






 本文介绍了一位学长分享的关于如何利用深度学习技术开发一个叶片病虫害识别分类系统的毕设项目。项目涉及数据集的自建、使用卷积神经网络(如AlexNet和LeNet)进行模型训练,通过实验环境的描述和实验结果分析展示了深度学习在农业病虫害检测中的应用及其优势。
本文介绍了一位学长分享的关于如何利用深度学习技术开发一个叶片病虫害识别分类系统的毕设项目。项目涉及数据集的自建、使用卷积神经网络(如AlexNet和LeNet)进行模型训练,通过实验环境的描述和实验结果分析展示了深度学习在农业病虫害检测中的应用及其优势。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于深度学习的叶片病虫害识别分类系统
项目背景
农业是国民经济的基础产业,而叶片病虫害是农业生产中常见的问题,严重影响农作物的产量和质量。传统的叶片病虫害识别和分类方法依赖于人工经验,效率低下且准确性不高。随着深度学习技术的发展,基于深度学习的叶片病虫害识别分类系统成为了解决这一问题的有效途径。此课题的研究对于推动深度学习技术在农业领域的应用,提高叶片病虫害识别和分类的准确性和效率,具有重要意义。
数据集
由于网络上没有现有的合适的数据集,我决定自己去农田进行拍摄,收集叶片病虫害图片并制作了一个全新的数据集。这个数据集包含了各种叶片病虫害的照片,其中包括不同类型的病虫害以及它们在不同发展阶段的表现。通过现场拍摄,我能够捕捉到真实的叶片病虫害情况和多样的病虫害类型,这将为我的研究提供更准确、可靠的数据。我相信这个自制的数据集将为基于深度学习的叶片病虫害识别分类系统研究提供有力的支持,并为该领域的发展做出积极贡献。

数据扩充是提高模型鲁棒性和泛化能力的重要手段。在本研究中,我们对收集到的叶片病虫害图片数据进行了多样化的数据扩充。包括使用图像处理技术生成新的训练样本,如旋转、缩放、裁剪等。这些扩充后的数据能够帮助模型更好地学习和理解叶片病虫害的多样性和复杂性,提高模型在实际应用中的表现力。同时,数据扩充还可以增加模型的泛化能力,使其在面对未见过的数据时仍能保持良好的性能。

