






目录
一、背景简介
ResNet152是深度残差网络(Deep Residual Network)的一种,它是一个非常强大的图像分类模型。该网络由微软研究院提出,其核心思想是通过引入残差模块和瓶颈结构,使得模型可以在更深的层次上有效地学习图像特征,从而避免优化函数陷入局部最优解和梯度消失的问题。基本原理是通过引入残差模块和瓶颈结构,使得模型可以在更深的层次上有效地学习图像特征,从而避免优化函数陷入局部最优解和梯度消失的问题。
ResNet的设计思路是将输入特征通过一系列的卷积层、池化层等操作后,再将其与原始输入特征进行求和,这样就可以保留更多的原始信息,避免信息在多层网络中传递时被丢失。这种残差连接的设计使得网络在训练时可以跳过一些不必要的卷积操作,从而减少计算量和模型大小,同时提高模型的性能。
二、ResNet152残差网络应用实践
ResNet152残差网络在应用实践中表现出色,被广泛应用于各种计算机视觉任务中,如图像分类、目标检测、语义分割等,本次将以图像分类方面为案例进行实践操作演示。
1、定义ResNet152模型
resnet_model = models.resnet152(weights=models.ResNet152_Weights.DEFAULT) #创建ResNet152模型实例
for param in resnet_model.parameters():#冻结模型参数,只剩全连接层
param.requires_grad = False
in_features = resnet_model.fc.in_features
resnet_model.fc = nn.Linear(in_features,20)
params_to_update = []
for param in resnet_model.parameters():#遍历ResNet152模型的所有参数
if param.requires_grad == True:
params_to_update.append(param)
具体参数详解如下:
resnet_model = models.resnet152(weights=models.ResNet152_Weights.DEFAULT):这行代码创建了一个ResNet152模型实例。models.resnet152是PyTorch中预定义的ResNet152模型函数。weights=models.ResNet152_Weights.DEFAULT指定了使用默认的预训练权重。for param in resnet_model.parameters(): param.requires_grad = False:这行代码将ResNet152模型中所有参数的requires_grad属性设置为False。这意味着在反向传播(backpropagation)时,这些参数不会更新。这通常用于冻结模型的某些部分,以防止在训练过程中改变其参数。in_features = resnet_model.fc.in_features:这行代码获取ResNet152模型的最后全连接层的输入特征数量。resnet_model.fc = nn.Linear(in_features,20):这行代码将ResNet152模型的最后全连接层替换为一个新的全连接层,该全连接层的输入特征数量与原来的相同(in_features),输出特征数量为20。params_to_update = [] for param in resnet_model.parameters(): if param.requires_grad == True: params_to_update.append(param):这里创建了一个空列表params_to_update,然后遍历ResNet152模型的所有参数。对于每个需要更新的参数(即param.requires_grad == True),将其添加到params_to_update列表中。
通过上述过程创建了一个ResNet152模型,冻结了其所有参数(不更新这些参数),然后修改了最后的全连接层,以使其输出20维的向量,而不是原始的类别向量。同时,准备了一个列表,用于存储需要更新的参数,以便在训练过程中使用。
2、输入图像预处理
data_transforms = { #也可以使用PIL库,smote 人工拟合出来数据
'train':
transforms.Compose([
transforms.Resize([300,300]), #是图像变换大小
transforms.RandomRotation(45),#随机旋转,-45到45度之间随机选
transforms.CenterCrop(256),#从中心开始裁剪[256,256]
transforms.RandomHorizontalFlip(p=0.5),#随机水平翻转 选择一个概率概率
transforms.RandomVerticalFlip(p=0.5),#随机垂直翻转
transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),#参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相
transforms.RandomGrayscale(p=0.1),#概率转换成灰度率,3通道就是R=G=B
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#标准化,均值,标准差
]),
'valid':
transforms.Compose([
transforms.Resize([256,256]),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}下面对部分参数进行详细解释:
'train'和'valid':这两个键定义了两种数据转换的方式,分别用于训练集和验证集。通常,训练集和验证集的转换方式可能会有所不同,例如验证集可能不需要进行数据增强。transforms.Compose([...]):这是PyTorch的图像转换工具,它接受一系列的转换操作(称为“transforms”),并将它们串联起来,使得每个转换都会在前一个转换之后执行。transforms.ToTensor():这个操作会将输入的图像从PIL Image或者numpy.ndarray转化为PyTorch的Tensor。transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]):这个操作会标准化输入的Tensor,使其具有指定的均值和标准差。这在训练神经网络时很常见,因为这可以帮助网络更好地学习特征。
