




图神经网络GNN学习笔记:表示学习
如果有一类方法可以 自动地从数据中去学习“有用”的特征,并可以直接用于后续的具体任务,这类方法称为
表示学习。
1. 表示学习
1.1 表示学习的意义
传统机器学习中,需要在数据处理和转换上花费大量精力才能保证特征工程选取的特征使得机器学习算法更有效。如果存在一种可以从数据中得到有判别性特征的方法,就会减少机器学习算法对特征工程的依赖。从而可以将机器学习应用到更多的领域,这就是表示学习的价值。
那么对于表示学习来说,要回答3个问题:
(1)如何判断一个表示比另一个表示更好?
(2)如何挖掘这些表示?
(3)使用什么样的目标去得到一个好的表示?
举一个例子就是一个图像,计算机能够得到的知识一个个像素点这样的原始数据,只关注像素点是无法得到一些具体信息的;而人在看到一个图像的时候自然会通过高层的抽象语义来判断,这之间的差距称为语义鸿沟,它指的是低层次特征和高层次抽象之间的差异。一个好的表示就应该尽可能减小这个语义鸿沟,提供一些高层次的有价值的特征。
1.2 离散表示与分布式表示
机器学习中,对一个对象的表示有两种常见的方式:独热编码(one-hot)和分布式表示。
- 独热码将研究的对象表示成一个向量,只在某个维度上为1,其余全为0。有多少种类型,向量的长度就有多长。举例:自然语言处理中的词袋模型
- 分布式表示就是通过某种方式得到一个低维稠密的向量来表示研究对象,典型的例子就是颜色,可以用RGB值的三元组来表示。
独热码表示起来非常简单,只需要列出所有可能的值就可以得到,但它会使得所有不同的表示都是相互独立(正交)的,这会让它表示起来丢失大量的语义信息,此外独热向量的维度可能非常高且非常稀疏。
而分布式表示就能够保留这些语义信息,而且维度可以很低,当然相应的也会比独热码实现起来更复杂一点。
1.3 端到端学习是一种强大的表示学习方法
所谓端到端学习(end-to-end learning)就是以原始输入作为输入,并直接输出想要得到结果(比如分类)。相应的,传统的机器学习模型中,一些工作都是先处理输入,通过特征工程提取出特征,之后再交由分类器进行判断。
由此端到端学习可以看作是表示学习与任务学习的结合(提取特征+分类),它们不是完全分裂的,而是联合优化的,一次反向传播更新的不只是基于特征给出分类结果的参数,还更新了提取特征的参数使得整个模型的效果会更好,这体现了深度学习模型的优越性。
深度学习模型另一个优势是能够学习到数据的层次化表达。低层次的特征更加通用,高层次的特征则更贴近具体任务,所以对于一些比较相近的任务,其实是可以使用相同的低层次特征的,这让深度学习可以进行迁移学习。
表示学习的任务通常是学习这样一个映射:
f
:
X
→
R
d
f:X\rightarrow R^d
f:X→Rd,即将输入映射到一个稠密的低维向量空间中。这里介绍两种典型的表示学习方法:基于重构损失的方法和基于对比损失的方法。
2. 基于重构损失的方法——自编码器
自编码器是一种无监督的表示学习模型,以输入数据为参考,可以用于数据降维和特征提取。
2.1 自编码器
自编码器的思路是:将输入映射到某个特征空间,再从这个特征空间映射回输入空间进行重构。结构上看它由编码器和解码器组成,编码器用于从输入中提取特征,解码器则用于从特征重构出输入数据。在训练完成后,使用编码器进行特征提取。

最简单的自编码器有3层组成:1个输入层、1个隐藏层、1个输出层。从输入到隐藏层就是编码器,从隐藏层到输出层就是解码器。
给定输入
x
∈
R
n
x\in R^n
x∈Rn,假设从输入层到隐藏层的变换矩阵为
W
e
n
c
∈
R
d
×
n
W_{enc}\in R^{d\times n}
Wenc∈Rd×n,
d
d
d为隐藏层的神经元数目,经过变换
h
=
σ
(
W
e
n
c
x
+
b
e
n
c
)
h=\sigma (W_{enc}x+b_{enc})
h=σ(Wencx+benc)得到编码后的特征为
