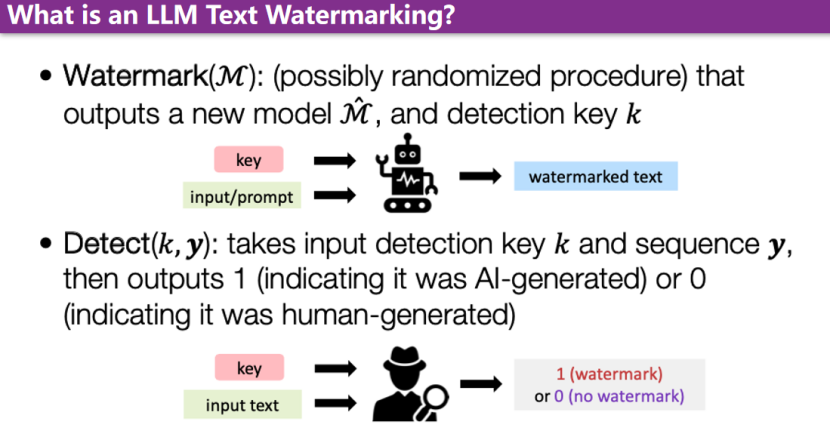
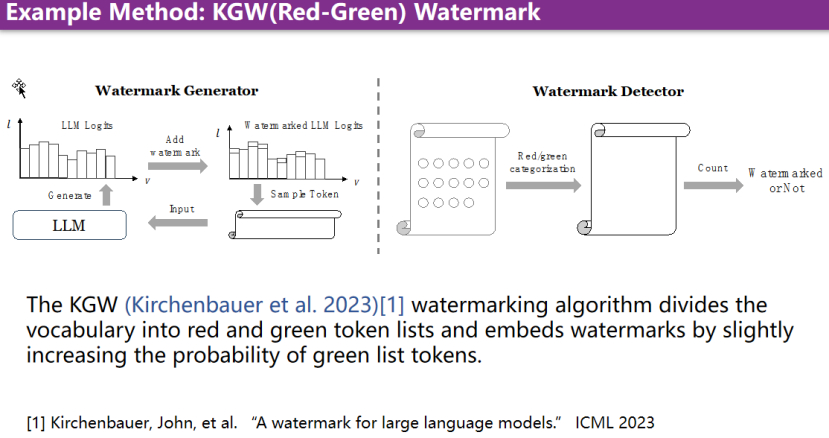
KGW(Red-Green) Watermark
KGW(Red-Green)算法的基本逻辑在于,在生成针对大模型生成的下一个词表的分布时,会更加强调绿色词。具体做法是将词表分为红色词表和绿色词表,并简单地增加绿色词表中词的概率。这样,采样出来的词中绿色词的数量就会更多。因此,在后续的检测过程中,只需要判断绿色词是否在统计意义上大于红色词,就可以判断文本是否含有水印。
N-gram watermarking
但是,绿色词表具体如何生成?实际上有两种途径,这引出了两类的水印范式。一种如之前所述的算法,是基于N-gram的水印技术。N-gram基于之前N个token的生成进行哈希,进而决定划分方式。

