









类不平衡问题

类不平衡的数据集训练得到的分类器最大的问题就是:分类器对较大数量类别的数据的识别精度较高,对较小类别数据的识别精度较低,这是由于分类器在训练时学习了较多的较大数量类别的特征,而学习到的较小数量类别的特征较少,进而训练完成的分类器容易将较小类别的数据识别为较大类别的数据。
算法原理
SMOTE(Synthetic Minority Over-sampling Technique)算法是一种处理不平衡数据集的过采样技术。它通过生成新的少数类样本来平衡数据集,而不是简单地复制现有的少数类样本,从而减少过拟合的风险
实现过程
(1)根据类别数量不平衡,获得每个少数类别的增量数量
例如:类别A中有100个样本,类别B中只有50个样本,则类别B为少数类别,类别B的需增量数量为100-50=50。
(2)找出每个少数类样本的k个最近邻居
例如:类别B中的样本b3,将与该样本的相似度最大的5个样本作为b3的最近邻居。
(3)每个样本通过其k近邻样本生成新的样本点
例如:类别B中的样本b3结合最近邻居中的b4样本点,生成了新的样本点b55。
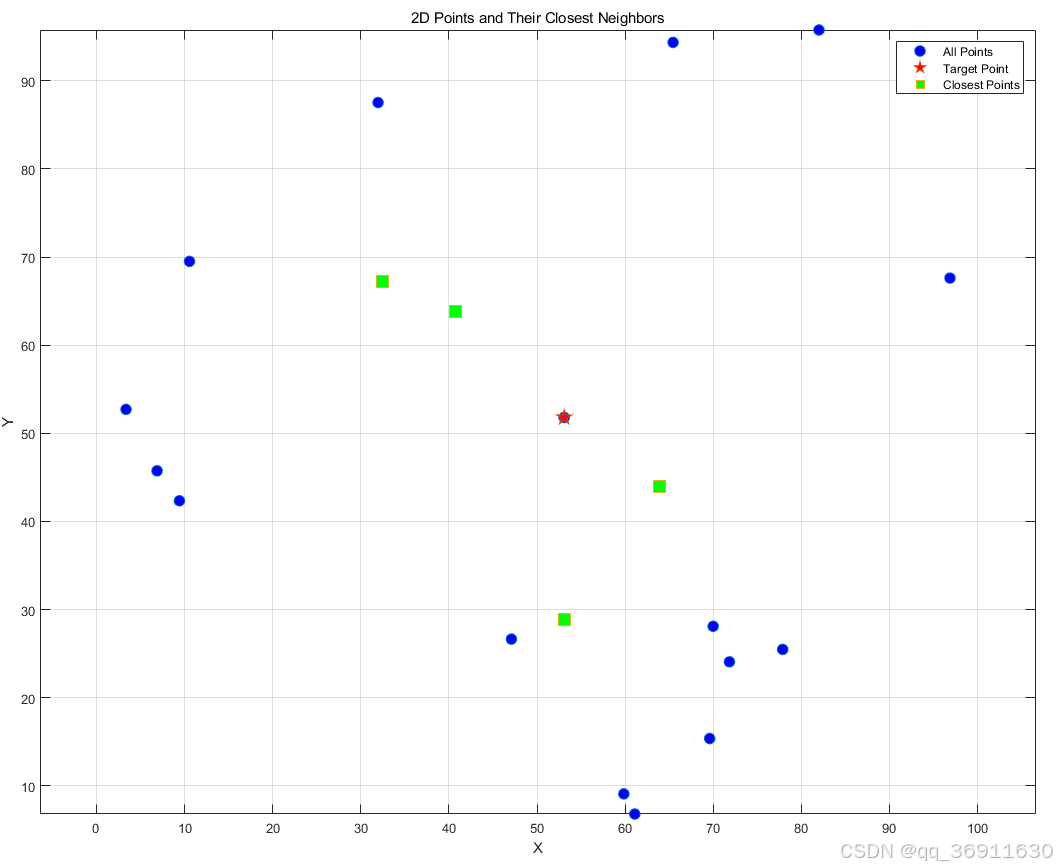
如图所示,图中共有20个点,其中红色星号的点为目标点,即计算该点的最近邻点,绿色方格点为该点的4个最近邻点。
示例和实现代码
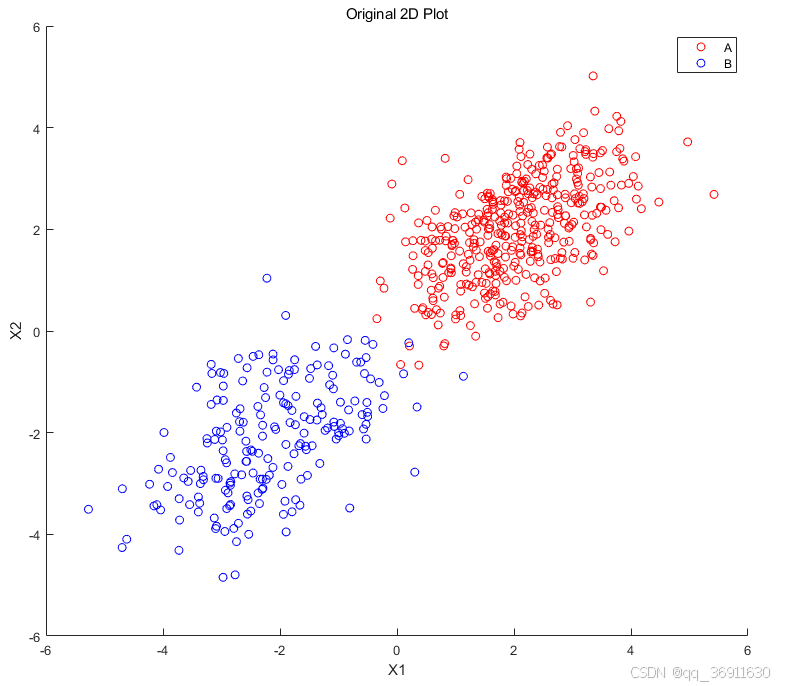
如图所示,红色点和蓝色点属于两个不同的类别,其中红色点类别的数量为400,蓝色点类别的数量为200,蓝色点类别为少数点类别。原始的两个类别的数据点图示如 Original 2D Plot 图所示。
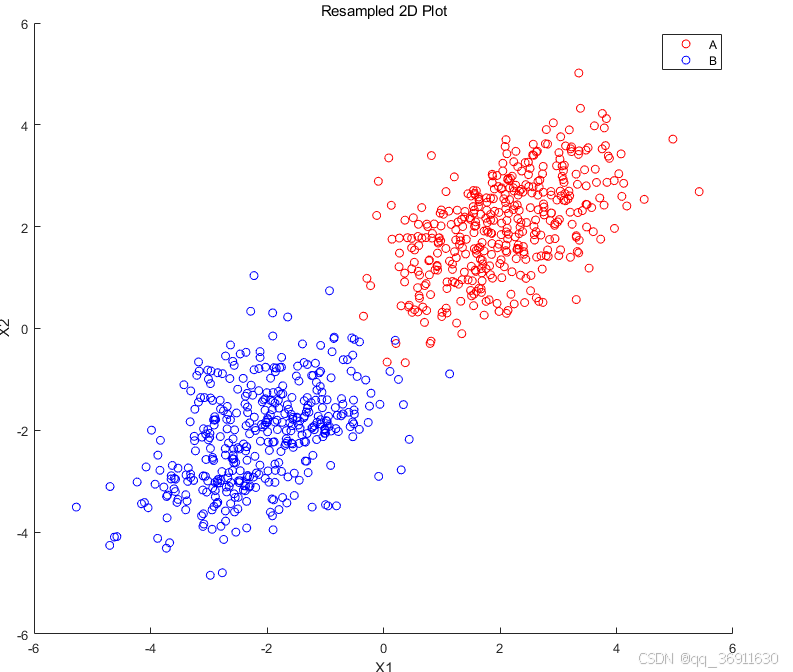
下图为: 对蓝色点通过smote方法新增了100个样本点后得到的蓝色点和红色点的分布对比图,如 Resampled 2D Plot 图示。
代码:
% 生成A组和B组的二维数据
A = mvnrnd([2 2], [1 0.5; 0.5 1], 400);
B = mvnrnd([-2 -2], [1 0.5; 0.5 1], 200);
% 绘制原始的二维图
figure;
scatter(A(:, 1), A(:, 2), 'r');
hold on;
scatter(B(:, 1), B(:, 2), 'b');
xlabel('X1');
ylabel('X2');
title('Original 2D Plot');
legend('A', 'B');
hold off;
% 使用SMOTE算法对B组数据进行增量
B_resampled = smote(B, 200);
% 绘制增量后的二维图
figure;
scatter(A(:, 1), A(:, 2), 'r');
hold on;
scatter(B_resampled(:, 1), B_resampled(:, 2), 'b');
xlabel('X1');
ylabel('X2');
title('Resampled 2D Plot');
legend('A', 'B');
hold off;
% SMOTE算法的实现
function B_resampled = smote(B, k)
% B: 输入特征矩阵
% k: 需要为每个样本生成的新样本数
% B_resampled: 扩展后的B组数据
[n, d] = size(B); % n是样本数量,d是特征数量
B_resampled = B; % 初始的B组数据
for i = 1:n
% 随机选择一个样本
selected_sample = B(randi(n), :);
% 计算差异并生成新样本
diff = selected_sample - B(i, :);
new_samples = B(i, :) + rand(1, d) .* diff;
