







在语音合成领域,'以假乱真’一直是技术攻关的终极目标。近日,字节豆包团队推出的Seed-TTS模型,凭借对人类语音的高精度复现(甚至能模仿发音瑕疵),在中文语音合成基准测评中以93.06分的成绩领跑行业。本文将介绍如何调用该模型,探讨其如何重新定义AI语音的边界。
1. 注册或登录账号
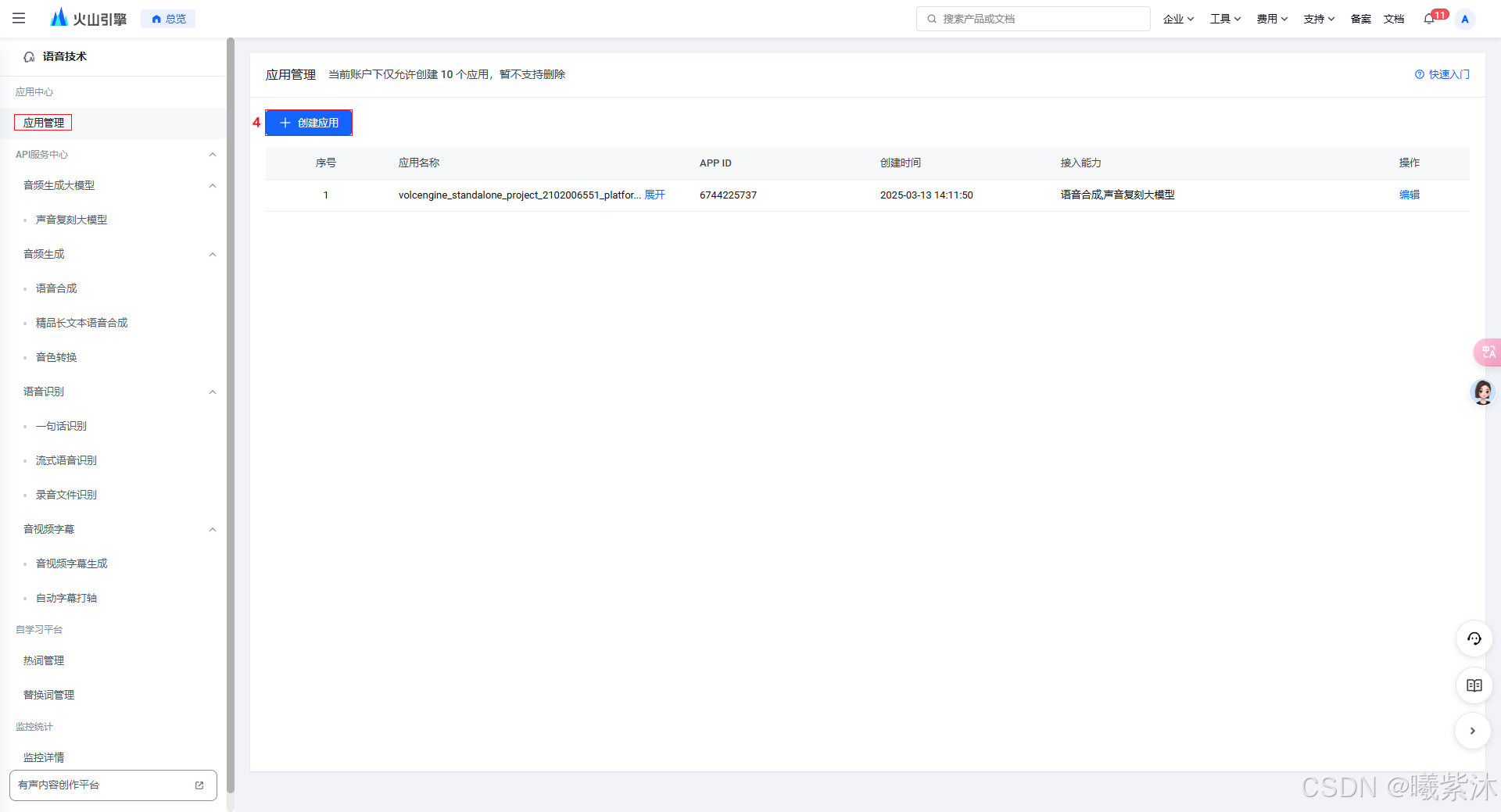
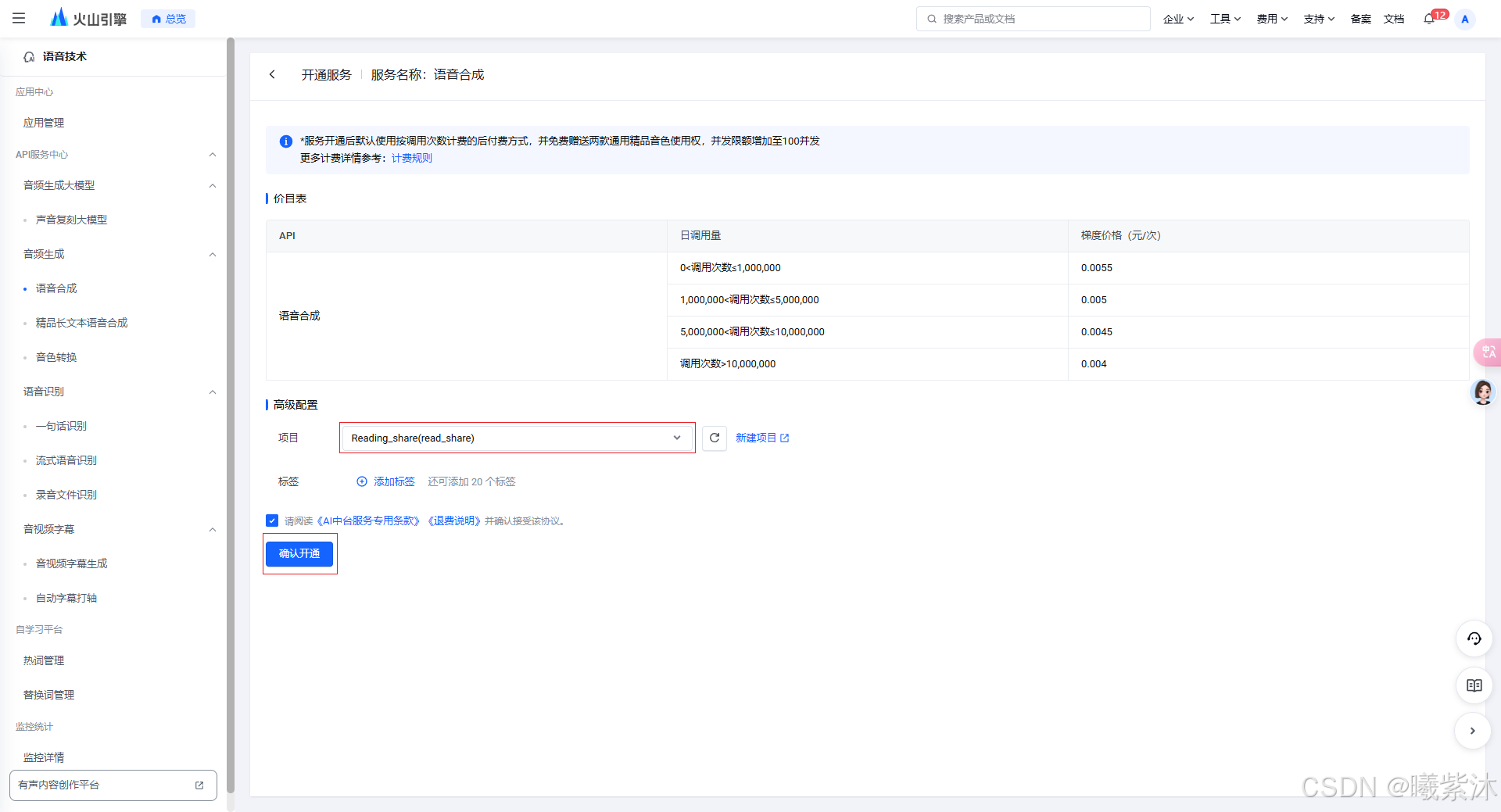
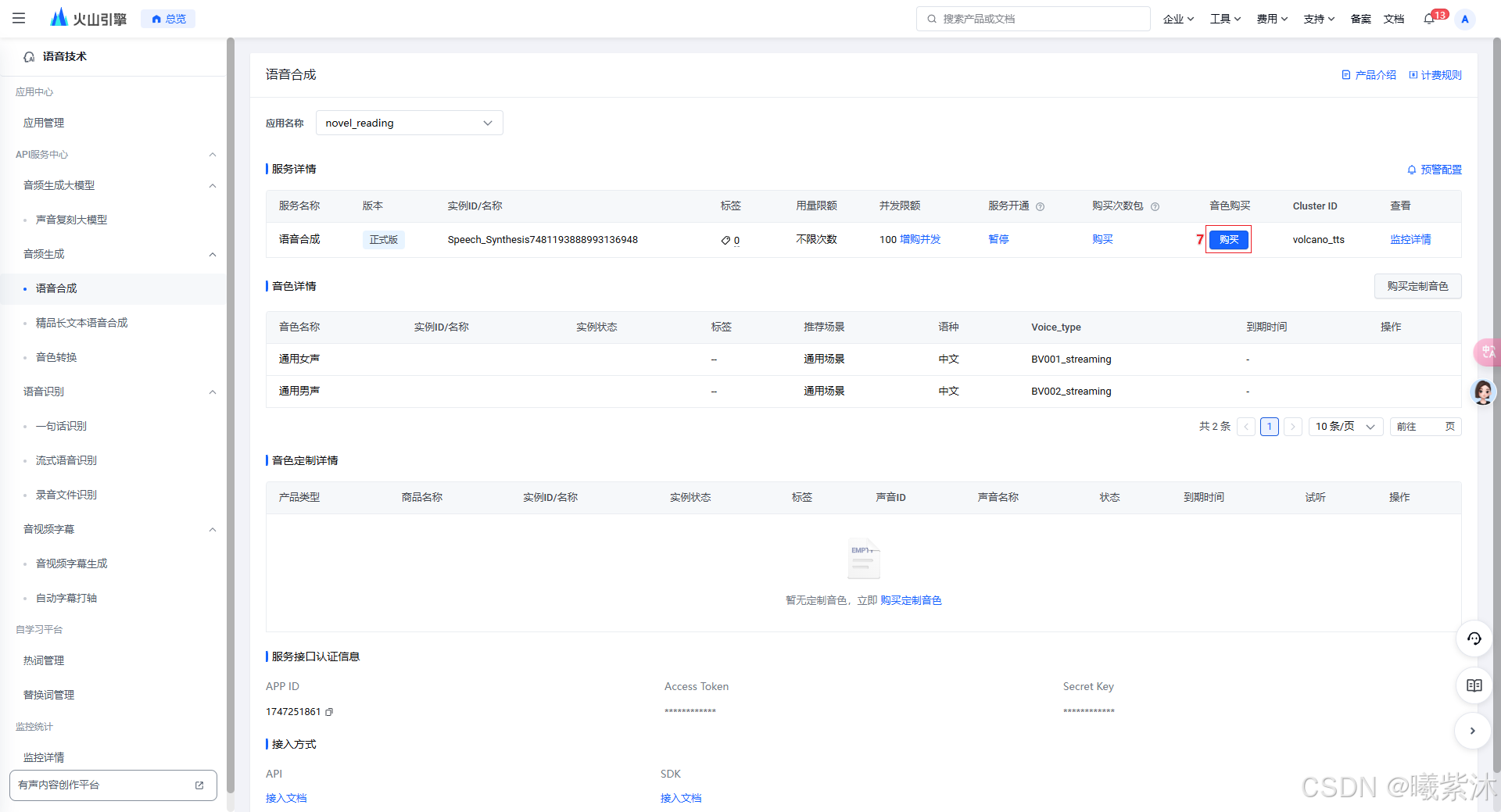
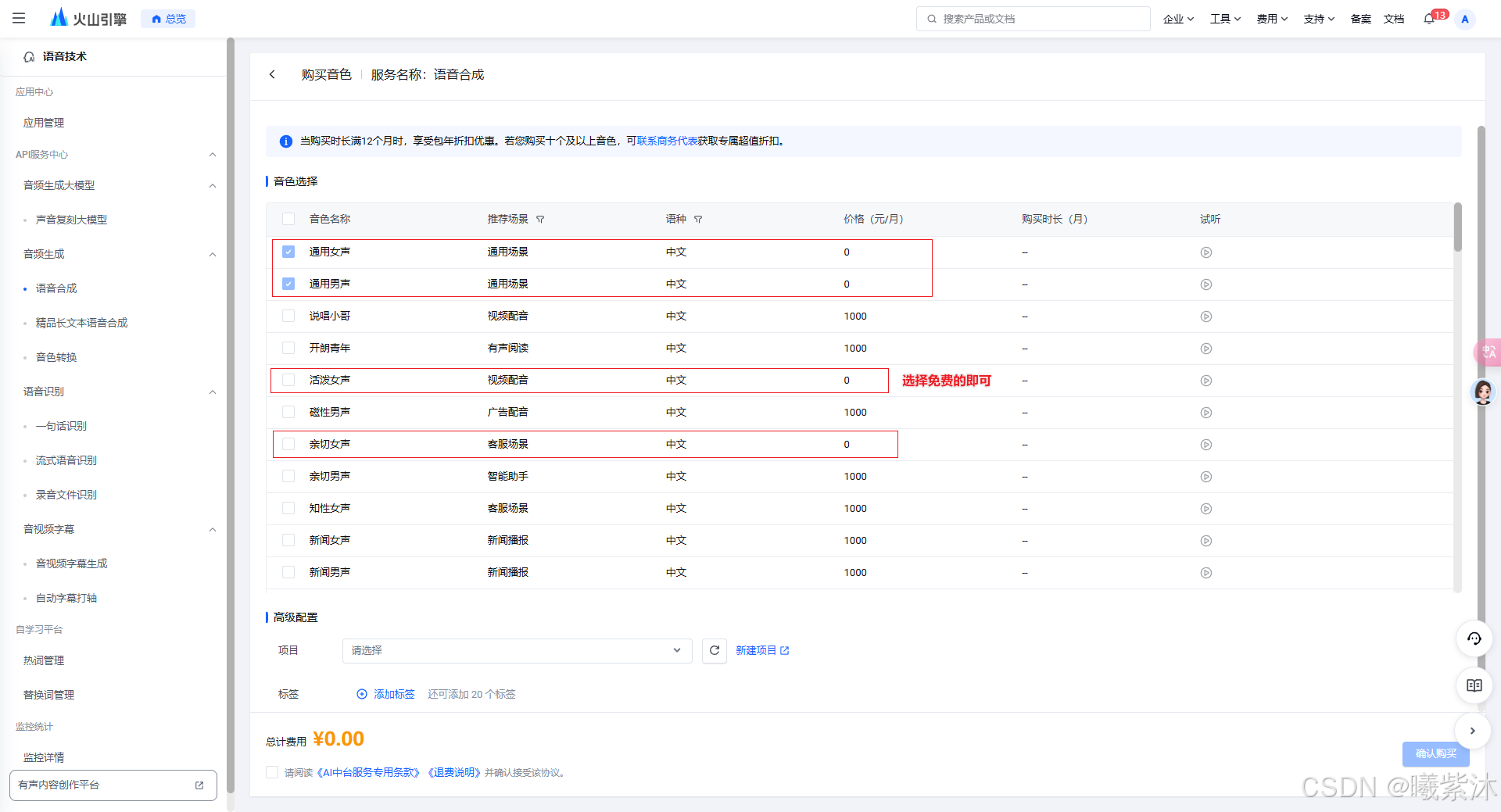
