










1.论文背景
在这篇论文之前,几乎所有的文本分类技术都是基于单词的,在这篇论文中,作者把字符级的文本当做原始的信号输入。
这篇论文,仅仅使用字符,运用在卷积神经网络上。作者发现,当训练大规模数据集的时候,深度卷积神经网络并不需要单词层面的意义(包括语言的语法和语义)。这是非常激动人心的工程简化,因为不管什么语言,它都是由字符组成的,因此这对于构建跨语言的系统至关重要。还有一个好处,对于异常的字符组成(比如拼写错误)和表情符,该模型依然能够应付。
2.论文动机
以字符作为输入和以词作为输入相比,词向量的维度更小,因为单词是无限的,但是字符是有限的。可以很好的解决维度太大的问题。
这里值得一提的是这篇论文的实验结果并不是在所有数据集上完全比其他方法更好,它最大的贡献是提供了这种以字符作为输入的方法,为以后的研究提供了新的思路。
3.模型设计

论文中模型有6个卷积层和三个池化层,这个模型图一眼看去不是很好理解,我将在下面逐渐介绍。
3.1构建字母表和向量化
首先构建字母表,包含70个字符,其中26个英文字母,10个数字,33个其他字符和一个全零向量(用于表示unknow字符):
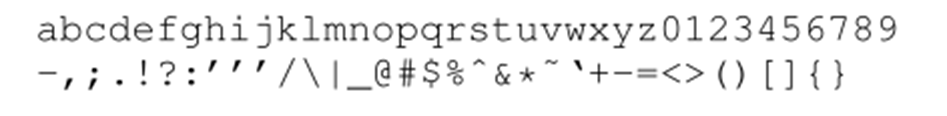
输入字符序列,采用one-hot编码,转换为长度为1014的向量序列,超过1014的字符都被忽略。one-hot编码举例如下:

3.2卷积和池化操作
论文中第三四五次卷积后是不接池化层的,输入的向量长度是1014,论文中提到一个公式:l6=(l0-96)/27
我对这个公式进行了具体的计算,经过六次卷积和三次池化后,长度为34,具体计算如下图。

论文总有两个模型,一个large一个small,large的通道数是1024,small的通道数是256,以small为例,全部通道的实现过程如下图所示:

4.结论
传统方法在十万级的训练集上传统方法表现更好,当上百万的训练集上char cnn表现更好。
char cnn不仅可以不依靠句法信息和语义信息,甚至连词的信息都不需要。十分方便工程实现,因为不管干什么语言都是最终以字符为单位的,还有一个好处就是对于拼写错误和特殊符号表情等有更好的鲁棒性。
字符级的卷积网络是一个有效的方法。 模型如何很好地进行比较,这取决于许多因素,比如数据集的大小,以及对字母表的选择。
5.自己的一点看法和感想
其实这篇论文的思路很明确,在更早的时候就把CNN用在了文本处理上(TextCNN),不过都是以词作为输入的,这里提出了以字符为输入的CNN网络模型,尤其在英文中,字符的数量有限,可以取得还不错的效果。在中文中,我觉得最大的难点是字符表的构建,因为中文中的字就有很多,所以,我觉得它更适合用于特定领域,先去构建特定领域的字符表,然后再进行分类,也有可能取得一定的效果。














 1723
1723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