% 将新样本添加到B_resampled中
B_resampled = [B_resampled; new_samples];
end
% 由于我们为每个样本生成了一个新样本,我们需要从结果中随机选择k个样本
B_resampled = B_resampled(1:200 + k, :);
end
改进点
以下是针对SMOTE算法改进点的现有论文或专利,以及相关链接:
1. **动态调整K值**:
- 改进方向:根据不同样本的局部密度动态调整K值。
- 原理:在样本密度高的区域,选择较小的K值以保持样本多样性;在样本密度低的区域,选择较大的K值以增加样本数量。
- 举例:在处理图像数据时,边缘区域的样本密度通常较低,可以动态增加K值以生成更多样本。
- 相关论文:[Research on expansion and classification of imbalanced data based on SMOTE algorithm](https://www.nature.com/articles/s41598-021-03430-5)
2. **权重调整的SMOTE**:
- 改进方向:根据样本在不同维度上的类别代表性赋予权重。
- 原理:在生成新样本时,对那些在某些维度上更具代表性的样本赋予更高的权重。
- 举例:在医学数据分析中,某些症状可能在区分疾病类别上更为关键,因此可以增加这些症状维度的权重。
- 相关论文:[Weighted-SMOTE: A modification to SMOTE for event classification in sodium cooled fast reactors](https://www.researchgate.net/publication/320061271_Weighted-SMOTE_A_modification_to_SMOTE_for_event_classification_in_sodium_cooled_fast_reactors)
3. **基于类别差异的SMOTE**:
- 改进方向:在生成新样本时考虑类别间的差异性。
- 原理:优先选择那些与目标类别差异较大的样本作为近邻,以生成新样本。
- 举例:在金融欺诈检测中,正常交易和欺诈交易在某些特征上可能差异显著,可以利用这些特征生成新样本。
- 相关论文:[Geometric SMOTE a geometrically enhanced drop-in replacement for SMOTE](https://www.sciencedirect.com/science/article/abs/pii/S0020019019303401)
4. **基于拓扑关系的SMOTE**:
- 改进方向:考虑样本点的拓扑关系。
- 原理:在生成新样本时,考虑样本点在数据空间中的拓扑结构,以保持数据的拓扑一致性。
- 举例:在社交网络分析中,用户之间的连接关系可以作为拓扑结构,用于生成新的用户行为样本。
- 相关论文:[CURE-SMOTE algorithm and hybrid algorithm for feature selection and parameter optimization based on random forests](https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-017-1770-9)
5. **基于异常监测的SMOTE**:
- 改进方向:在异常监测中应用SMOTE,以提高异常检测的准确性。
- 原理:在生成新样本时,特别关注那些可能被误判为异常的样本。
- 举例:在网络安全中,某些正常的网络行为可能被误判为攻击,通过SMOTE改进可以减少这种误判。
- 相关论文:[SMOTE for learning from imbalanced data: Progress and challenges, marking the 15-year anniversary](https://jair.org/index.php/jair/article/view/11168)