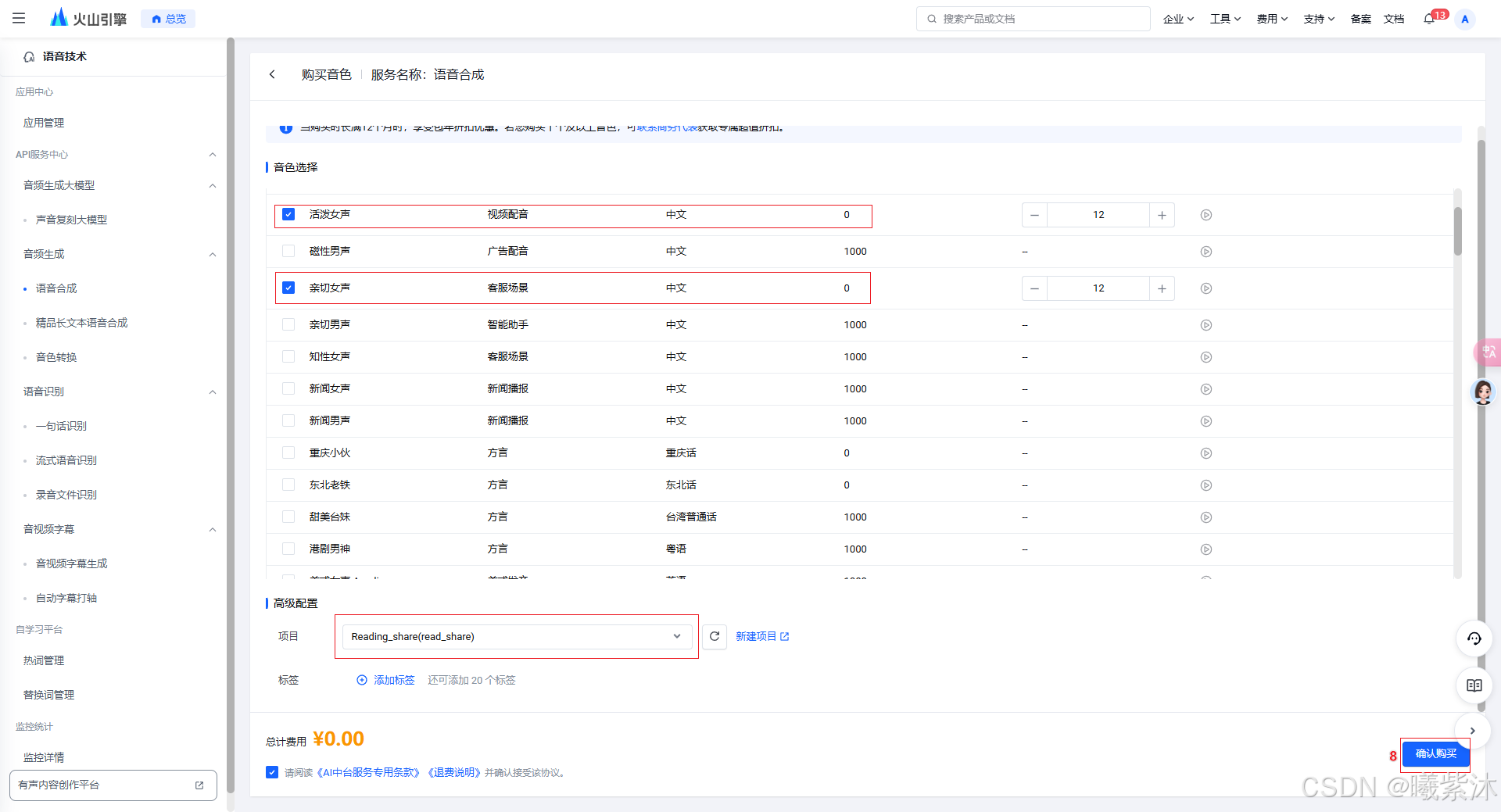
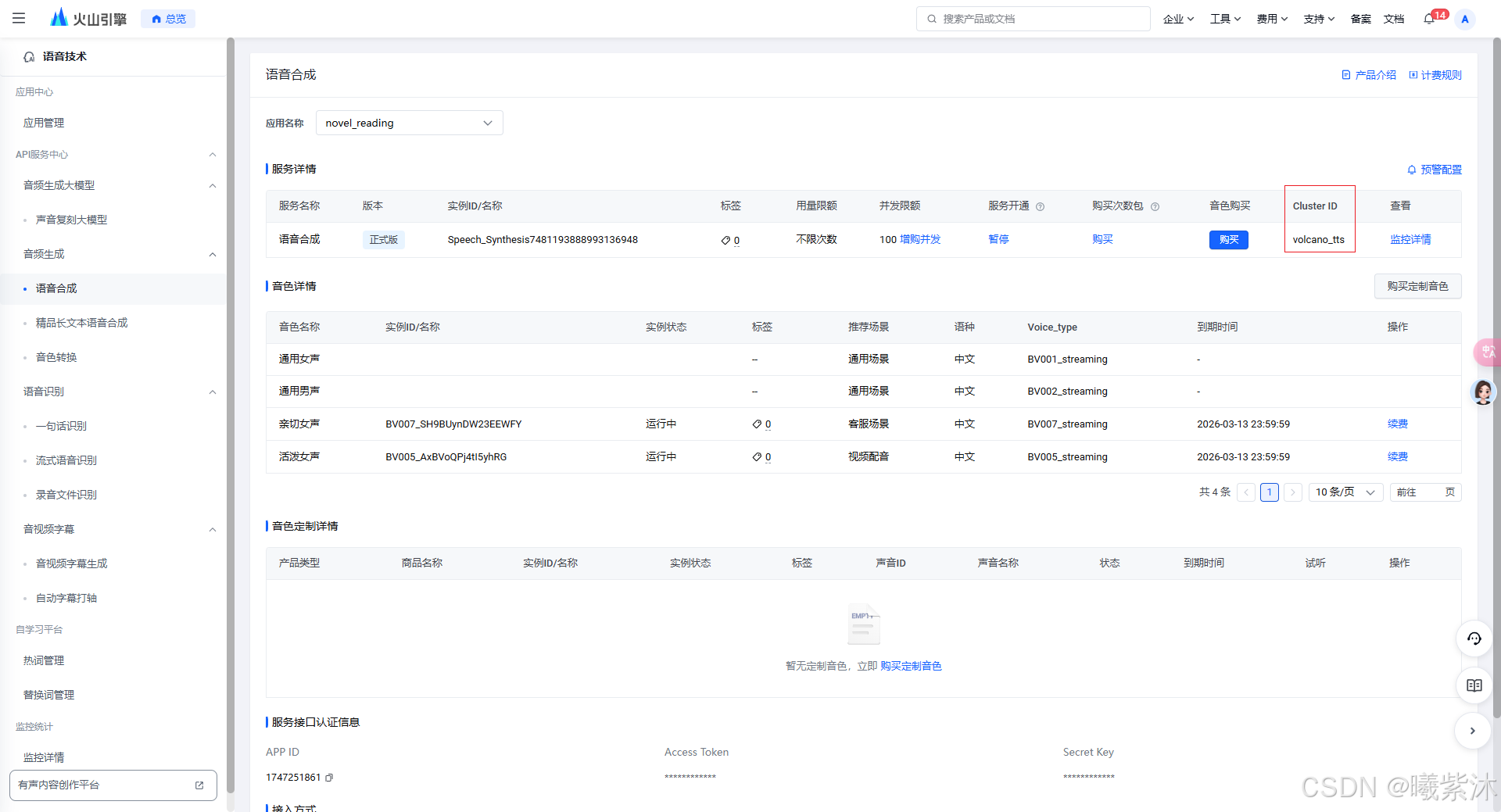
2.选择语音合成模型
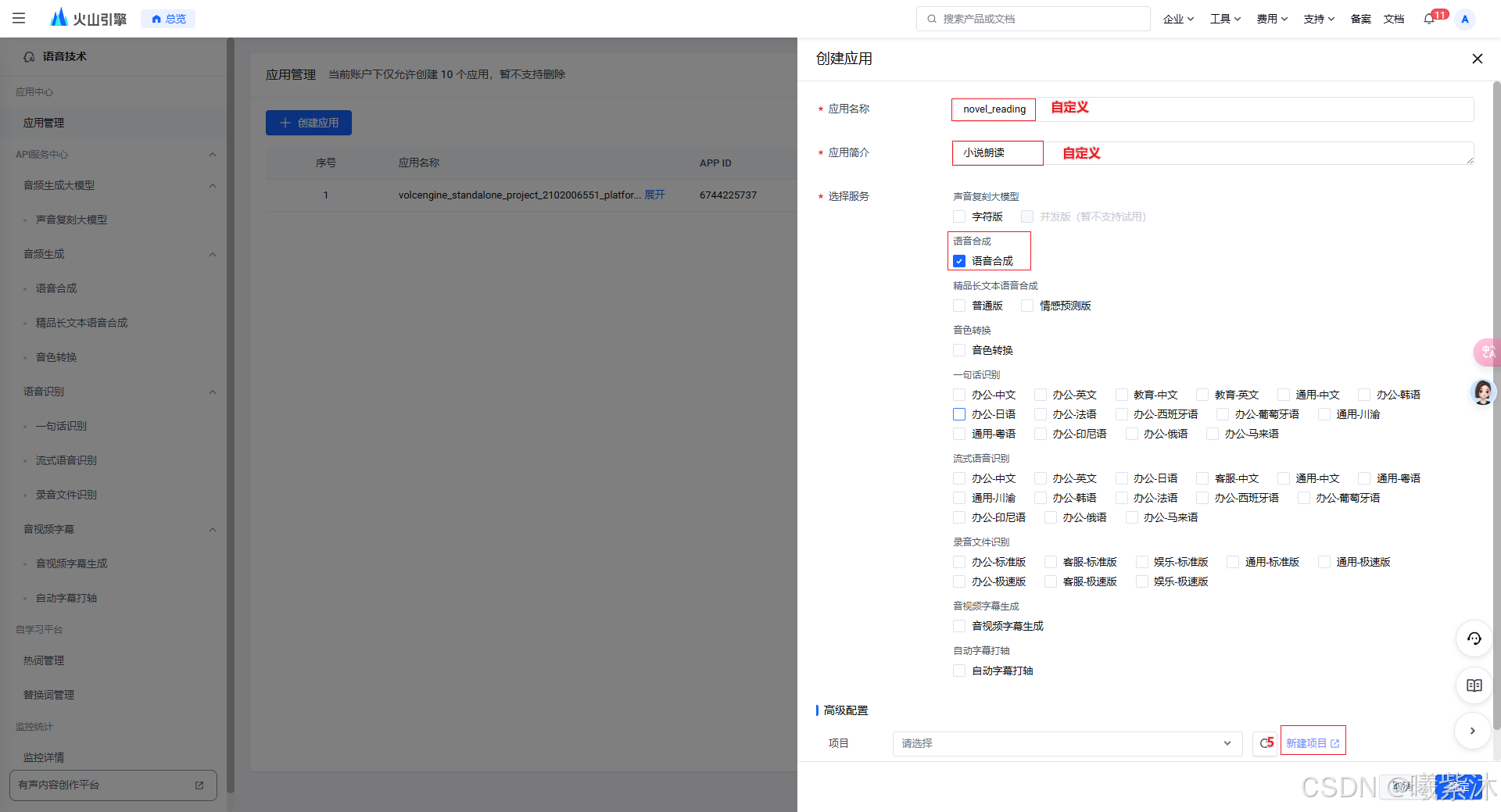
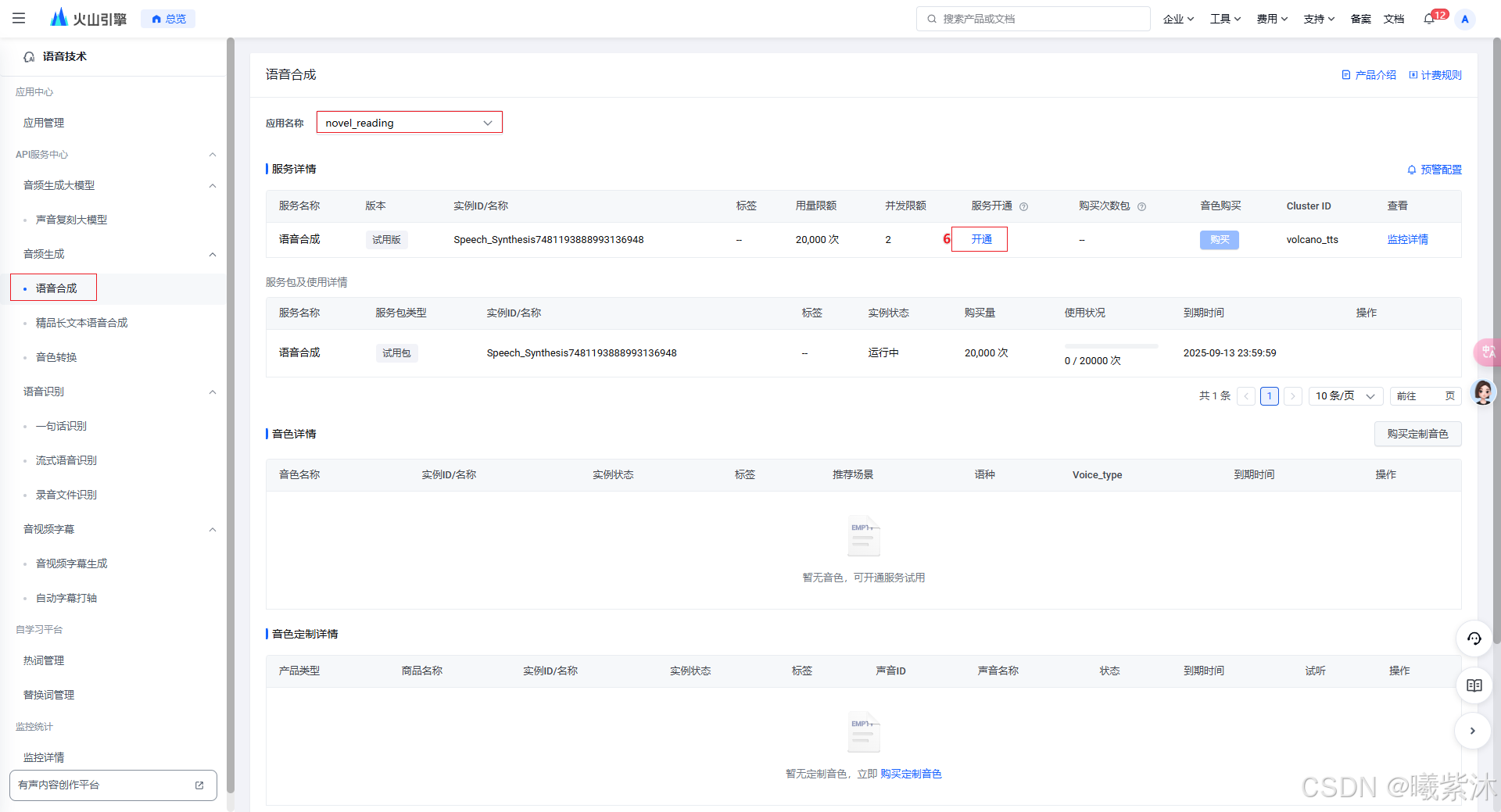
3. 操作流程

4. 创建Python虚拟环境
conda create -n doubao_tts python=3.12 -y
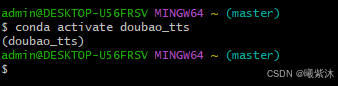
4.1 激活Python虚拟环境