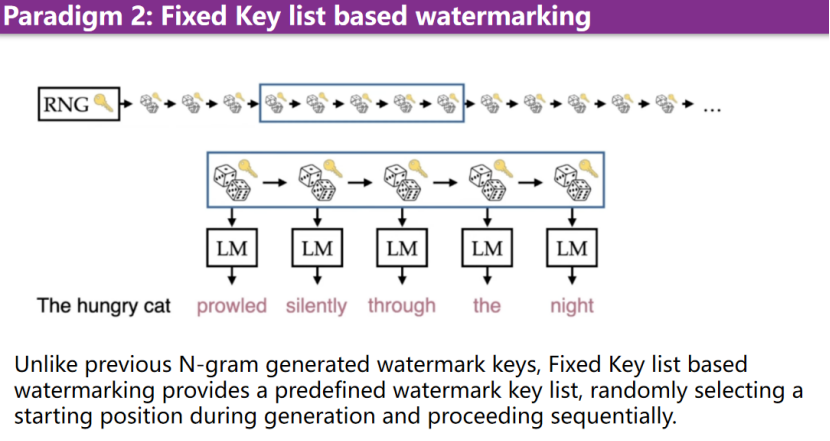
Fixed Key list based watermarking
此外,还有其他的范式。例如基于fixed key list的水印生成。这意味着,水印并非完全依赖于之前的N gram模型。存在一个fixed key list,在每次生成水印时,会随机选择一个starting line,并通过这种方式生成水印。
但这会带来一个新的问题,即当前的大模型被加入各种形式的水印。那么,作为用户,是否可以通过一个黑盒的方式,通过构造特定的prompt来验证大模型是否携带某种水印。
Our Contribution: WaterProbe Method to Identify Watermarked LLMs
本文的核心贡献在于通过设计一种算法,使其能够通过用户设计的与当前流行prompt交互的策略或流程,从而准确地判断大型模型是否携带水印。具体来说,本文设计的方法主要通过模型持续重复使用相同的watermark key来生成输出,判断输出分布的偏移,来确定模型是否具有水印。关键问题转化为如何通过prompt设计实现使用相同水印的样本不断采样的效果。以下步骤详细介绍了构造过程的各个阶段。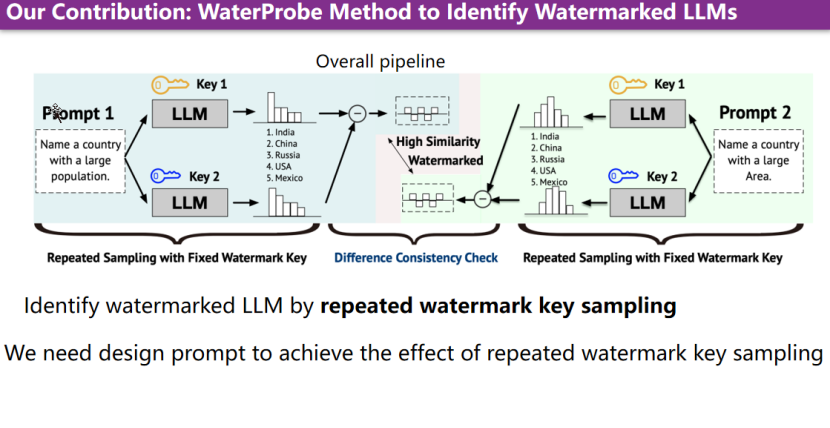 首先,构造一对高相关的prompt。这两个prompt的回复可能是相交的集合,但分布可能略有不同。针对N gram的形式,可以先生成一个固定的前缀,然后生成问题答案,通过比较答案在不同前缀下的偏移长度,来判断是否存在水印。
首先,构造一对高相关的prompt。这两个prompt的回复可能是相交的集合,但分布可能略有不同。针对N gram的形式,可以先生成一个固定的前缀,然后生成问题答案,通过比较答案在不同前缀下的偏移长度,来判断是否存在水印。

第二步,针对上述prompt,不断进行采样,可以采样上千次以获得统计分布。

第三步,在获得统计分布后,可以对前缀相同的水印进行相关性分析。前提需要有一个假设,在通常情况下,水印规则对结果的影响是符合连续性条件的。基于此假设,可以通过计算在不同水印的相同前缀对同一分布的影响是否一致,进而计算得出cosine相似度,并判断其是否大于某一阈值。如果认为大于某一个阈值,那么经过prompt检测,就可判定该大模型携带水印,该服务是带有水印的。上述介绍的方法主要是服务于N gram base的水印方法。一个更核心的挑战是,如何针对key list范式的水印进行构造和设计prompt方法。此处引入了Water-Prob-v2算法。