h
∈
R
d
h\in R^{d}
h∈Rd。解码器将编码特征
h
h
h映射回输入空间,假设从隐藏层到输出层的编码矩阵为
W
d
e
c
∈
R
n
×
d
W_{dec}\in R^{n\times d}
Wdec∈Rn×d,经过变换
x
~
=
σ
(
W
d
e
c
h
+
b
d
e
c
)
\tilde{x}=\sigma(W_{dec}h+b_{dec})
x~=σ(Wdech+bdec)得到重构的输入为
x
~
\tilde{x}
x~。
自编码器不需要额外的标签信息进行监督学习,它是通过不断最小化输入和输出之间的重构误差进行训练的。基于损失函数 L = 1 N ∑ i ∣ ∣ x i − x i ~ ∣ ∣ 2 2 L=\frac{1}{N} \sum_i {||x_i-\tilde{x_i}||_2^2} L=N1i∑∣∣xi−xi~∣∣22,通过反向传播计算梯度,利用梯度下降算法不断优化参数 W e n c , W d e c , b e n c , b d e c W_{enc},W_{dec},b_{enc},b_{dec} Wenc,Wdec,benc,bdec。
一般来说编码器的结构不局限于只有一个隐藏层的全连接网络,一般来说,编码器和解码器可以是更复杂的模型,分别用 f f f和 g g g来表示,损失函数可以表示为 L = 1 N ∑ i ∣ ∣ x i − g ( f ( x i ) ) ∣ ∣ 2 2 L=\frac{1}{N}\sum_i {||x_i-g(f(x_i))||_2^2} L=N1i∑∣∣xi−g(f(xi))∣∣22,其中N为样本数量。
通过训练编码器得到数据中的一些有用特征,最常用的一种方式是通过限定
h
h
h的维度比
x
x
x的维度小,即
d
<
n
d<n
d<n,符合这种条件的编码器称为欠完备自编码器。这种自编码器在一定的条件下可以得到类似于主成分分析(PCA)的效果。使用非线性的编码器和解码器可以得到更强大的效果。
比较容易混淆的一点是:这个自编码器先编码再解码,最后得到的不还是原始输入或者逼近原始输入的东西吗?所以要特别注意,自编码器训练完后,是直接拿输入过一个编码器进行特征提取再放到后面的神经网络里去的,解码器就用不到了,有种GAN的思想。
2.2 正则自编码器
如果编码器的维度大于等于输入的维度
d
≥
n
d\ge n
d≥n,那么就被称为过完备自编码器。如果不对过完备自编码器进行一些限制,那么其可能会更倾向于将输入拷贝到输出,从而得不到特征。因此通常会对模型进行一些正则化的约束。
2.2.1 去噪自编码器
去噪自编码器的改进在于在原始输入的基础上加入了一些噪声作为编码器的输入。解码器需要重构出不加噪声的原始输入
x
x
x,通过施加这个约束,迫使编码器不能简单地学习一个恒等变换,而必须从加噪的数据中提取出有用信息用于恢复原始数据。
具体做法是:随机将输入x的一部分置为0,这样就得到了加入噪声的输入
x
δ
x_\delta
xδ作为编码器的输入,解码器需要重构出不带噪声的数据x,因此损失函数为:
L
=
1
N
∑
i
=
1
∣
∣
x
−
g
(
f
(
x
δ
)
)
∣
∣
L=\frac{1}{N}\sum_{i=1}||x-g(f(x_\delta))||
L=N1i=1∑∣∣x−g(f(xδ))∣∣
2.2.2 稀疏自编码器
在损失函数上加入正则项使得模型学习到有用的特征,比如隐藏层使用Sigmoid激活函数,我们认为神经元的输出接近1时是活跃的,而接近0时是不活跃的,稀疏自编码器就是限制神经元的活跃度来约束模型,尽可能使大多数神经元处于不活跃的状态。
定义一个神经元的活跃度为它在所有样本上取值的平均值,用
ρ
i
^
\hat{\rho_i}
ρi^表示。限制
ρ
i
^
=
ρ
i
\hat{\rho_i}=\rho_i
ρi^=ρi,
ρ
i
\rho_i
ρi是一个超参数,表示期望的活跃度,通常是一个接近于0的值。通过对与