6. **基于数据传输优先级的SMOTE**:
- 改进方向:在数据传输中应用SMOTE,以优化数据的优先级。
- 原理:根据数据的传输优先级,生成新的数据样本,以确保高优先级数据的传输。
- 举例:在物联网中,可以根据传感器数据的重要性生成新的数据样本,以优化数据传输。
- 相关论文:[Improvement of maximum variance weight partitioning particle filter in urban computing and intelligence](https://ieeexplore.ieee.org/document/8805294)
7. **基于噪声过滤的SMOTE**:
- 改进方向:在生成新样本时减少噪声的影响。
- 原理:在生成新样本前,先对数据进行噪声过滤,以提高新样本的质量。
- 举例:在语音识别中,可以先过滤掉背景噪声,再生成新的语音样本。
- 相关论文:[Preprocessing noisy imbalanced datasets using SMOTE enhanced with fuzzy rough prototype selection](https://www.sciencedirect.com/science/article/abs/pii/S1568494615300884)
8. **基于数据分布范围的SMOTE**:
- 改进方向:适应不同数据分布范围的SMOTE。
- 原理:根据数据的分布范围,调整新样本的生成策略,以适应不同的数据分布。
- 举例:在气象数据分析中,可以根据不同的气候区域调整新样本的生成策略。
- 相关论文:[A generalized method to predict the compressive strength of high-performance concrete by improved random forest algorithm](https://www.sciencedirect.com/science/article/abs/pii/S0950653119315020)
9. **基于样本多样性的SMOTE**:
- 改进方向:增加样本多样性。
- 原理:在生成新样本时,不仅考虑最近的K个近邻,也考虑更远的样本,以增加样本的多样性。
- 举例:在图像识别中,可以通过考虑不同距离的样本来生成新的图像样本,以提高模型的泛化能力。
- 相关论文:[Augmenting the diversity of imbalanced datasets via multi-vector stochastic exploration oversampling](https://www.sciencedirect.com/science/article/pii/S0925231224003710)
10. **基于类别代表性的SMOTE**:
- 改进方向:根据样本的类别代表性生成新样本。
- 原理:优先选择那些更具类别代表性的样本来生成新样本,以提高新样本的代表性。
- 举例:在文本分类中,可以优先选择那些最能代表特定主题的文本样本来生成新的文本样本。
- 相关论文:[LR-SMOTE—An improved unbalanced data set oversampling based on K-means and SVM](https://www.sciencedirect.com/science/article/abs/pii/S0950653120301458)


















 4654
4654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











