







安装
requests是一个基于网络请求的模块。可以模拟浏览器进行网络请求。
pip install requests
流程
- 指定url(网址)
- 发起请求
- 获取响应数据(爬取到的数据)
- 持久化存储
小示例(GET请求)
1. 首页获取
# 51游戏首页爬取
# URL:https://code.51.com/jh/tg1/i11/ld2j29ic.html
import requests
# 1.指定url
url = 'https://code.51.com/jh/tg1/i11/ld2j29ic.html'
# 2.发起请求
# get会返回一个响应对象。
response = requests.get(url=url)
# 3.获取响应数据
page_text = response.text # text表示获取字符串形式的响应数据
# print(page_text)
# 4.持久化存储
with open('51game.html', 'w', encoding='utf-8') as fp:
fp.write(page_text)
2. URL搜索
注意:在浏览器的地址栏中网址,网址?后面的内容就是请求的参数(请求参数)
# 51游戏搜索
# URL:https://game.51.com/search/action/game/?q=传奇
import requests
# 1.指定url
params = { # 字典是用于封装请求参数
'q': '传奇'
}
url = 'https://game.51.com/search/action/game/'
# 2.发起请求
# get是基于指定的url和携带了固定的请求参数进行请求发送
response = requests.get(url=url, params=params)
# 3.获取响应数据
page_text = response.text # text表示获取字符串形式的响应数据
# print(page_text)
# 4.持久化存储
with open('传奇.html', 'w', encoding='utf-8') as fp:
fp.write(page_text)
改进
# 根据输入内容返回html页面
game_title = input('输入搜索内容:')
params = { # 字典是用于封装请求参数
'q': game_title
}
# 多个请求参数
import requests
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36'
}
title = input('请输入菜名:')
params = {
'keyword': title,
'cat': '1001'
}
# 1.指定url
url = 'https://www.xiachufang.com/search/'
# 2.发起请求
response = requests.get(url=url, headers=headers, params=params)
# 处理乱码
response.encoding = 'utf-8' # gbk
# 3.获取响应数据
page_text = response.text
# 4.持久化存储
fileName = title + '.html'
with open(fileName, 'w', encoding='utf-8') as fp:
fp.write(page_text)
3. UA检测
User-Agent:请求载体的身份标识。
- 使用浏览器发请求,则请求载体就是浏览器
- 使用爬虫程序发请求,则请求载体就是爬虫程序
所以,爬虫发起请求的User-Agent伪装成浏览器的身份,即可
import requests
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
# 1.指定url
url = 'https://www.xiachufang.com/'
# 2.发起请求
# 携带了指定的请求头进行的请求发送
response = requests.get(url=url, headers=headers)
# 3.获取响应数据
page_text = response.text
# 4.持久化存储
with open('cook.html', 'w', encoding='utf-8') as fp:
fp.write(page_text)
4. 动态加载数据爬取
# 电影名称和评分爬取
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
url = 'https://movie.douban.com/typerank?type_name=%E7%88%B1%E6%83%85&type=13&interval_id=100:90&action='
response = requests.get(url=url, headers=headers)
