






KL散度(Kullback-Leibler Divergence)介绍及详细公式推导
发表于 2019-05-22 | 更新于 2019-05-26 | 分类于 Deep Learning , Math | 阅读次数:
本文字数: 11k | 阅读时长 ≈ 10 分钟
KL散度简介
KL散度的概念来源于概率论和信息论中。KL散度又被称为:相对熵、互熵、鉴别信息、Kullback熵、Kullback-Leible散度(即KL散度的简写)。在机器学习、深度学习领域中,KL散度被广泛运用于变分自编码器中(Variational AutoEncoder,简称VAE)、EM算法、GAN网络中。
KL散度定义
KL散度的定义是建立在熵(Entropy)的基础上的。此处以离散随机变量为例,先给出熵的定义,再给定KL散度定义。
若一个离散随机变量XX的可能取值为X={x1,x2,⋯,xn}X={x1,x2,⋯,xn},而对应的概率为pi=p(X=xi)pi=p(X=xi),则随机变量XX的熵定义为:
H(X)=−∑i=1np(xi)logp(xi)H(X)=−∑i=1np(xi)logp(xi)
规定当p(xi)=0p(xi)=0时,p(xi)logp(xi)=0p(xi)logp(xi)=0
若有两个随机变量P、QP、Q,且其概率分布分别为p(x)、q(x)p(x)、q(x),则pp相对qq的相对熵为:
DKL(p||q)=∑i=1np(x)logp(x)q(x)DKL(p||q)=∑i=1np(x)logp(x)q(x)
之所以称之为相对熵,是因为其可以通过两随机变量的交叉熵(Cross-Entropy)以及信息熵推导得到:
针对上述离散变量的概率分布p(x)、q(x)p(x)、q(x)而言,其交叉熵定义为:
H(p,q)==∑xp(x)log1q(x)−∑xp(x)logq(x)H(p,q)=∑xp(x)log1q(x)=−∑xp(x)logq(x)
在信息论中,交叉熵可认为是对预测分布q(x)q(x)用真实分布p(x)p(x)来进行编码时所需要的信息量大小。
因此,KL散度或相对熵可通过下式得出:
DKL(p||q)====H(p,q)−H(p)−∑xp(x)logq(x)−∑x−p(x)logp(x)−∑xp(x)(logq(x)−logp(x))−∑xp(x)logq(x)p(x)DKL(p||q)=H(p,q)−H(p)=−∑xp(x)logq(x)−∑x−p(x)logp(x)=−∑xp(x)(logq(x)−logp(x))=−∑xp(x)logq(x)p(x)
KL散度的数学性质
KL散度可以用来衡量两个分布之间的差异,其具有如下数学性质:
正定性
DKL(p||q)≥0DKL(p||q)≥0
可用Gibbs 不等式直接得出。先给出Gibbs不等式的内容:
若∑ni=1pi=∑ni=1qi=1∑i=1npi=∑i=1nqi=1,且pi,qi∈(0,1]pi,qi∈(0,1],则有:
−∑inpilogpi≤−∑inpilogqi−∑inpilogpi≤−∑inpilogqi
当且仅当pi=qi∀ipi=qi∀i等号成立。
Gibbs不等式的证明可见后文附录。
不对称性
KL散度并不是一个真正的度量或者距离,因为它不具有对称性:
D(p∥q)≠D(q∥p)D(p‖q)≠D(q‖p)
各种散度中,Jensen-Shannon divergence(JS散度)是对称的。
对KL散度不对称性的直观解释可见链接。
从不同角度解读KL散度
统计学意义上的KL散度:
