






一、卷积神经网络必须输入相同大小的图片吗?
答案是不必。卷积神经网络(CNN)不要求输入的图片必须具有相同的大小。通常,CNN可以处理不同大小的图片。在实践中,常见的做法是将图片缩放或裁剪成相同的尺寸,以便于批处理和训练。但是,使用卷积神经网络的一些架构,如全局平均池化层(Global Average Pooling),允许处理不同尺寸的输入图片,这使得网络更加灵活。
当有全连接层时,必须输入相同大小的图片。这是因为全连接层和前面一层的连接的参数数量需要事先确定,不像卷积核的参数个数就是卷积核大小,前层的图像大小不管怎么变化,卷积核的参数数量也不会改变,但全连接的参数是随前层大小的变化而变的,如果输入图片大小不一样,那么全连接层之前的feature map也不一样,那全连接层的参数数量就不能确定, 所以必须实现固定输入图像的大小。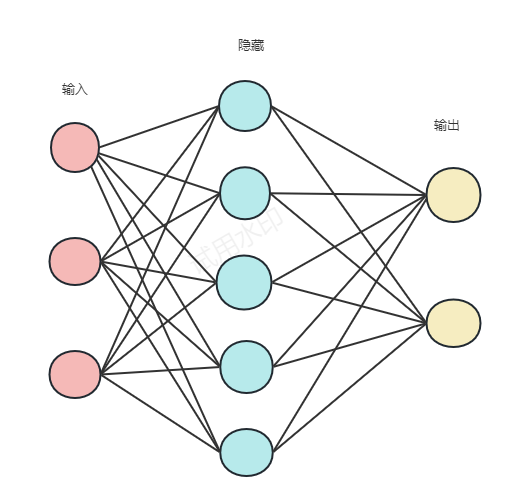
全连接神经网络结构一旦固定,需要学习的参数w是固定的,例如 输入图像是 28*28 = 784,w 的转置= (500,784),输出矩阵的shape:(500,1),如果输入图像的大小改变,但是w的大小并不会改变,因此,无法计算。
而对于卷积神经网络,卷积核的每个元素表示参数w,不论输入图像大小怎么改变,卷积核大小是不变的,并且通过卷积操作,每次都能训练到卷积核中的元素,所以卷积神经网络的输入图像的大小是任意的。
二、具体实例验证
将多组不同大小的照片输入卷积神经网络,有全连接层时
class CNN(nn.Module):
def __init__(self): # 输入大小 (3, 256, 256)
super(CNN, self).__init__()
self.conv1 = nn.Sequential( #将多个层组合成一起。
nn.Conv2d( #2d一般用于图像,3d用于视频数据(多一个时间维度),1d一般用于结构化的序列数据
in_channels=3, # 图像通道个数,1表示灰度图(确定了卷积核 组中的个数),
out_channels=16,# 要得到几多少个特征图,卷积核的个数
kernel_size=5, # 卷积核大小,5*5
stride=1, # 步长
padding=2, # 一般希望卷积核处理后的结果大小与处理前的数据大小相同,效果会比较好。那padding改如何设计呢?建议stride为1,kernel_size = 2*padding+1
), # 输出的特征图为 (16, 256, 256)
nn.ReLU(), # relu层
nn.MaxPool2d(kernel_size=2), # 进行池化操作(2x2 区域), 输出结果为: (16, 128, 128)
)
self.conv2 = nn.Sequential( #输入 (16, 128, 128)
nn.Conv2d(16, 32, 5, 1, 2), # 输出 (32, 128, 128)
nn.ReLU(), # relu层
nn.Conv2d(32, 32, 5, 1, 2), # 输出 (32, 128, 128)
nn.ReLU(),
nn.MaxPool2d(2), # 输出 (32, 64, 64)
)
self.conv3 = nn.Sequential( #输入 (32, 64, 64)
nn.Conv2d(32, 64, 5, 1, 2),
nn.ReLU(), # 输出 (64, 64, 64)
)
self.out = nn.Linear(64 * 64 * 128, 20) # 全连接层得到的结果
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)# 输出 (64,64, 32, 32)
x = x.view(x.size(0), -1) # flatten操作,结果为:(batch_size, 64 * 32 * 32)
output = self.out(x)
return output输出层必须为64*64*64,,如上述代码64*64*128,则会导致计算出错,从而报错

这是由于全连接层是层层相扣的,在矩阵乘法中,第一个矩阵的列数必须与第二个矩阵的行数相等。第一个矩阵的形状是64x262144,即有64行和262144列,而第二个矩阵的形状是524288x20,即有524288行和20列。显然,第一个矩阵的列数和第二个矩阵的行数并不相等,所以这两个矩阵不能相乘。
所以,全连接层必须输入相同大小的图片















 1267
1267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









