







 本文介绍了一种基于深度学习的药品外包装识别系统,结合RFID技术和改进的鲸鱼算法与二维最大熵图像分割,使用LeNet-5进行定制化训练,通过数据增强提高模型性能。文章详细描述了项目背景、设计思路、模型训练过程以及优化措施。
本文介绍了一种基于深度学习的药品外包装识别系统,结合RFID技术和改进的鲸鱼算法与二维最大熵图像分割,使用LeNet-5进行定制化训练,通过数据增强提高模型性能。文章详细描述了项目背景、设计思路、模型训练过程以及优化措施。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于深度学习的药品外包装识别系统
项目背景
在药品行业中,准确识别和追踪药品外包装的重要性不言而喻。当前,许多药品识别任务仍然依赖于人工操作,这种方式存在着效率低下、易出错和成本高昂的问题。因此,开发一种基于深度学习的药品外包装识别系统具有重要的背景和意义。这样的系统可以提高药品识别的速度和准确性,为药品监管、溯源追踪以及库存管理等方面带来巨大的便利和效益。
设计思路
RFID射频识别技术是一种常用的智能包装技术,通过在药品包装盒外贴上RFID标签,并通过传感器读取标签内容。该技术可以实现药品追踪、监测和信息可视化,并记录药品在冷链运输和流通过程中的实时状态和位置。相比传统标签,RFID智能标签具有扫描速度快、扫描数量多、体积小、信息安全度高和数据存储量大等优点。在扫描过程中,RFID智能标签可以同时识别多个物品,识别距离可达20米,在药品冷链运输中保证高效率获取信息。这项技术对于监测药品出库和库存情况,并进行可视化设计,对药品供应系统有很大帮助。

鲸鱼算法是一种基于优化的算法,灵感来源于鲸鱼群体的行为。通过改进鲸鱼算法,可以提高其搜索能力和收敛速度,以更好地适应图像分割的需求。二维最大熵图像分割是一种基于信息论的图像分割方法,它通过最大化图像分割后的互信息来实现自适应的分割结果。在药品包装识别系统中,可以利用二维最大熵图像分割来提取药品包装的关键信息和特征,例如药品标签、批号和有效期等。将改进的鲸鱼算法与二维最大熵图像分割相结合,可以实现更准确和高效的药品包装识别。通过优化算法的搜索能力和收敛速度,可以提高分割结果的质量和准确性。
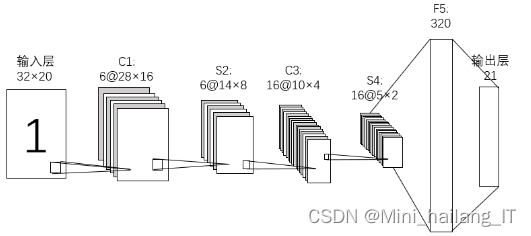
LeNet-5是一种早期经典的神经网络,由计算机科学家Yann LeCun提出,并采用了反向传播算法进行有监督的训练。因其在机器学习等领域的杰出贡献,被誉为卷积神经网络之父。LeNet-5网络在字符识别方面取得了极好的效果,推动了该领域的发展。相对于多层感知机,卷积神经网络的参数数量大大减少,因此在特征提取方面得到广泛应用。LeNet-5的设计和训练方法为后续的卷积神经网络奠定了基础,其结构和思想影响了许多后续的神经网络模型,成为了深度学习和计算机视觉领域的重要里程碑。