在统计学意义上来说,KL散度可以用来衡量两个分布之间的差异程度。若两者差异越小,KL散度越小,反之亦反。当两分布一致时,其KL散度为0。正是因为其可以衡量两个分布之间的差异,所以在VAE、EM、GAN中均有使用到KL散度。
信息论角度的KL散度:
KL散度在信息论中的专业术语为相对熵。其可理解为编码系统对信息进行编码时所需要的平均附加信息量。其中信息量的单位随着计算公式中loglog运算的底数而变化。
- log底数为2:单位为比特(
bit)- log底数为
e:单位为奈特(nat)
若对从统计学角度直观解释KL散度感兴趣,可参阅以下文章:
- 英文版[推荐]:Kullback-Leibler Divergence Explained
- 英文版中文翻译[推荐]: 解释Kullback-Leibler散度
- 中文版:直观解读KL散度的数学概念
连续随机变量的KL散度推导
服从一维高斯分布的随机变量KL散度
定义
假设 p 和 q 均是服从N (μ1,σ21)N (μ1,σ12)和N (μ2,σ22)N (μ2,σ22)的随机变量的概率密度函数 (probability density function) ,则从 q 到 p 的KL散度定义为:
DKL(p||q)==∫[log(p(x))−log(q(x))]p(x) dx∫[ p(x)log(p(x))−p(x)log(q(x))] dxDKL(p||q)=∫[log(p(x))−log(q(x))]p(x) dx=∫[ p(x)log(p(x))−p(x)log(q(x))] dx
已知正态分布的概率密度函数(probability density function)如下式:
p(x)=12π−−√σ1exp(−(x−μ1)22σ21)q(x)=12π−−√σ2exp(−(x−μ2)22σ22)p(x)=12πσ1exp(−(x−μ1)22σ12)q(x)=12πσ2exp(−(x−μ2)22σ22)
KL散度推导
根据KLKL散度公式可以将其分为两项进行计算,第一项∫p(x)log(p(x))dx∫p(x)log(p(x))dx计算如下:
∫p(x)log(p(x))dx======∫p(x)log[12π−−√σ1exp(−(x−μ1)22σ21)]dx∫p(x)[log12π−−√σ1+logexp(−(x−μ1)22σ21)]dx−12log(2πσ21)+∫p(x)(−(x−μ1)22σ21)dx−12log(2πσ21)−∫p(x)x2dx−∫p(x)2xμ1dx+∫p(x)μ21dx2σ21−12log(2πσ21)−(μ21+σ21) −(2μ1×μ1) +μ212σ21−12[1+log(2πσ21)]∫p(x)log(p(x))dx=∫p(x)log[12πσ1exp(−(x−μ1)22σ12)]dx=∫p(x)[log12πσ1+logexp(−(x−μ1)22σ12)]dx=−12log(2πσ12)+∫p(x)(−(x−μ1)22σ12)dx=−12log(2πσ12)−∫p(x)x2dx−∫p(x)2xμ1dx+∫p(x)μ12dx2σ12=−12log(2πσ12)−(μ12+σ12) −(2μ1×μ1) +μ122σ12=−12[1+log(2πσ12)]
第二项可以同第一项按照类似的方式进行展开化简,如下:
