



港中大(深圳)联合中科院声学所、上海人工智能实验室等机构发布了超过10万小时包含6种语言的多样化的语音生成数据集—— Emilia!更重要的是,Amphion直接开源了 Emilia-Pipe 数据预处理框架,学术界也能众筹数据了,也能玩大模型了! 🎉🎉🎉

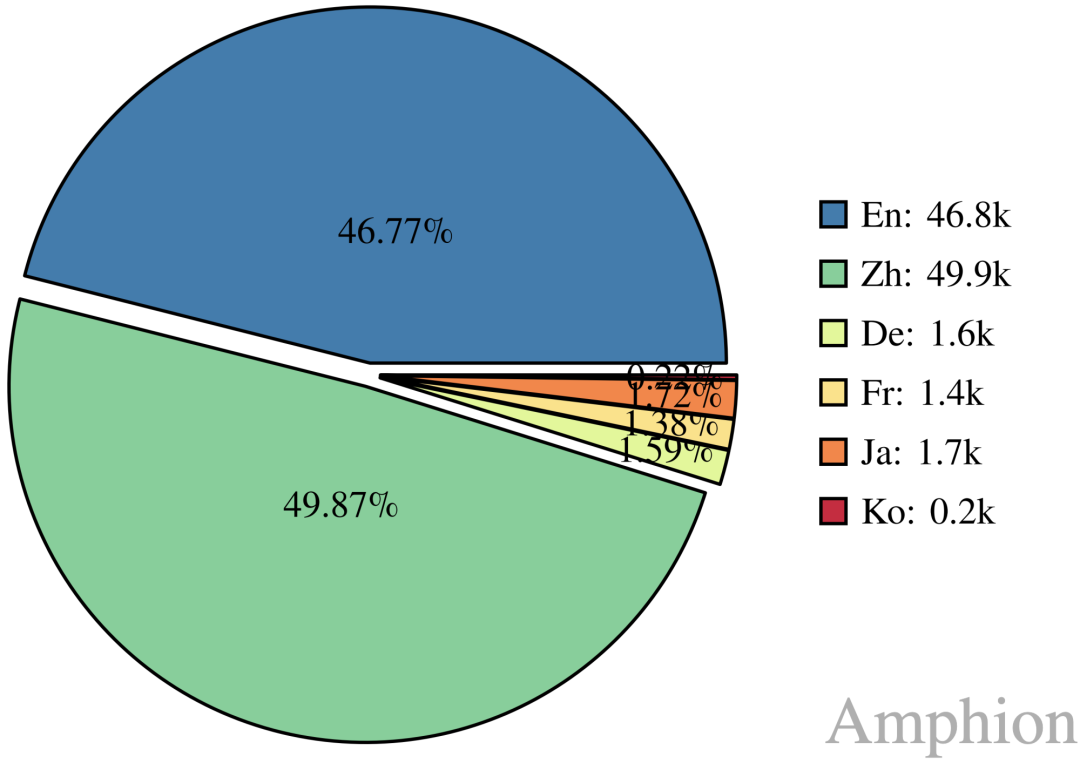
来仔细看看Emilia数据集吧。Emilia初始数据集包含超过十万小时、采样率为24kHz的语音数据,覆盖中文、英文、德语、法语、日语和韩语六种语言。该数据集以互联网中真实的自然(spontaneous)语音为主,涵盖了如脱口秀、访谈、辩论、体育解说和有声书等各种内容类型。这种多样性确保了数据集捕捉到广泛的真实人类说话风格。下面的图表展示了数据集中每种语言的时长统计。
相较于MLS、Libri-Light等有声书数据集,Emilia数据集在声学特征和语义覆盖方面更为丰富,如下图所示。

用Emilia训练语音生成大模型的话,效果会怎么样?🤔🤔 先听听基于Emilia数据集训练的语音合成TTS模型的生成效果,跟同样量级数据集训练的CosyVoice的生成效果对比,感受一下。
(Emilia Dataset + Amphion)-1,语音之家,9秒
Cosyvoice-1,语音之家,10秒

(Emilia Dataset + Amphion)-2,语音之家,19秒
Cosyvoice-2,语音之家,26秒
(Emilia Dataset + Amphion)-3,语音之家,11秒
CosyVoice-3,语音之家,13秒
(Emilia Dataset + Amphion)-4,语音之家,7秒
CosyVoice-4,语音之家,9秒

再看看Emilia 10万小时数据集训练的TTS系统跟SeedTTS、ChatTTS等开源和商业系统/模型的客观指标对比(其中测试数据来自SeedTTS官方测试集)。

目前,Emilia数据集和Emilia-Pipe预处理框架已经发布,详细信息可通过以下链接获取。
👇👇👇
📌 ArXiv: https://arxiv.org/abs/2407.05361
📌 GitHub: https://github.com/open-mmlab/Amphion/tree/main/preprocessors/Emilia
📌 Homepage: https://emilia-dataset.github.io/Emilia-Demo-Page/
📌 HuggingFace: https://huggingface.co/datasets/amphion/Emilia
目前该数据集是CC-BY-NC。想把该数据预处理框架用于商业用途或者获得该数据集或定制大规模数据集,赶快联系Amphion团队 joyeduan@cuhk.edu.cn 吧。

















 531
531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