以上代码部分定义了两种用于图像数据预处理的转换方式:一种用于训练集,另一种用于验证集。这些转换包括调整图像大小、旋转、裁剪、翻转、色彩抖动、灰度化以及标准化等步骤。
3、定义自定义数据集类
class food_dataset(Dataset): #food_dataset是自己创建的类名称,可以改为你需要的名称
def __init__(self, file_path,transform=None): #类的初始化
self.file_path = file_path
self.imgs = []
self.labels = []
self.transform = transform
with open(self.file_path) as f:
samples = [x.strip().split(' ') for x in f.readlines()]
for img_path, label in samples:
self.imgs.append(img_path)
self.labels.append(label)
def __len__(self): #类实例化对象后,可以使用len函数测量对象的个数
return len(self.imgs)
def __getitem__(self, idx): #关键,可通过索引的形式获取每一个图片数据及标签
image = Image.open(self.imgs[idx]) #
if self.transform:
image = self.transform(image)
label = self.labels[idx]
label = torch.from_numpy(np.array(label,dtype = np.int64))
return image, label
training_data = food_dataset(file_path = 'train.txt',transform = data_transforms['train'])
test_data = food_dataset(file_path = 'test.txt',transform = data_transforms['valid'])
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True) # 64张图片为一个包,
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)定义了一个自定义的数据集类 food_dataset,它从文件中读取图片路径和对应的标签,并提供了一种方法来获取数据集中的样本。这个类可以用于 PyTorch 的数据加载器(DataLoader),以便在训练循环中批量加载和转换数据。具体操作解析详看下文定义训练和测试数据集
注:下述定义训练集及测试集均在上述连接中有讲述,本文不再叙述
4、检测可用计算设备及定义优化器
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"#检测是否支持GPU
print(f"Using {device} device")
model = resnet_model.to(device)
loss_fn = nn.CrossEntropyLoss()#定义交叉熵损失函数
optimizer = torch.optim.Adam(params_to_update,lr=0.001)#定义优化器部分参数详解如下:
model = resnet_model.to(device):将预定义的ResNet模型转移到之前确定的设备上。如果设备是CPU或MPS,这行代码没有实际作用,因为模型已经在这些设备上。但如果设备是CUDA,这行代码会将模型放到GPU上。optimizer = torch.optim.Adam(params_to_update,lr=0.001):定义了一个优化器,即Adam优化器。它将使用学习率(lr)为0.001来优化模型中的参数。这里的
params_to_update是一个指向模型中需要更新的参数的引用。通常,这意味着模型的权重和偏差。
5、模型训练
epochs = 20 #定义训练次数
for t in range(epochs):
start_time = time.time()
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer) #进行训练和测试
test(test_dataloader, model, loss_fn)
end_time = time.time()
time_diff = end_time - start_time
print("时间差:", time_diff) #计算训练时间
print()通过执行20次的训练,并记录每次的损失和准确率,进而判断图像分类的结果是否符合要求。
6、完整代码及结果展示
import torch
from torch.utils.data import Dataset,DataLoader
import numpy as np
from torch import nn
from PIL import Image
from torchvision import transforms
import torchvision.models as models
import time
resnet_model = models.resnet152(weights=models.ResNet152_Weights.DEFAULT)
for param in resnet_model.parameters():
param.requires_grad = False
in_features = resnet_model.fc.in_features
resnet_model.fc = nn.Linear(in_features,20)
params_to_update = []
for param in resnet_model.parameters():
if param.requires_grad == True:
params_to_update.append(param)
data_transforms = { #也可以使用PIL库,smote 人工拟合出来数据
'train':
transforms.Compose([