∫p(x)log(q(x))dx======∫p(x)log[12π−−√σ2exp(−(x−μ2)22σ22)]dx∫p(x)[log12π−−√σ2+logexp(−(x−μ2)22σ22)]dx−12log(2πσ22)+∫p(x)(−(x−μ2)22σ22)dx−12log(2πσ22)−∫p(x)x2dx−∫p(x)2xμ2dx+∫p(x)μ22dx2σ22−12log(2πσ22)−(μ21+σ21) −(2μ2×μ1) +μ222σ22−12log(2πσ22)−σ21 +(μ1−μ2)22σ22∫p(x)log(q(x))dx=∫p(x)log[12πσ2exp(−(x−μ2)22σ22)]dx=∫p(x)[log12πσ2+logexp(−(x−μ2)22σ22)]dx=−12log(2πσ22)+∫p(x)(−(x−μ2)22σ22)dx=−12log(2πσ22)−∫p(x)x2dx−∫p(x)2xμ2dx+∫p(x)μ22dx2σ22=−12log(2πσ22)−(μ12+σ12) −(2μ2×μ1) +μ222σ22=−12log(2πσ22)−σ12 +(μ1−μ2)22σ22
所以可以简化KL散度公式如下:
KL(p,q)===∫[ p(x)log(p(x))−p(x)log(q(x))] dx−12[1+log(2πσ21)]−[−12log(2πσ22)−σ21 +(μ1−μ2)22σ22] logσ2σ1 +σ21 +(μ1−μ2)22σ22 −12KL(p,q)=∫[ p(x)log(p(x))−p(x)log(q(x))] dx=−12[1+log(2πσ12)]−[−12log(2πσ22)−σ12 +(μ1−μ2)22σ22]= logσ2σ1 +σ12 +(μ1−μ2)22σ22 −12
服从多元高斯分布的随机变量KL散度
定义
其定义与一元高斯分布假设下一致,只是 p 和 q 服从的分布形式产生了改变:
p(x)∼N (μ1,Σ21)=1(2π)n/2|Σ1|1/2exp(−12(x−μ1)TΣ−11(x−μ1))p(x)∼N (μ1,Σ12)=1(2π)n/2|Σ1|1/2exp(−12(x−μ1)TΣ1−1(x−μ1))
q(x)∼N (μ2,Σ22)=1(2π)n/2|Σ2|1/2exp(−12(x−μ2)TΣ−12(x−μ2))q(x)∼N (μ2,Σ22)=1(2π)n/2|Σ2|1/2exp(−12(x−μ2)TΣ2−1(x−μ2))
其中:
μ1,μ2∈Rn×1μ1,μ2∈Rn×1
Σ1,Σ2∈Rn×nΣ1,Σ2∈Rn×n
KL散度推导
与一元高斯分布类似,可将DKL(p||q)DKL(p||q)分为两部分:
第一部分:
=====∫p(x)log(p(x))dx∫p(x)log[1(2π)n/2|Σ1|1/2exp(−12(x−μ1)TΣ−11(x−μ1))]dx∫p(x)[log1(2π)n/2|Σ1|1/2+logexp(−12(x−μ1)TΣ−11(x−μ1))]dxlog1(2π)n/2|Σ1|1/2+∫p(x)(−12(x−μ1)TΣ−11(x−μ1))dxlog1(2π)n/2|Σ1|1/2+Ep(x)[−12(x−μ1)TΣ−11(x−μ1)]log1(2π)n/2|Σ1|1/2−12Ep(x)[(x−μ1)TΣ−11(x−μ1)]∫p(x)log(p(x))dx=∫p(x)log[1(2π)n/2|Σ1|1/2exp(−12(x−μ1)TΣ1−1(x−μ1))]dx=∫p(x)[log1(2π)n/2|Σ1|1/2+logexp(−12(x−μ1)TΣ1−1(x−μ1))]dx=log1(2π)n/2|Σ1|1/2+∫p(x)(−12(x−μ1)TΣ1−1(x−μ1))dx=log1(2π)n/2|Σ1|1/2+Ep(x)[−12(x−μ1)TΣ1−1(x−μ1)]=log1(2π)n/2|Σ1|1/2−12Ep(x)[(x−μ1)TΣ1−1(x−μ1)]