ρ
i
\rho_i
ρi偏离较大的神经元进行惩罚,就可以得到稀疏的编码特征。这里选择使用相对熵作为正则项,如下:
L
s
p
a
r
s
e
=
∑
j
=
1
d
ρ
log
ρ
ρ
j
^
+
(
1
−
ρ
)
log
1
−
ρ
1
−
ρ
j
^
L_{sparse}=\sum_{j=1}^{d}\rho\log{\frac{\rho}{\hat{\rho_j}}}+(1-\rho)\log{\frac{1-\rho}{1-\hat{\rho_j}}}
Lsparse=j=1∑dρlogρj^ρ+(1−ρ)log1−ρj^1−ρ
相对熵可以量化表示两个概率分布之间的差异。当两个分布相差越大时,相对熵值越大;当两个分布完全相同时,相对熵值为0。
加上稀疏项的惩罚后,损失函数变为:
L
=
L
(
x
i
,
g
(
f
(
x
i
)
)
)
+
λ
L
s
p
a
r
s
e
L=L(x_i,g(f(x_i)))+\lambda L_{sparse}
L=L(xi,g(f(xi)))+λLsparse
其中,
λ
\lambda
λ是调节重构项和稀疏正则项的权重。
2.2.3 变分自编码器
变分自编码器可以用于生成新的样本数据。
1.变分自编码器的原理
变分自编码器的本质是生成模型,其假设样本都是服从某个复杂分布
P
(
x
)
P(x)
P(x),即
x
∼
P
(
X
)
x\sim P(X)
x∼P(X),生成模型的目的就是要建模
P
(
X
)
P(X)
P(X),这样就可以从分布中进行采样,得到新的样本数据。
一般来说,每个样本都可能受到一些因素的控制,这些因素称为隐变量。假设有多个隐变量,用向量
z
z
z表示,概率密度函数为
p
(
z
)
p(z)
p(z)。同时有一个函数
f
(
z
:
θ
)
f(z:\theta)
f(z:θ),它可以把
p
(
z
)
p(z)
p(z)中采样的数据
z
z
z映射为与
X
X
X比较相似的数据样本,即
p
(
X
∣
z
)
p(X∣z)
p(X∣z)的概率更高。
引入隐变量后通过
p
(
x
)
=
∫
z
p
(
x
∣
z
)
p
(
z
)
d
z
p(x)=\int_z{p(x|z)p(z)}dz
p(x)=∫zp(x∣z)p(z)dz来求解
p
(
X
)
p(X)
p(X)的分布,这里需要考虑两个问题:
- 如何选定隐变量 z z z
- 如何计算积分
对于隐变量
z
z
z的选择,变分编码器假设
z
z
z的每个维度都没有明确的含义,而仅仅要求z方便采用。因此假设z服从标准正态分布
z
∼
N
0
,
I
z\sim N{0,I}
z∼N0,I。而
p
(
x
∣
z
)
p(x|z)
p(x∣z)的选择常常也是正态分布,它的均值为
f
(
z
;
θ
)
f(z;\theta)
f(z;θ),方差为
σ
2
I
\sigma^2I
σ2I,其中
σ
\sigma
σ是一个超参数。
p
(
x
∣
z
)
=
N
(
f
(
z
;
θ
)
,
σ
2
I
)
p(x|z)=N(f(z;\theta),\sigma^2I)
p(x∣z)=N(f(z;θ),σ2I)
为什么上述假设是合理的呢?实际上任何一个d维的复杂分布都可以通过对d维正态分布使用一个复杂的变换得到,因此,给定一个表达能力足够强的函数,可以将服从正态分布的隐变量z映射为模型需要的隐变量,再将这些隐变量映射为x。
但是大部分的z都不能生成与x相似的样本,即
p
(
x
∣
z
)
p(x|z)
p(x∣z)通常都接近于0,因此需要那种能够大概率生成比较像x的z。如何得到呢?如果知道z的后验分布
p
(
z
∣
x
)
p(z|x)
p(z∣x),就可以通过x推断得到。变分自编码器引入了另一个分布
q
(
z
∣
x
)
q(z|x)
q(z∣x)来近似后验分布
p
(
z
∣
x
)
p(z|x)
p(z∣x)。那么问题是
E
z
∼
q
(
z
∣
x
