







概述
3d Objectron是一种适用于日常物品的移动实时3D物体检测解决方案。它可以检测2D图像中的物体,并通过在Objectron数据集上训练的机器学习(ML)模型估计它们的姿态.
下图为模型训练后推理的结果!

算法
我们建立了两个机器学习管道来从单个RGB图像预测物体的3D边界框:一个是两阶段管道,另一个是单阶段管道。两阶段管道比单阶段管道快3倍,准确率相似或更好。单阶段管道擅长检测多个物体,而两阶段管道适用于单个主导物体。
单价段训练模型:
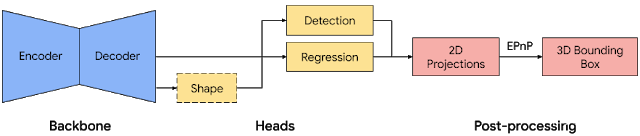
我们的单级流技术路线图,如图所示,模型骨干具有基于MobileNetv2的编码器-解码器架构。我们采用多任务学习方法,同时预测物体的形状、检测和回归。形状任务根据可用的真实注释,例如分割,预测物体的形状信号。如果在训练数据中没有形状注释,则此步骤是可选的。对于检测任务,我们使用注释的边界框并适合高斯到盒子,其中心在盒子重心处,标准偏差与盒子大小成比例。检测的目标是预测具有峰值表示物体中心位置的此分布。回归任务估计八个边界框顶点的二维投影。为了获得边界框的最终3D坐标,我们利用了一个成熟的姿态估计算法(EPnP)。它可以恢复物体的3D边界框,而不需要先验知识。给定3D边界框,我们可以轻松地计算物体的姿态和大小。该模型足够轻,可以在移动设备上实时运行(在Adreno 650移动GPU上以26 FPS的速度运行)。
主要代码和结果
结果:

获取现实世界的3D训练数据
尽管由于自动驾驶汽车依赖于3D捕捉传感器(如LIDAR)的研究的流行,有大量的街景3D数据可用,但是对于更精细的日常物品的具有真实3D标注的数据集非常有限。为了解决这个问题,我们开发了一种新颖的数据管道,利用移动增强现实(AR)会话数据。随着ARCore和ARKit的到来,数亿部智能手机现在具有AR功能,并且能够在AR会话期间捕获附加信息,包括相机姿态、稀疏3D点云、估计的照明和平面表面。
为了标注地面真实数据,我们构建了一个新颖的注释工具,可用于AR会话数据,允许注释者快速为物体标注3D边界框。此工具使用分屏视图,在左侧显示覆盖了3D边界框的2D视频帧,以及在右侧显示3D点云、相机位置和检测到的平面的视图。注释者在3D视图中绘制3D边界框,并通过检查2D视频帧的投影来验证其位置。对于静态对象,我们只需要在一个帧中标注一个对象,并使用AR会话数据的地面真实相机姿态信息将其传播到所有帧,这使得该过程高效。
主要代码:
with mp_objectron.Objectron(static_image_mode=True,
max_num_objects=5,
min_detection_confidence=0.5,
model_name='Shoe') as objectron:
for idx, file in enumerate(IMAGE_FILES):
image = cv2.imread(file)
##全部代码请联系---------->qq1309399183<-----------------------
# Convert the BGR image to RGB and process it with MediaPipe Objectron.
results = objectron.process(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
if not results.detected_objects:
print(f'No box landmarks detected on {file}')
continue
print(f'Box landmarks of {file}:')
annotated_image = image.copy()
for detected_object in results.detected_objects:
mp_drawing.draw_landmarks(
annotated_image, detected_object.landmarks_2d, mp_objectron.BOX_CONNECTIONS)
mp_drawing.draw_axis(annotated_image, detected_object.rotation,
detected_object.translation)
cv2.imwrite('/tmp/annotated_image' + str(idx) + '.png', annotated_image)
全部代码可交流私信
主要讲解:主要调用库函数,然后可以对视频流或者读取电脑摄像头,真正做到方便实用,高效快捷,实时显示结果 实施输出模型,可以毕业设计用。

















 3830
3830











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











