






目录
为什么要用过采样?
当我们创建一个逻辑回归模型时,往往会遇到这样一个问题,那就是两类标签的数量相差非常大,可能达到几十万甚至上百万,导致创建的模型往往不是很准确。
那么怎样才能避免或者是尽量减小误差呢?通常可以通过下采样或者过采样进行优化,这里我们就先来学习一种方法——过采样。
一、过采样
过采样是一种处理不平衡数据集的方法,它通过人工合成新的少数类样本,使得少数类样本的数量与多数类样本相当。这样可以提高分类模型对少数类样本的学习能力,从而改善分类性能。这里我们主要介绍SMOTE算法。
二、SMOTE算法
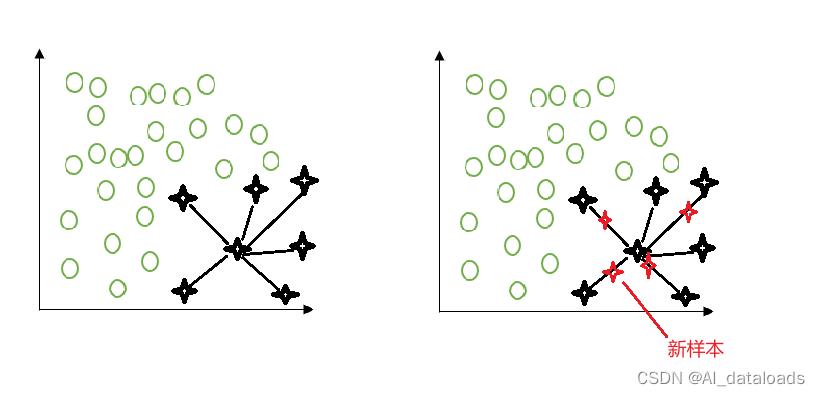
SMOTE(Synthetic Minority Over-sampling Technique)是一种用于处理类别不平衡问题的过采样方法,特别适用于少数类样本数量较少的情况。其基本思想是通过合成新的少数类样本来平衡数据集。
计算公式:
假设我们有一个少数类样本 x 和它的 k 个最近邻样本 {X₁, X₂, ..., Xₖ}。
生成新的合成样本的公式如下: 新样本 = X + rand(0,1) × (Xᵢ - X)
其中,rand(0,1)的范围在 [0, 1] 之间,用于控制合成样本的位置。
对于多个少数类样本,重复以上公式的步骤,即可生成相应数量的合成样本来平衡数据集。
注意:这里的公式是一个简化的表达方式,目的是说明 SMOTE 的基本原理。实际应用中,可能会使用不同的距离度量方法,比如欧氏距离(Euclidean distance)或其他相似性度量方法,来计算最近邻样本。
三、优缺点
优点:
-
改善分类性能:过采样可以增加少数类样本的数量,使得分类模型更好地学习少数类的特征,并提高对少数类样本的分类性能。
-
保留信息:过采样方法通过合成新的样本而不是仅仅重复复制已有样本,从而可以引入一定程度的新信息,丰富少数类样本的多样性。
-
不引入偏见:过采样在合成新的少数类样本时并不依赖于多数类样本,因此不会引入对多数类的任何偏见。
缺点:
-
过拟合风险:过采样会增加少数类样本的数量,可能导致模型对少数类样本过度拟合,从而降低其在未见样本上的泛化能力。
-
增加计算成本:过采样方法需要合成新的样本,这会增加数据集的规模,进而增加训练和预测的计算成本。
-
引入噪声:在合成新的少数类样本时,过采样方法可能引入一定程度的噪声,这可能对模型的性能产生不利影响。
-
类别平衡失衡:过采样可能会导致数据集类别的平衡性失衡,特别是当过采样比例过高时,会使得多数类样本的比例相对较低,从而可能导致模型对多数类样本的分类性能下降。
为了克服以上缺点,可以结合欠采样技术和集成学习方法来进行综合处理。欠采样可以减少多数类样本,从而减少计算成本和防止过拟合,而集成学习方法可以通过结合多个模型的预测结果来提高分类性能和泛化能力。此外,根据具体情况,选择适当的过采样方法和参数设置也是至关重要的。
四、python代码示例
以下代码首先读取了名为'creditcard.csv' 的信用卡数据集。删除了无用的 'Time' 列。数据集被分为特征和标签,其中特征保存在 x 中,标签保存在 y中。
SMOTE的具体操作如下:
首先,创建一个名为 oversampler 的 SMOTE 实例,通过 SMOTE(random_state=0) 来初始化。random_state=0 是为了设定随机数生成器的种子,以确保结果的可重现性。
接下来,在 fit_resample 方法中,将输入特征 x 和目标标签 y 作为参数传递给 SMOTE 实例进行处理。fit_resample 方法会执行以下操作:基于 SMOTE 算法生成一些合成的样本,以增加少数类的样本数量,使这两个类别之间的样本数量更加平衡。
最后,将生成的过采样样本集分别保存到变量 os_x 和 os_y 中,用于后续的模型训练或其他操作。通过这种方式,我们可以使用 SMOTE 算法来处理不平衡数据集,提高在少数类别上的分类性能。
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
# 读取信用卡数据集
data=pd.read_csv('creditcard.csv')
# 删除 Time 列,因为它是序号,是无用的
data = data.drop(['Time'],axis=1)
# 将数据集分为特征和标签
x=data.drop('Class',axis=1)
y=data.Class
number_0=len(y[y==0]) #统计标签为0的个数
number_1=len(y[y==1]) #统计标签为1的个数
print(f"标签为0的个数:{number_0}")
print(f"标签为1的个数:{number_1}")
# 使用 SMOTE 进行过采样
from imblearn.over_sampling import SMOTE
oversampler=SMOTE(random_state=0)
os_x,os_y=oversampler.fit_resample(x,y)
os_number_0=len(os_y[os_y==0]) #统计进行过采样后标签为0的个数
os_number_1=len(os_y[os_y==1]) #统计进行过采样后标签为1的个数
print(f"过采样后标签为0的个数:{os_number_0}")
print(f"过采样后标签为1的个数:{os_number_1}")运行结果:

由结果可知:
原始数据集中的0,1标签的数目差距非常大,但是经过过采样后我们人工增加了很多标签为1的数据,成功地平衡了数据集。

















 1503
1503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