page_text = response.text
with open('douban.html', 'w', encoding='utf-8') as fp:
fp.write(page_text)
在
douban.html中,并没有包含电影详情数据,需要定位动态加载数据是在哪一个数据包中
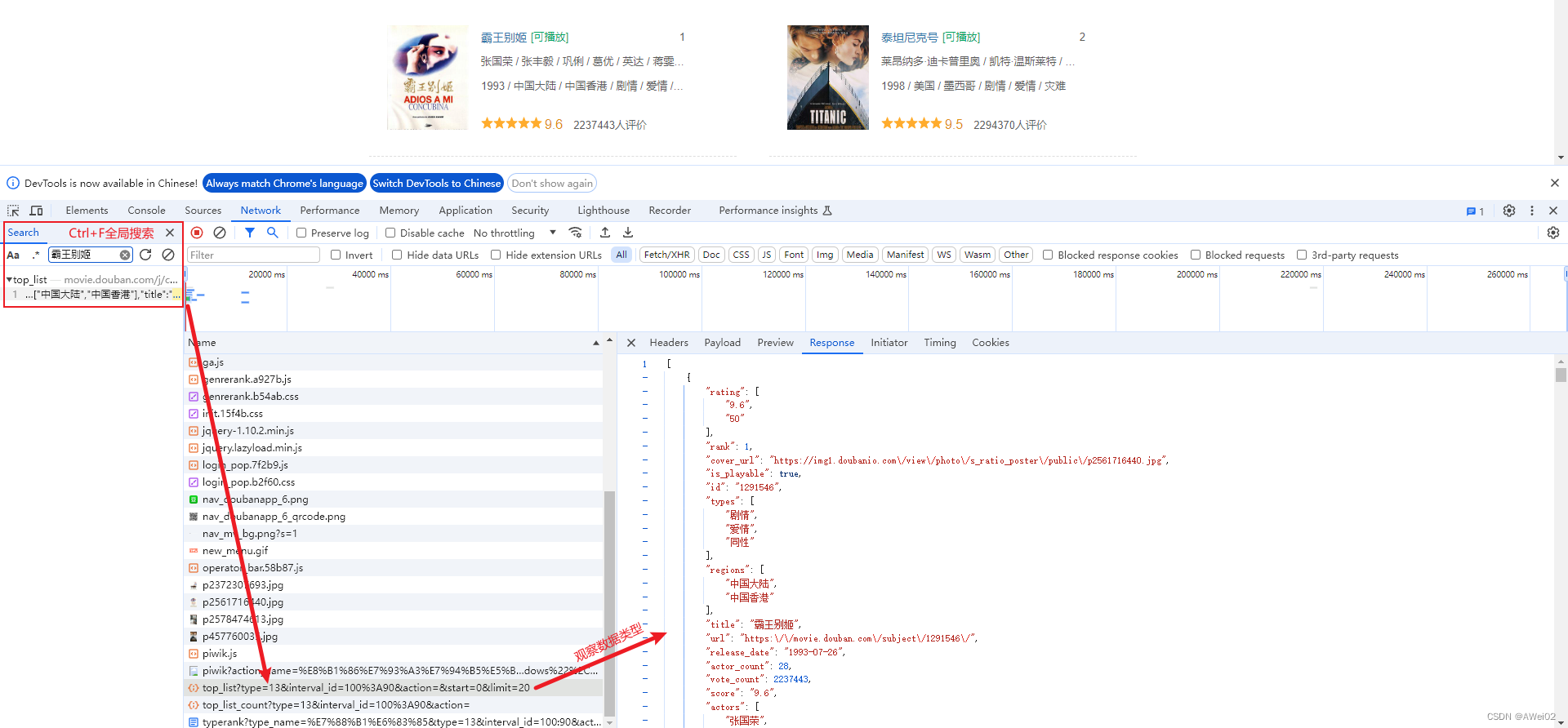
查看Header,分解请求
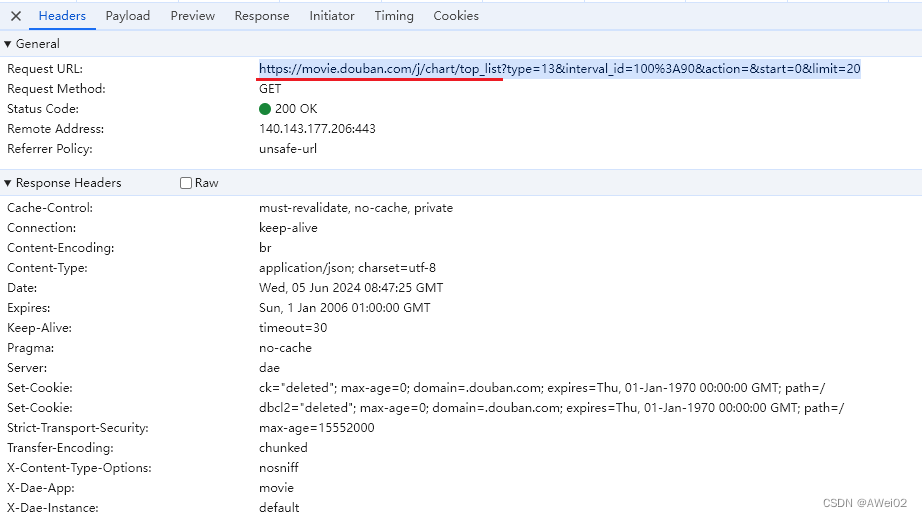
注意,其中的%根据URL编码规则改变,如%3A就是英文冒号
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
params = {
"type": "13",
"interval_id": "100:90",
"action": "",
"start": "0",
"limit": "20"
}
url = 'https://movie.douban.com/j/chart/top_list'
response = requests.get(url=url, headers=headers, params=params)
# json()获取json格式的响应数据,并且直接对json格式的响应数据进行反序列化
data_list = response.json()
fp = open('movie.txt', 'w')
for dic in data_list:
title = dic['title']
score = dic['score']
print(title, score)
fp.write(title + ':' + score + '\n')
fp.close()
小示例(POST请求)
# 爬取单页的数据
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
data = {
"cname": "",
"pid": "",
"keyword": "天津",
"pageIndex": "1",
"pageSize": "10"
}
# post请求携带请求参数使用data这个参数
response = requests.post(url=url, headers=headers, data=data)
data = response.json()
for dic in data['Table1']:
city = dic['cityName']
address = dic['addressDetail']
print(city, address)
# 爬取若干页的数据
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
for page in range(1, 6):
data = {
"cname": "",
"pid": "",
"keyword": "天津",
"pageIndex": str(page),
"pageSize": "10"
}
# post请求携带请求参数使用data这个参数
response = requests.post(url=url, headers=headers, data=data)
data = response.json()
for dic in data['Table1']:
city = dic['cityName']
address = dic['addressDetail']
print(city, address)
小示例(图片)
前提要找到图片地址
# 方式1(需要UA伪装时):
import requests
url = 'https://img0.baidu.com/it/u=540025525,3089532369&fm=253&fmt=auto&app=138&f=JPEG?w=889&h=500'
response = requests.get(url=url)
# content获取二进制形式的响应数据(图片、音频、视频、压缩包传输二进制)
img_data = response.content
with open('1.jpg', 'wb') as fp:
fp.write(img_data)
# 方式2(不需要UA伪装时)
from urllib import request
url = 'https://img0.baidu.com/it/u=540025525,3089532369&fm=253&fmt=auto&app=138&f=JPEG?w=889&h=500'
# urlretrieve可以将参数1表示的图片地址请求并且保存到参数2的目录中
request.urlretrieve(url, '2.jpg')















 5018
5018

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









