







先介绍一下吧
在监督学习或者分类中,随机森林(RF)是一个非常好的分类学习算法。随机森林算法的实质是基于决策树的分类器集成算法,每一棵决策树给出一对实体的匹配决策,并根据所有的树的投票来得到最终决策。
基本思想:首先,通过自助法(bootstrap)重采样技术,从原始训练样本集N中有放回的重复随机抽取k个样本生成新的训练集样本集合,每个样本集合容量为k;其次,根据自助样本集生成k个决策树组成的随机森林,得到k种分类结果;最后,根据k种分类结果对每个记录进行投票表决来决定最终分类。
其实质是对决策树算法的一种改进,将多棵决策树组合在一起,每棵决策树的建立依赖于一个独立抽取的样本,形成森林中的每棵树都具有相同的分布,分类误差取决于每一棵决策树的分类能力和它们之间的相关性。步骤如下:
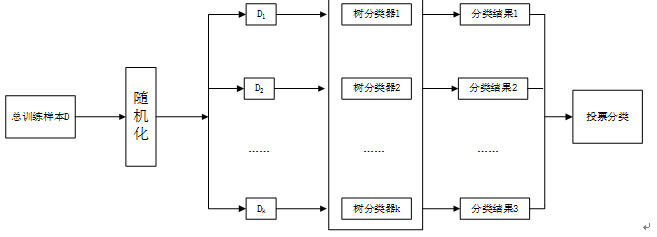
(1)首先我们用N表示原始训练集样本的个数,用M表示特征数目。
(2)从原始训练数据集中,应用bootstrap方法有放回地随机抽取k个新的自助样本集,并由此构建k棵分类回归树,每次未被抽到的样本组成了k个袋外数据(out-of-bag,OOB)。
(3)每个自助样本集生长为单棵决策树。在树的每个节点处从M个特征中随机挑选m个特征(m≤M),按照节点不纯度最小原则从这m个特征中选择一个特征进行节点分裂。
(4)每棵树都做最大限度的生长,不做任何
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















05-29
 579
579
579
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