)
[
p
(
x
∣
z
)
]
E_{z\sim q(z|x)}[p(x|z)]
Ez∼q(z∣x)[p(x∣z)]与
p
(
x
)
p(x)
p(x)的关系是怎么样的?这里计算
q
(
z
∣
x
)
q(z|x)
q(z∣x)和
p
(
z
∣
x
)
p(z|x)
p(z∣x)的KL距离,如下:
D
K
L
[
q
(
z
∣
x
)
∣
∣
p
(
z
∣
x
)
]
=
E
z
∼
q
(
z
∣
x
)
[
log
q
(
z
∣
x
)
−
log
p
(
z
∣
x
)
]
D_{KL}[q(z|x)||p(z|x)]=E_{z\sim q(z|x)}[\log q(z|x)-\log p(z|x)]
DKL[q(z∣x)∣∣p(z∣x)]=Ez∼q(z∣x)[logq(z∣x)−logp(z∣x)]
然后使用贝叶斯公式展开,得到如下公式:
D
K
L
[
q
(
z
∣
x
)
∣
∣
p
(
z
∣
x
)
]
=
E
z
∼
q
(
z
∣
x
)
[
log
q
(
z
∣
x
)
−
log
p
(
x
∣
z
)
−
log
p
(
z
)
]
+
log
p
(
x
)
D_{KL}[q(z|x)||p(z|x)]=E_{z\sim q(z|x)}[\log q(z|x)-\log p(x|z)-\log p(z)]+\log p(x)
DKL[q(z∣x)∣∣p(z∣x)]=Ez∼q(z∣x)[logq(z∣x)−logp(x∣z)−logp(z)]+logp(x)
log
p
(
x
)
−
D
K
L
[
q
(
z
∣
x
)
∣
∣
p
(
z
∣
x
)
]
=
E
z
∼
q
(
z
∣
x
)
[
log
(
p
(
x
∣
z
)
)
]
−
D
K
L
[
q
(
z
∣
x
)
∣
∣
p
(
z
)
]
\log p(x)-D_{KL}[q(z|x)||p(z|x)]=E_{z\sim q(z|x)}[\log (p(x|z))]-D_{KL}[q(z|x)||p(z)]
logp(x)−DKL[q(z∣x)∣∣p(z∣x)]=Ez∼q(z∣x)[log(p(x∣z))]−DKL[q(z∣x)∣∣p(z)]
上式即为整个变分自编码器的核心(尽管我没有看懂),左边包含了要优化的目标
p
(
x
)
p(x)
p(x),当我们选择的
q
(
z
∣
x
)
q(z|x)
q(z∣x)表达能力足够强时,是可以近似表达
p
(
z
∣
x
)
p(z|x)
p(z∣x)的。也就是说
D
K
L
[
q
(
z
∣
x
)
∣
∣
p
(
z
∣
x
)
]
D_{KL}[q(z|x)||p(z|x)]
DKL[q(z∣x)∣∣p(z∣x)]是一个趋近于0的数。右边第一项实际上就是一个编码器,将基于输入x得到的最有可能生成相似样本的隐变量采样出来,通过解码器得到生成的样本,右边第二项是一个正则项。
前面假设
p
(
x
∣
z
)
p(x|z)
p(x∣z)是正态分布,那么对于公式
log
p
(
x
)
−
D
K
L
[
q
(
z
∣
x
)
∣
∣
p
(
z
∣
x
)
]
=
E
z
∼
q
(
z
∣
x
)
[
log
(
p
(
x
∣
z
)
)
]
−
D
K
L
[
q
(
z
∣
x
)
∣
∣
p
(
z
)
]
\log p(x)-D_{KL}[q(z|x)||p(z|x)]=E_{z\sim q(z|x)}[\log (p(x|z))]-D_{KL}[q(z|x)||p(z)]
logp(x)−DKL[q(z∣x)∣∣p(z∣x)]=Ez∼q(z∣x)[log(p(x∣z))]−DKL[q(z∣x)∣∣p(z)]右边第一项,计算得到损失函数的第一部分重构损失,注意这里取负号是由于使用梯度下降的方法进行优化,因此目标变为最小化
−
p
(
x
)
-p(x)
−p(x),
f
(
z
;
θ
)
f(z;\theta)
