







要去广州工作了,所以抓取了广州租房信息看一下,来源是某家广州租房网。网上爬虫代码很多,对于简单的网页实现起来也很简单,直接上核心代码:
require(RCurl) ##载入包
require(XML)
rm(list = ls())
GZsource <- data.frame()
system.time(for (i in 1:100) {
if(i==1){webside ="http://xxxxxxxx.com/zufang/"}
else{webside = paste("http://xxxxxxxx/zufang/pg", i, "/", sep = "")}
url = getURL(webside, .encoding = "utf-8")
url_parse = htmlParse(url, encoding = "utf-8")
# 标题、链接
node = getNodeSet(url_parse, path = "//div[@class='list-wrap']//div[@class='info-panel']//a[@title]")
title_name = sapply(node, function(X) xmlGetAttr(X, "title"))
Encoding(title_name) = "UTF-8"
link = paste("http://sh.xxxxx.com", sapply(node, function(X) xmlGetAttr(X, "href")), sep = "")
# 小区、户型、面积
node = getNodeSet(url_parse, path = "//div[@class='list-wrap']//div[@class='where']//span")
inf1 = sapply(node, xmlValue)
xiaoqu = inf1[(1:length(title_name))*5 - 4]
house_type = gsub("\\s+", "", inf1[(1:length(title_name))*5 - 2])
size = as.numeric(gsub("[^0-9]*$", "", inf1[(1:length(title_name))*5 - 1]))
# 区域、地段
node = getNodeSet(url_parse, path = "//div[@class='list-wrap']//div[@class='other']//a")
inf2 = sapply(node, xmlValue)
area = inf2[(1:length(title_name))]
#diduan = inf2[(1:length(title_name))*2 - 0]
# 价格
node = getNodeSet(url_parse, path = "//div[@class='list-wrap']//div[@class='price']/span[@class='num']")
price = as.numeric(gsub("[^0-9]", "", sapply(node, xmlValue)))
GZsource = rbind(GZsource, data.frame(title_name, link, xiaoqu, house_type, size, area, price, stringsAsFactors = FALSE))
Sys.sleep(1)
})为了分地区分析,我直接按照行政区分别进行的抓取,比如天河区如下:
Tianhe <- data.frame()
system.time(for (i in 1:100) {
if(i==1){
webside = "http://xxxxxxxx/zufang/tianhe/"}
else{webside = paste("http://xxxxxxxx/zufang/tianhe/pg", i, "/", sep = "")}
url = getURL(webside, .encoding = "utf-8")
url_parse = htmlParse(url, encoding = "utf-8")
# 标题、链接
node = getNodeSet(url_parse, path = "//div[@class='list-wrap']//div[@class='info-panel']//a[@title]")
title_name = sapply(node, function(X) xmlGetAttr(X, "title"))
Encoding(title_name) = "UTF-8"
link = paste("http://sh.xxxxx.com", sapply(node, function(X) xmlGetAttr(X, "href")), sep = "")
# 小区、户型、面积
node = getNodeSet(url_parse, path = "//div[@class='list-wrap']//div[@class='where']//span")
inf1 = sapply(node, xmlValue)
xiaoqu = inf1[(1:length(title_name))*5 - 4]
house_type = gsub("\\s+", "", inf1[(1:length(title_name))*5 - 2])
size = as.numeric(gsub("[^0-9]*$", "", inf1[(1:length(title_name))*5 - 1]))
# 区域、地段
node = getNodeSet(url_parse, path = "//div[@class='list-wrap']//div[@class='other']//a")
inf2 = sapply(node, xmlValue)
area = inf2[(1:length(title_name))]
#diduan = inf2[(1:length(title_name))*2 - 0]
# 总价
node = getNodeSet(url_parse, path = "//div[@class='list-wrap']//div[@class='price']/span[@class='num']")
price = as.numeric(gsub("[^0-9]", "", sapply(node, xmlValue)))
# 单价
# node = getNodeSet(url_parse, path = "//div[@class='list-wrap']//div[@class='price-pre']")
# danjia = as.numeric(gsub("[^0-9]", "", sapply(node, xmlValue)))
Tianhe = rbind(Tianhe, data.frame(title_name, link, xiaoqu, house_type, size, area, price, stringsAsFactors = FALSE))
Sys.sleep(1)
})
Tianhe$District <- "天河区"最后把每个区的合并起来就行:
GZhouse <- rbind(Tianhe,panyu,liwan,Yuexiu,haizhu,baiyun,luogang,huangpu,huadou,zengcheng)最后结果如下
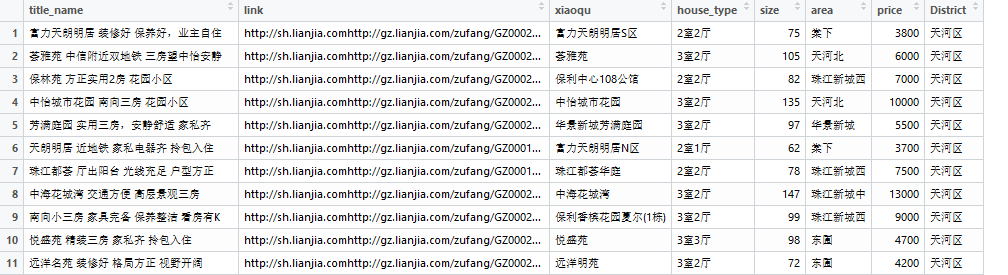
下一步就是在预处理后对房价进行可视化分析,看看现在不同区域的价格差异,等有时间再多找些数据以后多方位进行房价影响因素分析。
未完待续…















 2095
2095

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









