










基础知识:知识图谱理论知识,RAG理论知识,docker工具使用,dify工具使用
本博客将以菜谱为例,用dify本地构建基于知识图谱的RAG系统的demo
1. 数据处理
1.1 数据收集
问大模型联网搜索,菜谱的数据集
请帮我找一个中国菜谱数据集下载链接,要求包含菜的名字,类别,口味,食材,烹饪过程。
找到合适的数据集,链接如下:
https://drive.google.com/file/d/1HDUHNDHUxKJilfKr3D_9lA7K_RtJ6ewY/view
1.2 数据处理
这里的数据处理的目的是从非结构化文本中提取结构化信息
数据集的格式样例如下,因为已经是json格式的结构化信息,就不需要过多的处理了。
{
'name': '酸甜鲜美,草莓虾仁', # 作者提供的标题
'dish': '草莓虾仁', # 映射到下厨房提供的菜品列表中的菜品名(如果无法映射,则该值为'Unknown')
'description': '草莓和虾仁放在一起,刚开始就为了好看,后来竟然发现味道也很棒~', # 作者提供的菜谱描述
'recipeIngredient': # 作者提供的原料表 ['100克草莓', '300克对虾', '15克青椒', '1个鸡蛋', '8克盐', '3克胡椒粉', '10克料酒', '10克玉米淀粉', '10克生姜', '1000ml(消耗量25ml)色拉油'],
'recipeInstructions': [ # 菜谱步骤 '草莓一分为四切块', '将对虾洗净去头去壳', '虾仁开背去除虾线', '虾仁用盐、味精、胡椒粉、鸡蛋清、湿淀粉腌制上浆入味', '净锅倒入色拉油加热至三成热', '虾仁入锅滑熟倒出沥油', '原锅留底油加适量清水,加入少许盐、味精、料酒,烧开后用少许湿淀粉勾玻璃芡汁,然后倒入虾仁、草莓翻拌均匀淋上少许明油即可出锅' ],
'author': 'author_2894', # 脱敏的作者名
'keywords': # 下厨房提供的关键词 ['草莓虾仁的做法', '草莓虾仁的家常做法', '草莓虾仁的详细做法', '草莓虾仁怎么做', '草莓虾仁的最正宗做法', '健康', '养生', '季节', '家宴']
}2. 知识图谱构建
2.1 工具准备
基于Neo4j图谱库演示,因此需要安装Neo4j软件。这里通过docker快速部署即可
# 默认启动
docker run -itd --name neo4j -p 7474:7474 -p 7687:7687 -v $HOME/neo4j/data:/data neo4j
# 开启apoc,以及支持文件导入功能的neo4j启动命令
docker run -itd --name neo4j -p 7474:7474 -p 7687:7687 -e NEO4J_dbms_memory_transaction_total_max=4G -e NEO4JLABS_PLUGINS='["apoc"]' -e NEO4J_apoc_import_file_enabled=true -e NEO4J_AUTH=neo4j/123qweasd! neo4j:latest命令运行完后,打开浏览器,访问http://localhost:7474,如果看到Neo4j的登录页面,说明安装成功。