对传统的LeNet算法进行改进的内容如下:首先,在输入层将32×32像素大小归一化为32×20,以适应国药准字字符的8:5高宽比,避免字符拉伸变形情况,并减少网络训练参数以提高运算速率。其次,使用ReLU激活函数替代传统LeNet-5网络中的sigmoid函数,以避免易饱和和梯度消失等问题。然后,取消C5层,并将F5层与S4层和输出层进行全连接,减少训练参数并提高运算效率,避免过拟合现象。在优化器方面,采用Adam优化器进行权重更新,相较于随机梯度下降法具有更高的效率和较好的收敛效果。为了防止过拟合,引入Dropout,在F5全连接层中设置失活概率为0.5。最后,在输出层将识别类别分为21类,包括0-9的阿拉伯数字、大写字母"BFHJSTZ"以及"国药准字"4个汉字。这些改进措施可以提高LeNet算法的性能和准确性,适应国药准字识别任务的特点,并减少运算负载,提升计算效率。
数据集
由于网络上没有现有的合适的数据集,我们决定自己进行药品外包装的拍摄和数据集制作。我们前往药品生产企业和药店等地,收集了大量不同类型的药品外包装照片。在拍摄过程中,我们特别关注药品外包装的各种细节和特征,以保证数据集的全面性和准确性。通过现场拍摄,我们能够捕捉到真实的药品外包装样本,包括各种不同药品的不同规格和包装形式。通过这种自制的数据集,我们相信能够为药品外包装识别系统的研究提供更准确、可靠的数据,为该领域的发展做出积极贡献。
为了增加数据集的样本多样性和泛化能力,我们采用了数据扩充技术对收集到的药品外包装图像进行处理。我们使用了旋转、缩放、平移和镜像等操作,并添加了不同的噪声和变换,以增加数据集的样本多样性。通过数据扩充,我们能够训练出更鲁棒的模型,提高系统对于不同药品外包装的识别准确性,进一步提升系统的实用性和可靠性。数据扩充是本课题中一个重要的步骤,它能帮助我们克服数据集规模有限的问题,提高模型的泛化能力,从而更好地适应各种不同的药品外包装样本。
ef data_augmentation(image):
augmented_images = []
# 旋转操作
rotated_image = cv2.rotate(image, cv2.cv2.ROTATE_90_CLOCKWISE)
augmented_images.append(rotated_image)
# 镜像操作
flipped_image = cv2.flip(image, 1)
augmented_images.append(flipped_image)
# 缩放操作
scaled_image = cv2.resize(image, None, fx=0.5, fy=0.5)
augmented_images.append(scaled_image)
# 平移操作
rows, cols, _ = image.shape
translation_matrix = np.float32([[1, 0, 50], [0, 1, 50]])
translated_image = cv2.warpAffine(image, translation_matrix, (cols, rows))
augmented_images.append(translated_image)
return augmented_images
# 载入原始图像
image = cv2.imread('original_image.jpg')
# 进行数据扩充
augmented_images = data_augmentation(image)
# 保存扩充后的图像
for i, augmented_image in enumerate(augmented_images):
cv2.imwrite(f'augmented_image_{i}.jpg', augmented_image)模型训练
本实验基于Windows 10 64位平台,使用i5-9300H处理器、8GB DDR3内存和NVIDIA GTX1650独立显卡。开发环境采用Visual Studio 2017,并结合计算机视觉库OpenCV进行实验。这样的配置可以提供足够的计算资源和性能来处理图像和进行计算机视觉相关的任务。通过结合OpenCV库,可以实现图像处理、特征提取、图像识别和目标检测等功能。
为了对国药准字字符进行识别,使用改进的LeNet-5网络需要进行训练。首先,使用Xavier初始化函数对模型的权值进行初始化,以确保网络的初始参数合理。然后,将训练数据标号并输入到模型中,每次随机选择64张图像进行批量训练。使用Adam算法代替传统的随机梯度下降法来更新网络的权重和偏置参数,以提高训练效果。最后,统计识别率来评估模型的性能。
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
# 定义LeNet-5网络结构
model = tf.keras.Sequential([
layers.Conv2D(6, kernel_size=5, activation='relu', input_shape=(32, 20, 1)),
layers.MaxPooling2D(pool_size=2),
layers.Conv2D(16, kernel_size=5, activation='relu'),
layers.MaxPooling2D(pool_size=2),
layers.Flatten(),
layers.Dense(120, activation='relu'),
layers.Dense(84, activation='relu'),
layers.Dense(21, activation='softmax')
])
# 初始化模型权重
model.build((None, 32, 20, 1))
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.0001),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
# 加载训练数据和标签
train_images = ... # 训练图像数据
train_labels = ... # 训练标签
# 进行模型训练
model.fit(train_images, train_labels, batch_size=64, epochs=10)
# 加载测试数据和标签
test_images = ... # 测试图像数据
test_labels = ... # 测试标签
# 评估模型性能
test_loss, test_accuracy = model.evaluate(test_images, test_labels)
print('Test Loss:', test_loss)
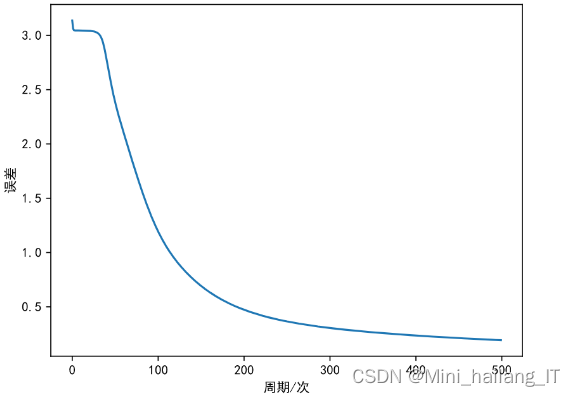
print('Test Accuracy:', test_accuracy)改进的LeNet-5网络的误差曲线图是用来展示训练过程中模型的误差变化情况。它可以帮助我们了解模型在训练过程中的收敛情况和性能表现。通过观察误差曲线图,我们可以判断模型是否收敛,是否存在过拟合或欠拟合等问题。误差曲线图还可以用来选择适当的训练轮数或提前停止训练,以获得性能最佳的模型。因此,误差曲线图在训练过程中起着重要的指导和评估作用。
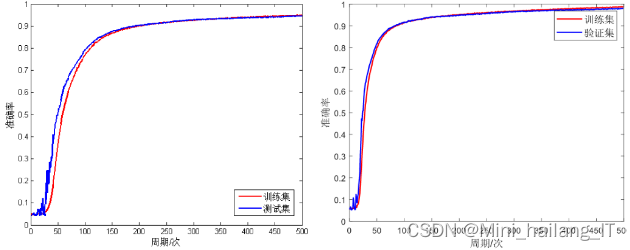
改进的LeNet-5相比传统的LeNet-5在识别准确率和识别时间上都有所提高,并且由于针对性的改进,前向传播的时间也缩短了。
model = tf.keras.Sequential([
layers.Conv2D(32, kernel_size=3, activation='relu', input_shape=(64, 64, 3)),
layers.MaxPooling2D(pool_size=2),
layers.Conv2D(64, kernel_size=3, activation='relu'),
layers.MaxPooling2D(pool_size=2),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
gyz_labels = tf.keras.utils.to_categorical(gyz_labels, num_classes)
model.fit(gyz_images, gyz_labels, batch_size=32, epochs=10)

















 590
590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