conda activate doubao_tts
4.2 安装需要的软件包
pip install requests
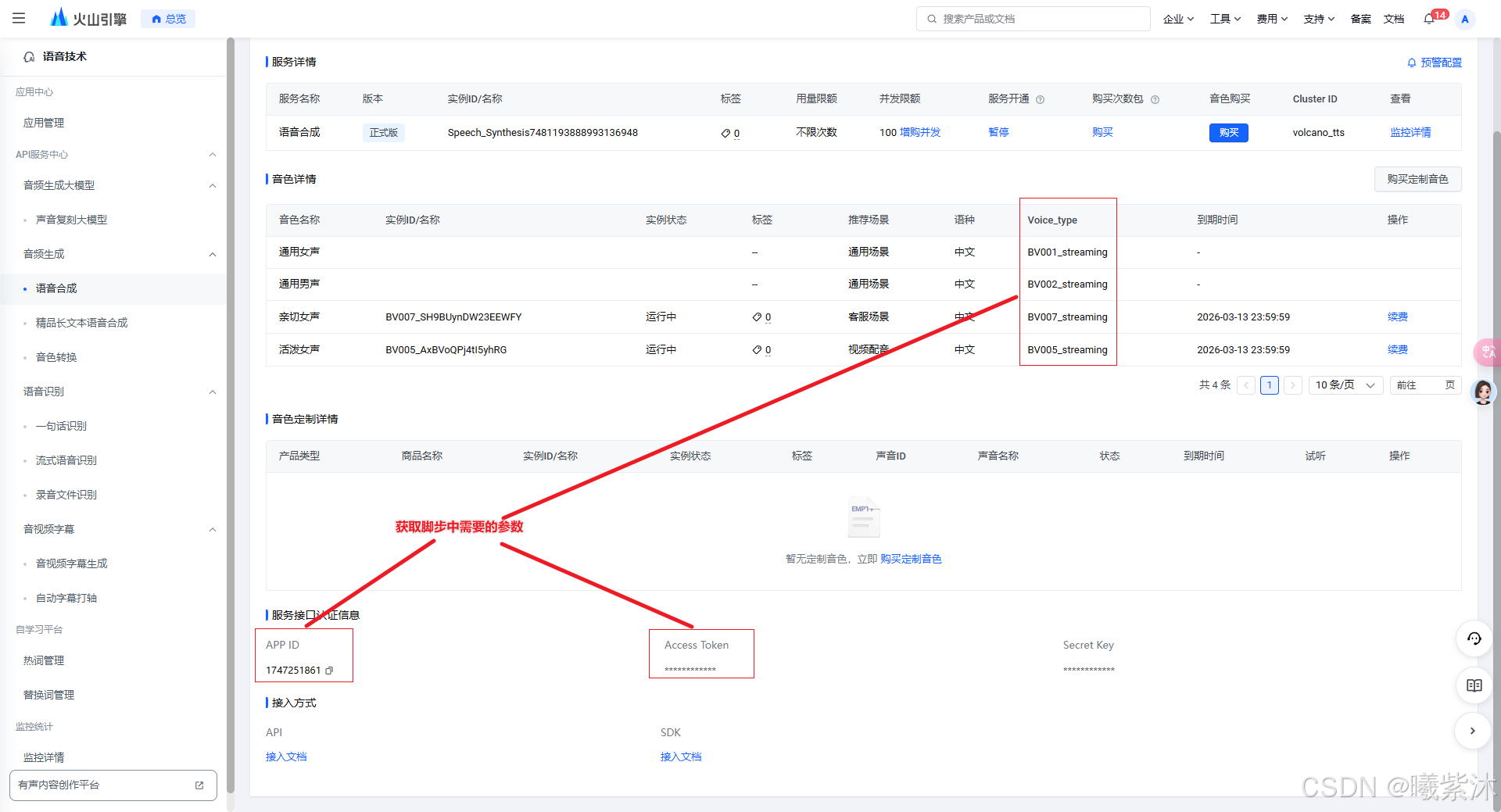
5.修改脚本中的参数
需要替换的参数有:
# 填写平台申请的appid, access_token以及cluster
appid = "xxx"
access_token= "xxx"
cluster = "xxx"
# 替换成自己喜欢的音色
voice_type = "xxx"
#coding=utf-8
'''
requires Python 3.6 or later