设计思路
神经网络是机器学习技术的重要分支,也是深度学习的基础。它的基本结构是三层的神经网络,包括输入层、中间层和输出层。输入层和输出层的节点数目是固定的,而中间层的节点数目可以根据算法需求自由设定。神经网络的关键是神经元之间的连接,每个连接都有一个权重,该权重通过网络训练过程中确定。神经网络的原理是由大量神经元和神经连接组成,数据在神经网络中流动,通过调整权重实现对输入数据的学习和预测。
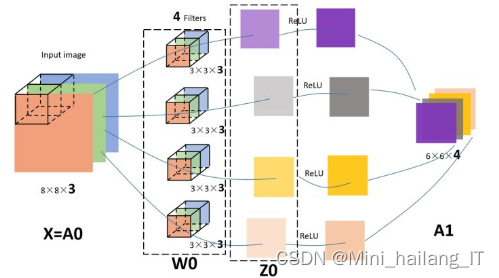
卷积神经网络(CNN)是人工神经网络(ANN)的重要组成部分,属于前馈神经网络中的多层神经网络。CNN的整体结构包括输入层、隐含层和输出层。隐含层是CNN的核心结构,包括卷积层、下采样层和全连接层。卷积层通过卷积计算提取输入图像中的深层特征,生成特征图。卷积核的数量越多,网络模型的学习能力越强。特征图传输给下采样层进行池化操作,降低特征维数,并在一定程度上防止过拟合。卷积层和池化层可以交替排列,出现次数根据模型的不同而变化。
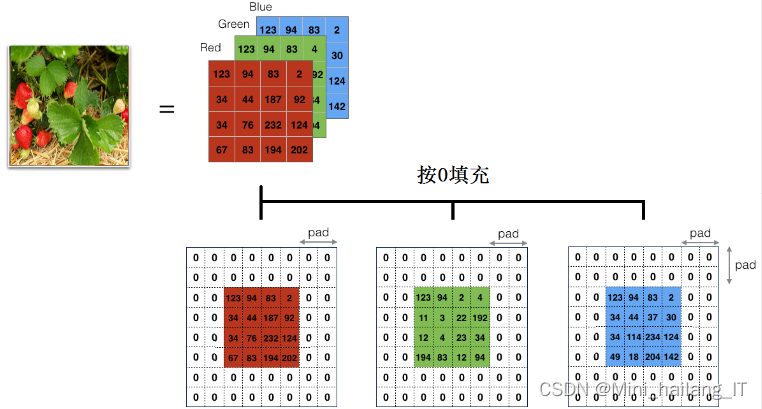
池化层在卷积神经网络中的主要作用是信息过滤和选择卷积层输出的特征。通过池化函数,池化层可以对特征图进行统计特征的池化区域替代,从而达到减少特征数量和参数量的效果,降低网络的计算量。此外,池化层还能够维持图像的不变性,对图像进行旋转、平移、伸缩等变换时保持稳定。
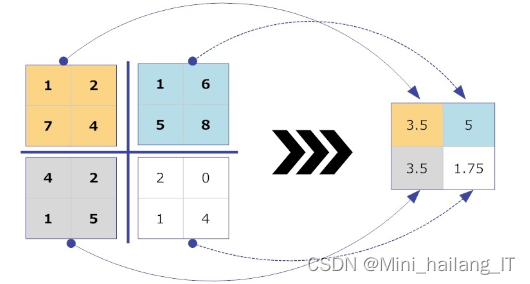
根据算法的不同,池化层可以采用最大池化(max-pooling)和均值池化(mean-pooling)两种方法。最大池化通过选择邻域内特征点的最大值来进行特征提取,而均值池化则通过求邻域内特征点的平均值来进行特征提取。最大池化是一种非线性函数,而均值池化是线性函数。
卷积神经网络中的全连接层与前馈神经网络中的隐含层类似,其作用是以全连接的形式接收上一层的神经元信号。在卷积神经网络的隐含层的最后部分,通常会包含全连接层作为分类器,用于进行深层的特征分类。全连接层的作用是将卷积神经网络中提取到的特征进行综合和分类,将高级特征与相应的输出类别进行关联。通过全连接层,网络可以学习到更加复杂和抽象的特征表示,从而实现对输入数据的准确分类和预测。
实验环境
该系统在Windows操作系统环境下使用Java语言进行设计和开发,采用B/S架构进行整体开发。前端界面使用JavaScript语言编写,图像处理和识别部分使用Python语言编写,并在PyCharm集成开发环境下完成。最终,Python程序被封装成.jar文件,Java接口可以直接调用Python程序中封装的函数。这种方式减少了系统开发的工作量并提高了开发效率。整个开发过程在Eclipse开发工具上进行运行和调试。
实验结果分析
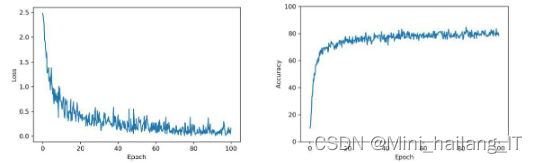
在本次实验中,训练的轮数(Epoch)设置为100,即将训练集中的全部样本训练100次。采用Adam优化算法进行训练,Adam算法通过估计梯度的一阶动量和二阶动量来自适应地调整学习率。学习率的初始值设置为0.0002。批量尺寸(Batch_size)被设定为32,表示每次迭代计算的图片数量。迭代(Iterations)是训练过程中重复反馈的过程,通过多次迭代训练神经网络,以达到预定的目标或结果。在本实验中,迭代次数与训练轮数相对应,即每个Epoch进行一次迭代。

通过比较LeNet和AlexNet两种卷积神经网络模型的训练结果,发现AlexNet模型在准确率和拟合程度上优于LeNet模型。具体来说,AlexNet模型的Loss值较低,表明其更好地拟合了训练数据;而准确率也明显高于LeNet模型,达到了91.04%。此外,AlexNet模型在较少的Epoch值下就达到了收敛,相比之下,LeNet模型需要更多的训练轮数。
相关代码示例:
# 定义模型
model = models.alexnet(pretrained=True)
num_features = model.classifier[6].in_features
model.classifier[6] = nn.Linear(num_features, len(class_names))
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# 训练模型
def train_model(model, criterion, optimizer, num_epochs=10):
for epoch in range(num_epochs):
print(f'Epoch {epoch+1}/{num_epochs}')
print('-' * 10)
for phase in ['train', 'val']:
if phase == 'train':
model.train() # 训练模式
else:
model.eval() # 验证模式
running_loss = 0.0
running_corrects = 0
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
return model
# 训练模型
model = train_model(model, criterion, optimizer, num_epochs=10)海浪学长项目示例:























 7506
7506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