transforms.Resize([300,300]), #是图像变换大小
transforms.RandomRotation(45),#随机旋转,-45到45度之间随机选
transforms.CenterCrop(256),#从中心开始裁剪[256,256]
transforms.RandomHorizontalFlip(p=0.5),#随机水平翻转 选择一个概率概率
transforms.RandomVerticalFlip(p=0.5),#随机垂直翻转
transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),#参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相
transforms.RandomGrayscale(p=0.1),#概率转换成灰度率,3通道就是R=G=B
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#标准化,均值,标准差
]),
'valid':
transforms.Compose([
transforms.Resize([256,256]),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
#做了数据增强不代表 训练效果一定会变好,只能说大概率上会变好
class food_dataset(Dataset): #food_dataset是自己创建的类名称,可以改为你需要的名称
def __init__(self, file_path,transform=None): #类的初始化
self.file_path = file_path
self.imgs = []
self.labels = []
self.transform = transform
with open(self.file_path) as f:
samples = [x.strip().split(' ') for x in f.readlines()]
for img_path, label in samples:
self.imgs.append(img_path)
self.labels.append(label)
def __len__(self): #类实例化对象后,可以使用len函数测量对象的个数
return len(self.imgs)
def __getitem__(self, idx): #关键,可通过索引的形式获取每一个图片数据及标签
image = Image.open(self.imgs[idx]) #
if self.transform:
image = self.transform(image)
label = self.labels[idx]
label = torch.from_numpy(np.array(label,dtype = np.int64))
return image, label
training_data = food_dataset(file_path = 'train.txt',transform = data_transforms['train'])
test_data = food_dataset(file_path = 'test.txt',transform = data_transforms['valid'])
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True) # 64张图片为一个包,
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
'''展示训练数据集中的图片'''
# from matplotlib import pyplot as plt
# image, label = iter(train_dataloader).__next__() #iter是一个迭代器函数。__next__()用于获取下一个数据
# sample = image[2] #image
# sample = sample.permute((1, 2, 0)).numpy() #tensor数据的维度转换
# plt.imshow(sample)
# plt.show()
# print('Label is: {}'.format(label[2].numpy()))
'''-------------cnn卷积神经网络部分----------------------'''
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")
model = resnet_model.to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params_to_update,lr=0.001)
#optimizer = torch.optim.Adam(model.parameters(), lr=0.01)#创建一个优化器,SGD为随机梯度下降算法??
#scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=25,gamma=0.5)
''' 定义神经网络 '''
from torch import nn
class CNN(nn.Module):
def __init__(self): # 输入大小 (3, 256, 256)
super(CNN, self).__init__()
self.conv1 = nn.Sequential( #将多个层组合成一起。
nn.Conv2d( #2d一般用于图像,3d用于视频数据(多一个时间维度),1d一般用于结构化的序列数据
in_channels=3, # 图像通道个数,1表示灰度图(确定了卷积核 组中的个数),
out_channels=16,# 要得到几多少个特征图,卷积核的个数
kernel_size = 5, # 卷积核大小,5*5
stride=1, # 步长
padding=2, # 一般希望卷积核处理后的结果大小与处理前的数据大小相同,效果会比较好。那padding改如何设计呢?建议stride为1,kernel_size = 2*padding+1
), # 输出的特征图为 (16, 256, 256)
nn.ReLU(), # relu层
nn.MaxPool2d(kernel_size=2), # 进行池化操作(2x2 区域), 输出结果为: (16, 128, 128)