f(z;θ)可以使用神经网络来实现。
−
log
p
(
x
∣
z
)
=
−
log
1
∐
i
=
1
D
2
π
σ
2
exp
(
−
(
x
−
f
(
z
;
θ
)
)
2
2
σ
2
)
=
1
2
σ
2
(
x
−
f
(
z
;
θ
)
)
2
+
c
o
n
s
t
a
n
t
-\log p(x|z)=-\log \frac{1}{\coprod_{i=1}^{D}\sqrt{2\pi \sigma ^2}}\exp (-\frac{(x-f(z;\theta))^2}{2\sigma ^2})=\frac{1}{2\sigma ^2}(x-f(z;\theta ))^2+constant
−logp(x∣z)=−log∐i=1D2πσ21exp(−2σ2(x−f(z;θ))2)=2σ21(x−f(z;θ))2+constant
对于
q
(
z
∣
x
)
q(z|x)
q(z∣x)的选择,也假设服从正态分布,它的各分量相互独立,如公式
D
K
L
[
q
(
z
∣
x
)
∣
∣
p
(
z
)
]
=
1
2
∑
i
=
1
d
(
μ
(
i
)
2
(
x
)
+
σ
(
i
)
2
(
x
)
−
ln
σ
(
i
)
2
(
x
)
−
1
)
D_{KL}[q(z|x)||p(z)]=\frac{1}{2}\sum _{i=1}^d(\mu _{(i)}^2(x)+\sigma _{(i)}^2(x)-\ln \sigma _{(i)}^2(x)-1)
DKL[q(z∣x)∣∣p(z)]=21∑i=1d(μ(i)2(x)+σ(i)2(x)−lnσ(i)2(x)−1)所示,那么可以得到损失函数的第二部分正则项。
q
(
z
∣
x
)
=
1
∐
i
=
1
d
2
π
σ
i
2
(
x
)
exp
(
−
(
z
−
μ
(
x
)
)
2
2
σ
2
(
x
)
)
q(z|x)=\frac{1}{\coprod_{i=1}^{d}\sqrt{2\pi \sigma_i^2(x)}}\exp (-\frac{(z-\mu(x))^2}{2\sigma^2(x)})
q(z∣x)=∐i=1d2πσi2(x)1exp(−2σ2(x)(z−μ(x))2)
根据上述原理,可以得出变分自编码器的结构,如下所示:
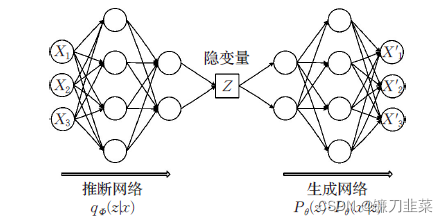
现在的问题是隐变量z是通过采样得到的,而采样操作是不可导的,无法进行反向传播,使用一个称为“重参数化”的技巧解决这个问题。具体地,先从正态分布
N
(
0
,
I
)
N(0,I)
N(0,I)中采样得到
ϵ
\epsilon
ϵ,隐变量
z
z
z通过计算得到
:
z
=
ϵ
μ
(
x
)
+
σ
(
x
)
:z=\epsilon \mu (x)+\sigma (x)
:z=ϵμ(x)+σ(x),这样就解决了反向传播的问题。
2.与自编码器对比
自编码器是一种无监督的表示学习方法,而变分自编码器本质上是生成模型。传统的自编码器的隐藏层空间是不连续的,其由一个个样本点编码构成,对于没有样本编码的地方,由于解码器没有见过这种隐藏层特征,因此当任意给定隐藏层向量时,解码器也就不能给出有意义的输出。而变分自编码器则是要建模样本的分布
p
(
x
)
p(x)
p(x),所以当训练完成后,只使用解码器就可以生成样本。
3. 基于对比损失的方法——Word2vec
Word2vec模型将词嵌入到一个向量空间中,用低维的向量表达每个词,并且语义相关的词距离更近。
3.1 词向量模型——Skip-gram
Word2vec是2013年由Tomas Mikolov提出的,核心思想是用一个词的上下文去刻画这个词。对应的有两种模型:
- 给定某个中心词的上下文去预测中心词,这个模型称为
CBow; - 给定一个中心词预测其上下文词,这个模型称为
Skip-gram;