pip install requests
'''
import base64
import json
import uuid
import requests
# 填写平台申请的appid, access_token以及cluster
appid = "xxx"
access_token= "xxx"
cluster = "xxx"
text = """
1. 自律:解决问题的第一步 🛠️
派克认为,自律是解决人生问题的首要工具。它包含四个原则:
推迟满足感:先苦后甜,学会把困难的事情放在前面完成。比如,工作中先处理棘手的任务,再享受轻松的时光。
承担责任:不推卸、不逃避,直面问题并找到解决方案。
忠于事实:不活在幻想中,接受现实并调整自己的行为。
保持平衡:在自由与约束、责任与权利之间找到平衡点。
自律不是压抑自己,而是通过主动选择,让生活更有秩序和意义。正如书中所说:“自律是爱的表现,是为了让自己和他人变得更好。
"""
voice_type = "BV001_streaming"
host = "openspeech.bytedance.com"
api_url = f"https://{host}/api/v1/tts"
header = {"Authorization": f"Bearer;{access_token}"}
request_json = {
"app": {
"appid": appid,
"token": "access_token",
"cluster": cluster
},
"user": {
"uid": "388808087185088"
},
"audio": {
"voice_type": voice_type,
"encoding": "mp3",
"speed_ratio": 1.0,
"volume_ratio": 1.0,
"pitch_ratio": 1.0,
},
"request": {
"reqid": str(uuid.uuid4()),
"text": text,
"text_type": "plain",
"operation": "query",
