







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于机器学习的地铁安检物品检测系统
项目背景
地铁作为城市重要的公共交通方式,安全问题一直备受关注。地铁安检是确保乘客安全的重要环节,但传统的人工安检方式存在效率低下和主观性强的问题。因此,开发基于机器学习的地铁安检物品检测系统具有重要意义。该系统利用计算机视觉和机器学习技术,能够自动识别地铁乘客携带的安全禁止物品,如刀具、爆炸物等,提高地铁安检的效率和准确性。通过该课题的研究,可以促进地铁安检工作的智能化发展,提升安全检查水平,为城市交通安全提供可靠保障。
数据集
由于网络上缺乏现有适用于基于机器学习的地铁安检物品检测系统的数据集,我决定使用网络爬虫技术自行收集数据,并制作了一个全新的数据集。该数据集包含了各种地铁安检场景中的图像,包括乘客携带的各类物品,如包、箱、刀具等。通过网络爬取和筛选,我获取了大量真实且多样化的图像,这将为我的研究提供更准确、可靠的数据基础。我相信这个自制的数据集将为基于机器学习的地铁安检物品检测系统的研究提供有力的支持,并为该领域的发展做出积极贡献。

为了增强基于机器学习的地铁安检物品检测系统的性能和鲁棒性,我采取了数据扩充的方法。通过对原始数据集进行各种变换和增强操作,例如旋转、缩放、平移和亮度调整,我生成了更多样化和丰富的图像数据。这种数据扩充的技术可以增加训练数据的多样性,提高系统对不同场景和光照条件的适应能力。同时,我还进行了数据平衡处理,确保各类物品在数据集中的分布均衡,避免模型对某些类别的偏好。通过数据扩充,我期待进一步提升地铁安检物品检测系统的性能,使其在实际应用中更加可靠和准确。
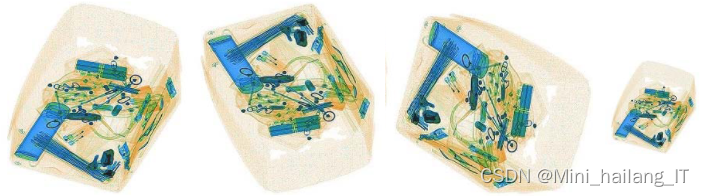
设计思路
传统基于滑动窗口方法的检测器被基于卷积神经网络的检测器所取代。基于卷积神经网络的检测器可以分为两个主要流派:两阶段检测器和一阶段检测器。
- 两阶段检测器由两个部分组成,第一部分生成稀疏的区域提议集,第二部分对提议进行分类和回归。这些两级检测器在具有挑战性的基准测试中取得了优秀的性能。
- 一阶段检测器是基于深度学习的一种检测方法,最早的一阶段检测器是OverFeat,之后出现了YOLO和SSD等算法。这些算法通过直接对预定义的默认框进行分类和回归来实现目标检测,并在准确性和实时性方面取得了有希望的结果。然而,与两阶段检测器相比,一阶段检测器的精度通常较低。

在卷积神经网络中,每一层的输出特征图可以看作是对输入图像的感受野映射。感受野就是网络中某一层输出结果中的一个元素在输入层的对应映射区域大小。为了准确提取目标特征,预测模块需要关注调整后的默认框,并使其感受野与之协调。
在两阶段检测器中,通常使用特征池操作(如RoI Pooling)来处理这个问题。但是,对于动态调整的默认框,传统的卷积滤波器采样位置固定在整个输入特征图上,可能会错过调整后的默认框所提供的精确目标特征,并且无法在最终框回归中显式考虑调整后的默认框。为了解决这个问题,提出了一种自适应感受野匹配的方法,即通过在卷积滤波器的固定网格采样位置上增加自适应的偏移量来覆盖调整后的默认框。这样可以确保卷积滤波器能够准确地提取调整后的默认框所包含的目标特征,从而提高分类和框回归的准确性。
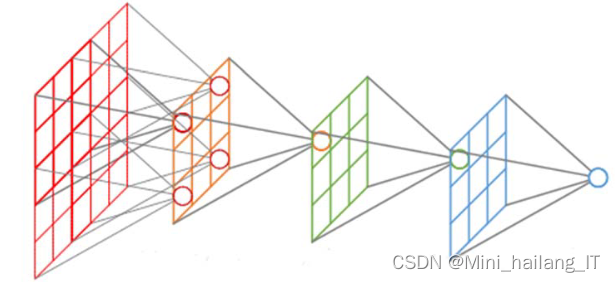
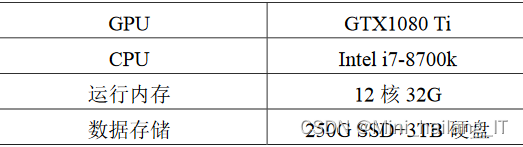
在Ubuntu系统环境下,使用TensorFlow框架进行网络模型训练,并配置了CUDA9基础架构、CUDNN7和PyTorch等工具,以提高训练速度。为了改善模型的尺度不变性,采用了特征金字塔网络(FPN)作为骨干网络,应用于三个基本网络:VGG-16、ResNet-101和MobileNet。
为了捕获大型对象,对被截断的VGG-16末端添加了两个额外的卷积块(conv8和conv9,步长为2),对截断的ResNet-101末端添加了一个额外模块(步长为2,通道为512),对截断的MobileNet末端添加了一个额外的深度卷积(步长为2,通道为512)。针对VGG-16和额外的层,在SSD中采用相同的配置,并使用L2归一化技术来扩展SSD之后的VGG-16的功能规范。
构建FPN时,使用了四个特征图,步幅分别为8、16、32和64像素,来自基本网络和额外的层。每个特征图都与默认框关联,其中每个特征图单元与具有默认比例的三个比例(0.5、1.0和2.0)的默认框相关联,长宽比设置为1:1。每个特征图单元分配了A=3个默认框,并通过预测长度为C的向量来检测其中的对象,其中C是对象类的数量,包括背景类和四个用于框回归的偏移量。
相关代码示例:
import tensorflow as tf
# 定义自适应调整默认框的函数
def adjust_default_boxes(inputs):
# 输入参数inputs包括默认框坐标、预测的二进制评分等
default_boxes = inputs['default_boxes']
scores = inputs['scores']
# 根据二进制评分调整默认框的大小和位置
adjusted_boxes = tf.where(tf.greater(scores, 0.5), default_boxes * 1.1, default_boxes)
return adjusted_boxes
# 构建模型
def build_model():
# 假设输入包括默认框和预测的二进制评分
default_boxes = tf.placeholder(tf.float32, [None, 4], name='default_boxes')
scores = tf.placeholder(tf.float32, [None], name='scores')
# 调用自适应调整默认框的函数
adjusted_boxes = adjust_default_boxes({'default_boxes': default_boxes, 'scores': scores})
return adjusted_boxes海浪学长项目示例:























 889
889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