如果没有指定密码的话,即没有NEO4J_AUTH的设置的话,默认用户名和密码都是neo4j,第一次登录后需要修改密码。
验证apoc是否安装成功
CALL apoc.help('');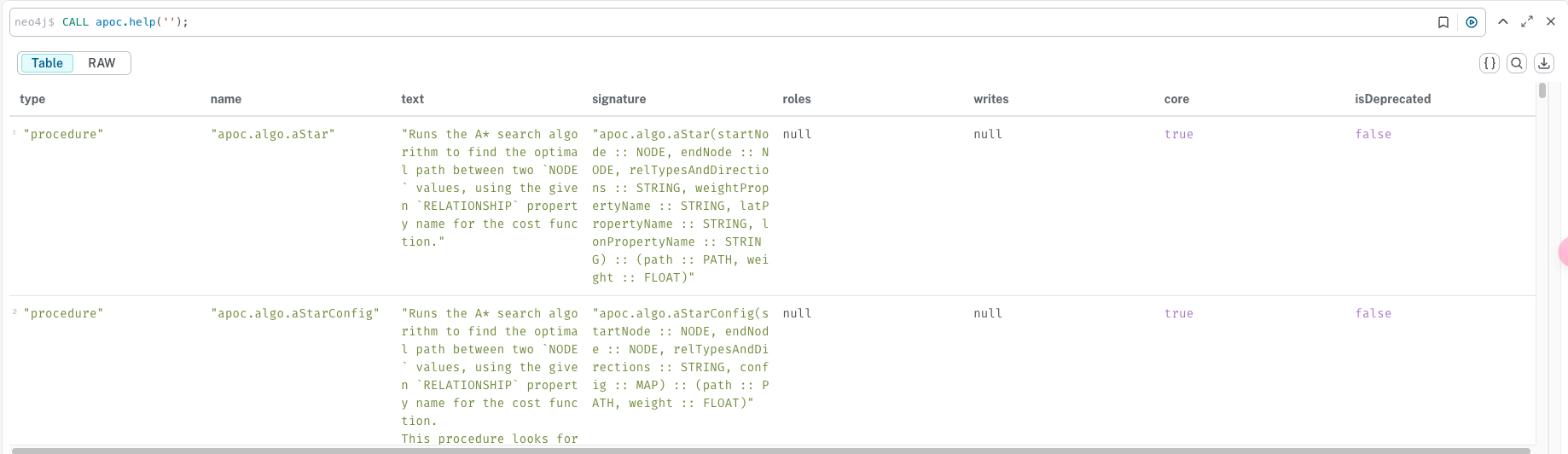
2.2 图谱库构建
本部分的工作:
-
创建图谱结构
-
数据入库
图谱的构建整体思路如下:
根据菜谱数据,定义以下核心实体(Node):
-
Recipe(菜谱) :主实体,包含菜谱的基本信息。
- 属性:
name(菜名,如“蛋炒饭”)。
- 属性:
-
Ingredient(原料) :菜谱中使用的食材。
- 属性:
name(原料名,如“鸡蛋”)。
- 属性:
-
Keyword(关键词) :用于分类或标签的关键词。
- 属性:
name(关键词名,如“炒饭”“家常菜”)。
- 属性:
定义实体之间的关系(Relationship):
-
Recipe → CONTAINS → Ingredient表示菜谱包含某个原料。
-
Recipe → BELONGS_TO → Keyword表示菜谱属于某个关键词分类。
# 需要将json文件放入容器内import目录下
docker cp Downloads/recipe_corpus.json neo4j:/var/lib/neo4j/import/recipe_corpus.json# 进入neo4j,执行加载JSON文件的Cypher语句
// 加载JSON数据并创建Recipe节点及基础属性
CALL apoc.load.json("file:///recipe_corpus.json") YIELD value
UNWIND value AS recipe
CREATE (r:Recipe {
name: recipe.name, // 菜名
dish: recipe.dish, // 菜品类型(如主菜/甜点)
description: recipe.description, // 菜品描述
author: recipe.author, // 作者
instructions: recipe.recipeInstructions // 制作步骤
})
WITH recipe, r // 传递上下文到下一部分
// 创建Ingredient节点并建立Recipe→CONTAINS→Ingredient关系
UNWIND recipe.recipeIngredient AS ingredient
MERGE (i:Ingredient {name: ingredient})
CREATE (r)-[:CONTAINS]->(i) // 关系方向修正为Recipe指向Ingredient
WITH recipe, r // 传递上下文到下一部分
// 创建Keyword节点并建立Recipe→BELONGS_TO→Keyword关系
UNWIND recipe.keywords AS keyword
MERGE (k:Keyword {name: keyword})
CREATE (r)-[:BELONGS_TO]->(k) // 关系方向修正为Recipe指向Keyword这里不用原始数据太大了,导入不进去。