Experiment Result On Opensource LLMs
下图中展示了实验结果。Water-Probe-v1主要针对基于N-Gram的方法,效果非常好。但是该方法的缺点是,它无法检测Fixed-Key-List的方法。Water-Probe-v2方法针对不同的大模型,加入不同类型的水印,文中对这些方法进行了系统性的评估。结果表明,Water-Probe-v2方法能够针对所有大模型和目前所有的水印算法,取得非常优秀的检测效果。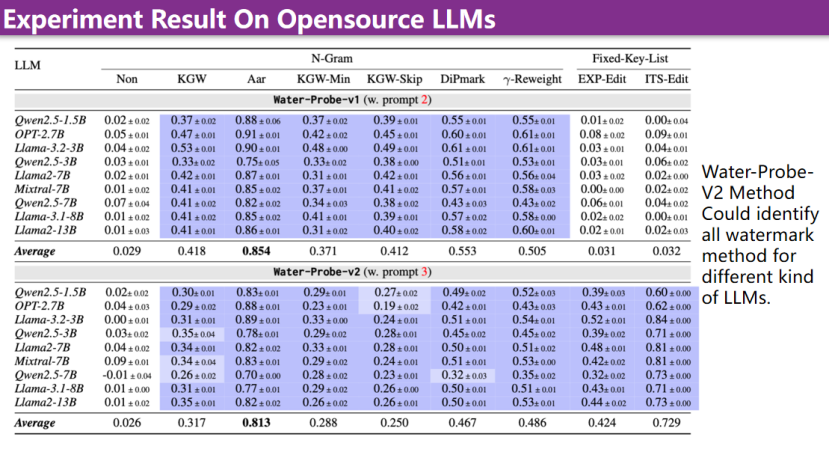
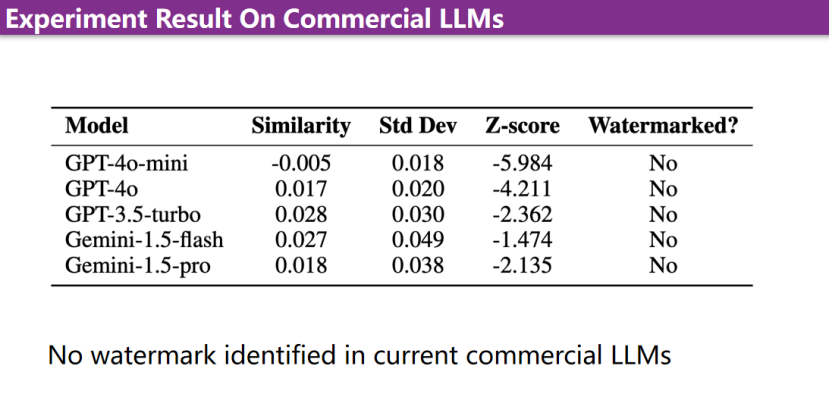
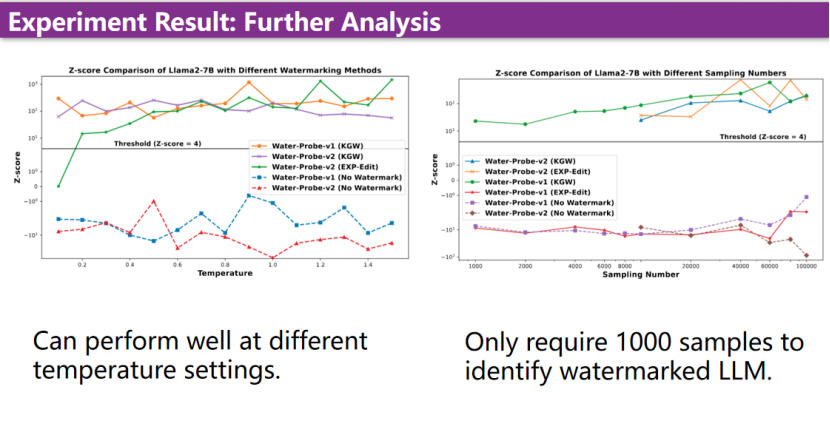

本期文章由陈研整理
近期精彩文章推荐

跨越边界,大模型如何助推科技与社会的完美结合?
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾700场活动,超800万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 观看作者讲解回放!


















 8
8

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