"with_frontend": 1,
"frontend_type": "unitTson"
}
}
if __name__ == '__main__':
try:
resp = requests.post(api_url, json.dumps(request_json), headers=header)
print(f"resp body: \n{resp.json()}")
if "data" in resp.json():
data = resp.json()["data"]
file_to_save = open("test_submit.mp3", "wb")
file_to_save.write(base64.b64decode(data))
except Exception as e:
e.with_traceback()
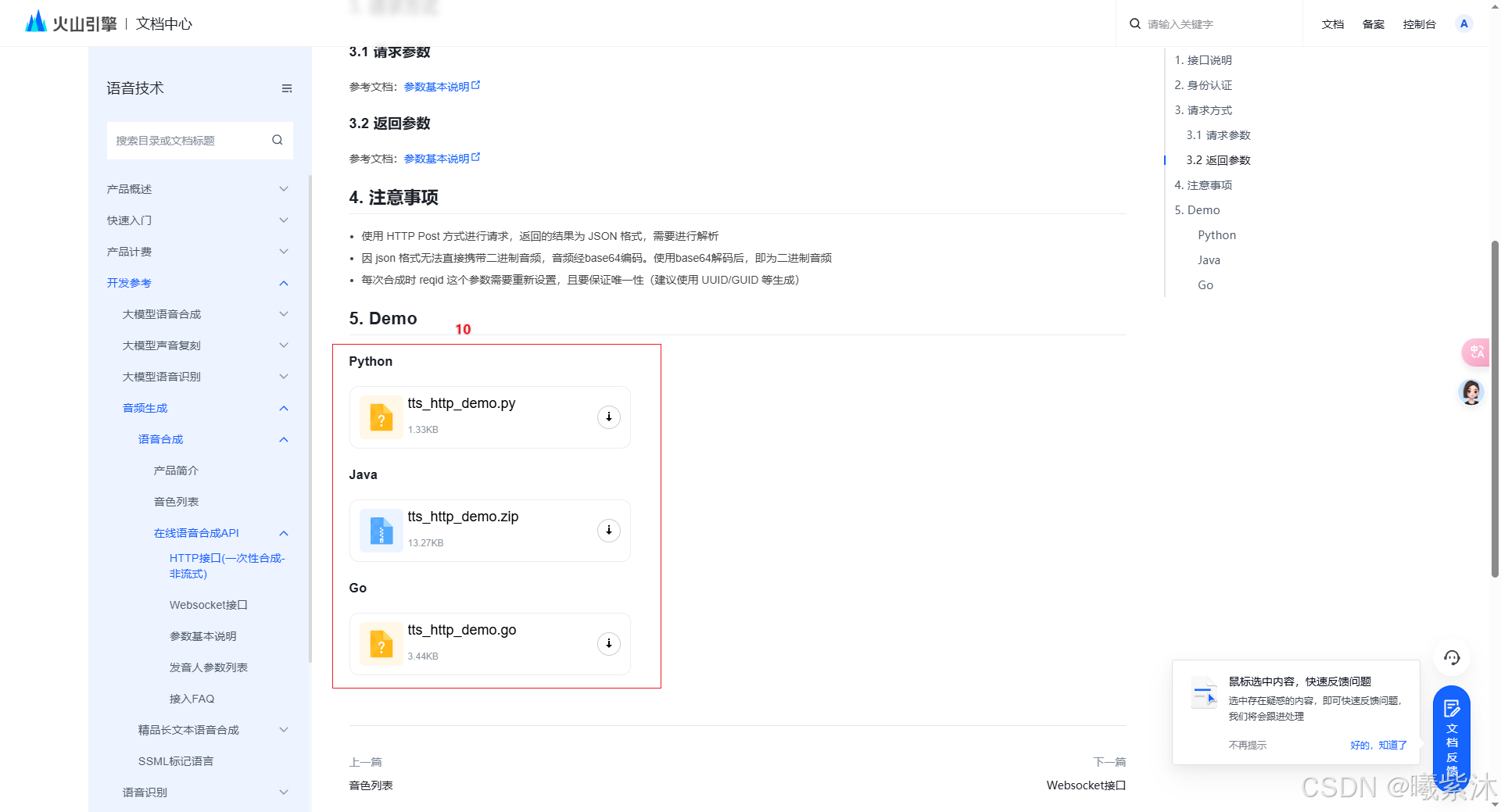
6.执行脚本
python tts_http_demo.py

附:
如果你对语音合成技术的应用场景或实现细节感兴趣,欢迎在评论区分享你的观点!后续将带来更多AI技术实践案例,记得关注不迷路~

















 1944
1944

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