入库操作后进行检查数据是否ok

MATCH (n) RETURN labels(n) AS NodeLabels, COUNT(*) AS NodeCount如果需要删除,可以参考以下语句
MATCH (n) DETACH DELETE n;通过http调用,后续dify主要也是通过http调用来访问neo4j
# http认证需要通过base64加密,然后将得到的结果粘贴到Authorization中
echo -n 'neo4j:123qweasd!' | base64
# 查询所有节点
curl -X POST \
http://localhost:7474/db/neo4j/tx/commit \
-H 'Authorization: Basic bmVvNGo6MTIzcXdlYXNkIQ==' \
-H 'Content-Type: application/json' \
-d '{
"statements": [{
"statement": "MATCH (n) RETURN n, labels(n) as labels",
"parameters": {}
}]
}'返回正确结果即可,如下图所示
3. 智能体构建
3.1 工具准备
dify的安装这里就不进行详细的介绍了
3.2 V1
3.2.1 构建方案
构建思路

构建效果
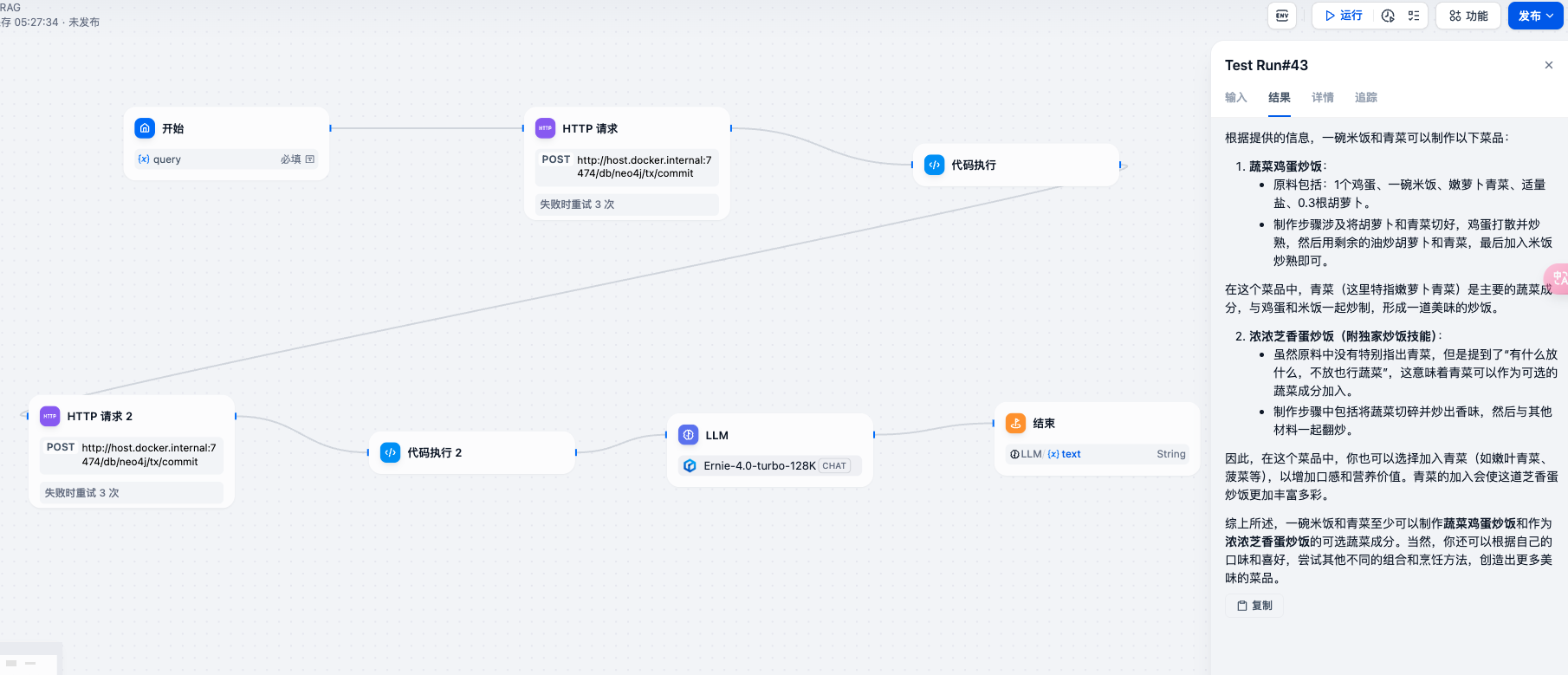
3.2.2 构建过程
dify导入以下yml文件即可使用,详见下载链接
https://download.csdn.net/download/AI_DL_ML_Dreamer/90555134
3.2.3 不足之处
可以新增文本库,结合知识图谱提取的信息,综合给大模型进行输出

















 1649
1649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