给定一个语料库,它可以由多篇文档组成,假设该语料库可以表示为一个长度为N的语料库的序列 C = w 1 , w 2 , . . . , w N C={w_1,w_2,...,w_N} C=w1,w2,...,wN,单词的词表为 V V V, w i ∈ V w_i\in V wi∈V。Ship-gram模型使用中心词预测上下文,定义上下文词以中心词为中心的某个窗口内的词,假设窗口的大小为 2 m + 1 2m+1 2m+1。希望在给定某个中心词的条件下,输出词为上下文的概率最大。
如下图所示,对于一个文本,选择中心词“网络”,取
m
=
2
m=2
m=2,以中心词及其上下文词构成的单词对为正样本
D
D
D,由中心词与其非上下文词构成的单词对为负样本,即为
D
ˉ
\bar{D}
Dˉ。如下:
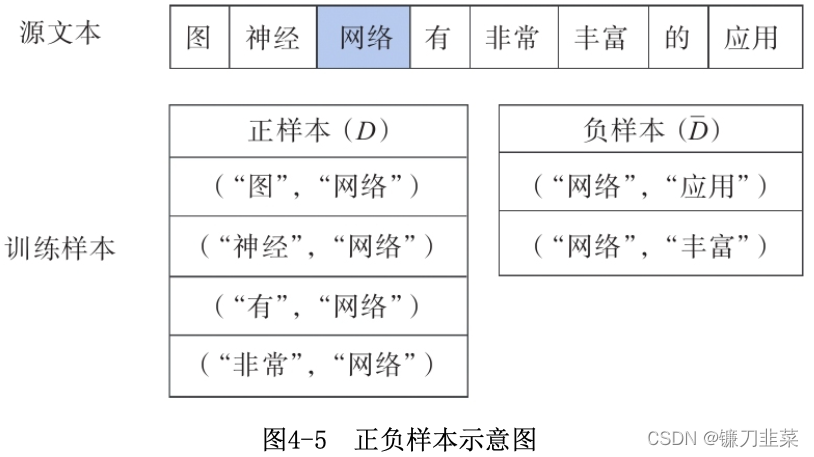
要想正确地根据中心词预测上下文词,那么可以最大化正样本中的单词对作为上下文出现的概率,同时最小化负样本中单词对作为上下文出现的概率,以此构造目标函数。具体来说,对正负样本定义标签,其中
w
c
w_c
wc表示中心词。
KaTeX parse error: Expected '}', got '_' at position 38: …1 & \text{ if(w_̲c, w)}\in D \\ …
目标是找到条件概率
p
(
y
=
1
∣
(
w
c
,
w
)
)
p(y=1|(w_c,w))
p(y=1∣(wc,w))和
p
(
y
=
0
∣
∣
(
w
c
,
w
)
)
p(y=0||(w_c,w))
p(y=0∣∣(wc,w))最大化的参数,如下所示:
θ
∗
=
arg
max
∏
(
w
c
,
w
)
∈
D
p
(
y
=
1
∣
(
w
c
,
w
)
)
∏
(
w
c
,
w
)
∈
D
ˉ
p
(
y
=
0
∣
(
w
c
,
w
n
e
g
)
;
θ
)
\theta^*=\arg\max\prod_{(w_c, w)\in D}{p(y=1|(w_c, w))}\prod_{(w_c, w)\in\bar{D}}{p(y=0|(w_c,w_{neg});\theta)}
θ∗=argmax(wc,w)∈D∏p(y=1∣(wc,w))(wc,w)∈Dˉ∏p(y=0∣(wc,wneg);θ)
这样问题就转化为一个二分类问题。给定任意两个词,判断它们是否是上下文词,因此,可以使用逻辑回归来建模这个问题。引入两个矩阵
U
∈
R
∣
D
∣
×
d
U\in R^{|D|\times d}
U∈R∣D∣×d,
V
∈
R
∣
D
∣
×
d
V\in R^{|D|\times d}
V∈R∣D∣×d,它们中的每一行代表着一个词,在模型训练完成后,它们就是包含语义表达的词向量。
U
、
V
U、V
U、V分别对应一个词作为中心词和上下文词两种角色下的不同表达。对于一个词
w
w
w,定义
U
w
U_w
Uw表示它对应的词向量。那么可以将上面的条件概率公式表示为
p
(
y
∣
(
w
c
,
w
)
)
=
{
σ
(
U
w
c
⋅
V
w
)
if
y
=
1
1
−
σ
(
U
w
c
⋅
V
w
)
if
y
=
0
p(y|(w_c,w))=\begin{cases} \sigma(U_{w_c} \cdot V_w) & \text{ if } y= 1\\ 1-\sigma(U_{w_c} \cdot V_w) & \text{ if } y=0 \end{cases}
p(y∣(wc,w))={σ(Uwc⋅Vw)1−σ(Uwc⋅Vw) if y=1 if y=0,其中
σ
(
x
)
\sigma(x)
σ(x)表示Sigmoid函数。