)
self.conv2 = nn.Sequential( #输入 (16, 128, 128)
nn.Conv2d(16, 32, 5, 1, 2), # 输出 (32, 128, 128)
nn.ReLU(), # relu层
nn.Conv2d(32, 32, 5, 1, 2), # 输出 (32, 128, 128)
nn.ReLU(),
nn.MaxPool2d(2), # 输出 (32, 64, 64)
)
self.conv3 = nn.Sequential( #输入 (32, 64, 64)
nn.Conv2d(32, 64, 5, 1, 2),
nn.ReLU(), # 输出 (64, 64, 64)
)
self.out = nn.Linear(64 * 64 * 64, 20) # 全连接层得到的结果
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)# 输出 (64,64, 32, 32)
x = x.view(x.size(0), -1) # flatten操作,结果为:(batch_size, 64 * 32 * 32)
output = self.out(x)
return output
#model = CNN().to(device)
#print(model)
def train(dataloader, model, loss_fn, optimizer):
model.train()
#pytorch提供2种方式来切换训练和测试的模式,分别是:model.train() 和 model.eval()。
# 一般用法是:在训练开始之前写上model.trian(),在测试时写上 model.eval() 。
# batch_size_num = 1
for X, y in dataloader: #其中batch为每一个数据的编号
X, y = X.to(device), y.to(device) #把训练数据集和标签传入cpu或GPU
pred = model.forward(X) #自动初始化 w权值
loss = loss_fn(pred, y) #通过交叉熵损失函数计算损失值loss
# Backpropagation 进来一个batch的数据,计算一次梯度,更新一次网络
optimizer.zero_grad() #梯度值清零
loss.backward() #反向传播计算得到每个参数的梯度值
optimizer.step() #根据梯度更新网络参数
# loss = loss.item() #获取损失值
# print(f"loss: {loss:>7f} [number:{batch_size_num}]")
# batch_size_num += 1
best_acc = 0
def test(dataloader, model, loss_fn):
global best_acc
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval() #
test_loss, correct = 0, 0
with torch.no_grad(): #一个上下文管理器,关闭梯度计算。当你确认不会调用Tensor.backward()的时候。这可以减少计算所用内存消耗。
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model.forward(X)
test_loss += loss_fn(pred, y).item() #
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
#a = (pred.argmax(1) == y) #dim=1表示每一行中的最大值对应的索引号,dim=0表示每一列中的最大值对应的索引号
#b = (pred.argmax(1) == y).type(torch.float)
test_loss /= num_batches
correct /= size
print(f"Test result: \n Accuracy: {(100*correct)}%, Avg loss: {test_loss}")
acc_s.append(correct)
loss_s.append(test_loss)
if correct > best_acc:
best_acc = correct
#loss_fn = nn.CrossEntropyLoss() #创建交叉熵损失函数对象,因为手写字识别中一共有10个数字,输出会有10个结果
#optimizer = torch.optim.Adam(model.parameters(), lr=0.01)#创建一个优化器,SGD为随机梯度下降算法??
#scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=25,gamma=0.5)
'''训练模型'''
epochs = 20
acc_s = []
loss_s = []
for t in range(epochs):
start_time = time.time()
# train_dataloader = DataLoader(training_data,batch_size=64,shuffle=True)
# test_dataloader = DataLoader(test_data,batch_size=64,shuffle=True)
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)
#scheduler.step()
end_time = time.time()
time_diff = end_time - start_time
print("时间差:", time_diff)
print()
测试结果如下:
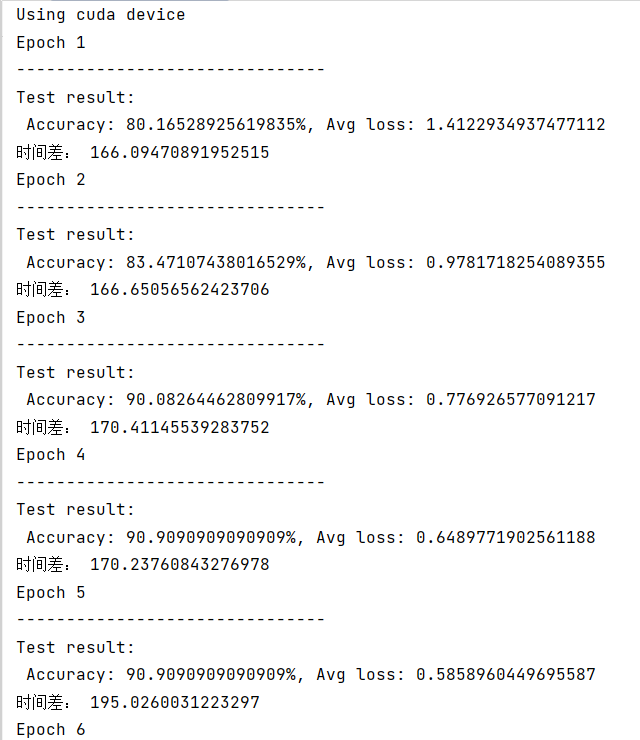
具体的测试结果以个人需要为基准,以上仅供参考!
三、总结
ResNet152作为深度残差网络的代表模型,通过残差块、批归一化和多层级结构等技术,实现了高效的特征学习和模型优化。它在各种计算机视觉任务中都取得了显著的性能提升。

















 5179
5179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