同理,第二部分可写为:
=∫p(x)log(q(x))dxlog1(2π)n/2|Σ2|1/2−12Ep(x)[(x−μ2)TΣ−12(x−μ2)]∫p(x)log(q(x))dx=log1(2π)n/2|Σ2|1/2−12Ep(x)[(x−μ2)TΣ2−1(x−μ2)]
因此可将服从多元高斯分布随机变量的KL散度写为:
DKL(p||q)=∫p(x)log(p(x))dx−∫p(x)log(q(x))dx=log(2π)n/2|Σ2|1/2(2π)n/2|Σ1|1/2−12Ep(x)[(x−μ1)TΣ−11(x−μ1)]+12Ep(x)[(x−μ2)TΣ−12(x−μ2)]=12log|Σ2||Σ1|+12Ep(x)[(x−μ2)TΣ−12(x−μ2)−(x−μ1)TΣ−11(x−μ1)]DKL(p||q)=∫p(x)log(p(x))dx−∫p(x)log(q(x))dx=log(2π)n/2|Σ2|1/2(2π)n/2|Σ1|1/2−12Ep(x)[(x−μ1)TΣ1−1(x−μ1)]+12Ep(x)[(x−μ2)TΣ2−1(x−μ2)]=12log|Σ2||Σ1|+12Ep(x)[(x−μ2)TΣ2−1(x−μ2)−(x−μ1)TΣ1−1(x−μ1)]
其中Ep(⋅)Ep(⋅)代表⋅⋅在概率密度函数p(x)p(x)的期望。此处需引入涉及多元变量的期望矩阵化求解方法。具体证明见后续附录,此处直接给出多元正态分布下期望矩阵化的表示结果:
E(xTAx)=tr(AΣ)+μTAμE(xTAx)=tr(AΣ)+μTAμ
因此:
DKL(p||q)=12log|Σ2||Σ1|+12Ep(x)[(x−μ2)TΣ−12(x−μ2)−(x−μ1)TΣ−11(x−μ1)]=12log|Σ2||Σ1|+12tr(Σ−12Σ1)+(μ1−μ2)TΣ−12(μ1−μ2)T−12tr(Σ−11Σ1)+(μ1−μ1)TΣ−12(μ1−μ1)T=12log|Σ2||Σ1|+12tr(Σ−12Σ1)+(μ1−μ2)TΣ−12(μ1−μ2)T−12nDKL(p||q)=12log|Σ2||Σ1|+12Ep(x)[(x−μ2)TΣ2−1(x−μ2)−(x−μ1)TΣ1−1(x−μ1)]=12log|Σ2||Σ1|+12tr(Σ2−1Σ1)+(μ1−μ2)TΣ2−1(μ1−μ2)T−12tr(Σ1−1Σ1)+(μ1−μ1)TΣ2−1(μ1−μ1)T=12log|Σ2||Σ1|+12tr(Σ2−1Σ1)+(μ1−μ2)TΣ2−1(μ1−μ2)T−12n
附录
多元高斯分布下期望证明:
为证明多元高斯分布下,下式:
E(xTAx)=tr(AΣ)+μTAμE(xTAx)=tr(AΣ)+μTAμ
成立,需引入以下性质:
-
矩阵的迹的性质:
tr(αA+βB)tr(A)tr(AB)=αtr(A)+βtr(B)=tr(AT)=tr(BA)⇒tr(ABC)=tr(CAB)=tr(BCA)tr(αA+βB)=αtr(A)+βtr(B)tr(A)=tr(AT)tr(AB)=tr(BA)⇒tr(ABC)=tr(CAB)=tr(BCA)
若λ∈Rn×1λ∈Rn×1,即λλ为列向量时,则λTAλλTAλ为标量,存在以下性质:
λTAλ=tr(λTAλ)=tr(AλλT)λTAλ=tr(λTAλ)=tr(AλλT)
-
多元高斯分布中均值μμ和方差ΣΣ的性质:
-
E[xxT]=Σ+μμTE[xxT]=Σ+μμT:
证明:
Σ∵(A−B)T=AT−BT∴∵x:随机变量μ:const∴=E[(x−μ)(x−μ)T]=E[(x−μ)(xT−μT)]=E[xxT−xμT−μxT−μμT]=E(xxT)−E(x)μT−μE(xT)−μμT=E(xxT)−μμTΣ=E[(x−μ)(x−μ)T]∵(A−B)T=AT−BT∴=E[(x−μ)(xT−μT)]=E[xxT−xμT−μxT−μμT]∵x:随机变量μ:const∴=E(xxT)−E(x)μT−μE(xT)−μμT=E(xxT)−μμT
-
E(xTAx)=tr(AΣ)+μTAμE(xTAx)=tr(AΣ)+μTAμ:
证明:
由于xTAxxTAx最终结果为标量,利用前述矩阵的迹的性质可有:
E(xTAx)∵A=const∴∵E[xxT]=Σ+μμT∴∵μTAμ∈R∴=E[tr(xTAx)]=E[tr(AxxT)]=tr[E(AxxT)]=tr[AE(xxT)]=tr[A(Σ+uuT)]=tr(AΣ)+tr(AμμT)=tr(AΣ)+tr(μTAμ)=tr(AΣ)+μTAμE(xTAx)=E[tr(xTAx)]=E[tr(AxxT)]=tr[E(AxxT)]=tr[AE(xxT)]∵A=const∴=tr[A(Σ+uuT)]∵E[xxT]=Σ+μμT∴=tr(AΣ)+tr(AμμT)=tr(AΣ)+tr(μTAμ)∵μTAμ∈R∴=tr(AΣ)+μTAμ
-
Gibbs不等式的证明
Gibbs不等式的内容如下:
若∑ni=1pi=∑ni=1qi=1∑i=1npi=∑i=1nqi=1,且pi,qi∈(0,1]pi,qi∈(0,1],则有:
−∑inpilogpi≤−∑inpilogqi−∑inpilogpi≤−∑inpilogqi
当且仅当pi=qi∀ipi=qi∀i等号成立。
Gibbs不等式等价于下式:
0≥∑i=1npilogqi−∑i=1npilogpi=∑i=1npilogqipi=−DKL(P∥Q)0≥∑i=1npilogqi−∑i=1npilogpi=∑i=1npilogqipi=−DKL(P‖Q)
以下证明∑ni=1pilog(qi/pi)≤0∑i=1npilog(qi/pi)≤0:
法一:
已知ln(x)≤x−1ln(x)≤x−1,如下图所示:
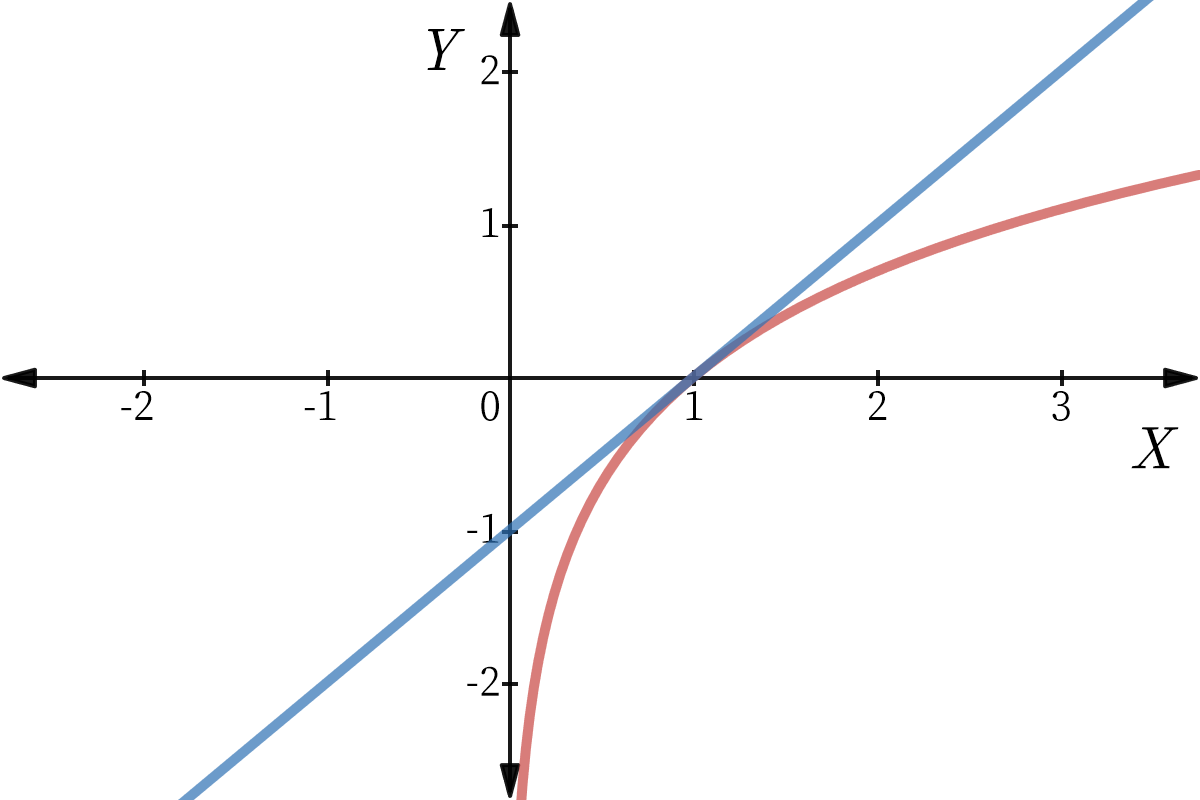
由上图或者严格数学证明可知,当且仅当x=1x=1时ln(x)=x−1ln(x)=x−1,即等号成立。
法二:
根据Jensen不等式在凸积分中的命题:
若gg是任意实值可测函数,ϕϕ在gg的值域中是凸函数,则:
ϕ(∫+∞−∞g(x)f(x)dx)≤∫+∞−∞ϕ(g(x))f(x)dxϕ(∫−∞+∞g(x)f(x)dx)≤∫−∞+∞ϕ(g(x))f(x)dx
若g(x)=xg(x)=x,则上式可简化为一常用特例:
ϕ(∫+∞−∞xf(x)dx)≤∫+∞−∞ϕ(x)f(x)dxϕ(∫−∞+∞xf(x)dx)≤∫−∞+∞ϕ(x)f(x)dx
因此:
DKL(p∥q)=−∫p(x)logq(x)p(x)dx≥−log∫q(x)dx=0DKL(p‖q)=−∫p(x)logq(x)p(x)dx≥−log∫q(x)dx=0
其中DKL(p|q)DKL(p|q)与Jensen不等式有以下对应关系:
ϕ(x)=log(x)f(x)=p(x)ϕ(x)=log(x)f(x)=p(x)
由此得证。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