联合前面得到的公式,取对数,可以得到 L = − ∑ ( w c , w ) ∈ D log σ ( U w c ⋅ V w ) − ∑ ( w c , w ) ∈ D ˉ log ( 1 − σ ( U w c ⋅ V w ) ) = − ∑ ( w c , w ) ∈ D log σ ( U w c ⋅ V w ) − ∑ ( w c , w ) ∈ D ˉ log σ ( − U w c ⋅ V w ) L=-\sum_{(w_c,w)\in D}\log{\sigma(U_{w_c}\cdot V_w)}-\sum_{(w_c,w)\in \bar{D}}\log{(1-\sigma(U_{w_c}\cdot V_w))}=-\sum_{(w_c,w)\in D}\log{\sigma(U_{w_c}\cdot V_w)}-\sum_{(w_c,w)\in \bar{D}}\log{\sigma (-U_{w_c}\cdot V_w)} L=−(wc,w)∈D∑logσ(Uwc⋅Vw)−(wc,w)∈Dˉ∑log(1−σ(Uwc⋅Vw))=−(wc,w)∈D∑logσ(Uwc⋅Vw)−(wc,w)∈Dˉ∑logσ(−Uwc⋅Vw),这就是Skip-gram的目标函数。
上式一方面在增大正样本的概率,另一方面在减少负样本的概率。实际上增大正样本的概率就是在增大
U
w
c
⋅
V
w
U_{w_c}\cdot V_w
Uwc⋅Vw,即中心词与上下文词的内积,也就是它们之间的相似度。也就是说,最小化上式实际上会使得中心词与上下文词之间的距离变小,而与非上下文词之间的距离更大,通过这种方式作为监督信号指导模型进行学习,模型收敛之后,参数矩阵
U
,
V
U,V
U,V就是我们需要的词向量,通常我们取
U
U
U作为最终的词向量。
构建正样本,并最大化正样本之间的相似度,最小化负样本之间的相似度的方式是表示学习中构建损失函数一种常用的思路,这类损失被称为对比损失,它将数据及其邻居在输入空间中的关系仍然能够被保留。不同任务中数据的邻居关系可能是不同的,这里邻居关系是上下文词。比如在人脸识别中,正样本可以定义为同一个体在不同条件下的人脸图像,负样本定义为不同个体的人脸图像,通过对比损失进行优化以学习到具有判别性的特征用于人脸识别。
3.2 负采样
通常情况下负样本的数量远比正样本多,这使得对负样本的计算会成为整体计算的瓶颈。容易想到的解决方案就是负采样技术,就是利用采样的方式来降低计算量,它在我们无法计算所有的负样本或者计算代价过高时,提供了一种降低计算复杂度的方法。使用负采样技术后,对于中心词
w
c
w_c
wc来说,损失函数变为如下
−
log
σ
(
U
w
c
V
w
)
−
∑
i
=
1
n
log
σ
(
−
U
w
c
V
N
E
G
(
w
c
)
i
)
-\log \sigma(U_{w_c} V_w)-\sum_{i=1}^n\log \sigma(-U_{w_c}V_{NEG(w_c)_i})
−logσ(UwcVw)−i=1∑nlogσ(−UwcVNEG(wc)i)
,其中 N E G ( w c ) NEG(w_c) NEG(wc)表示采样得到的与 w c w_c wc构成负样本的词集合,通过负采样将负样本的计算复杂度从 O ( ∣ V ∣ ) O(|V|) O(∣V∣)降至 O ( n ) O(n) O(n),其中 n < < ∣ V ∣ n<<|V| n<<∣V∣。在采样时一般不使用均匀采样,而是采用以词频为权重的带权采样。这种采样方式优化的不仅是词向量的内积,更是词向量的互信息。
3.3 词向量可视化
将学习到的词向量降维到二维空间进行可视化,语义相关或相近的词之间距离更近,语义差别较大的词相距较远。另外,某些词之间存在着一定的平移不变性。
参考资料
[1] 《深入浅出图神经网络:GNN原理解析》
[2] https://blog.csdn.net/Jeff__Fang/article/details/117198924
[3] 一文理解变分自编码器



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











