










Scrapy爬虫框架
目录
【1】Scrapy基础模块
| 模块 | 功能 | 实现 |
|---|---|---|
| 爬虫(Spiders) | 定义爬虫规则,发送request请求和处理返回的response都在这里实现 | 需要手写 |
| 数据存储(Items) | 定义爬取下来的数据结构,以及初步处理 | 需要手写 |
| 数据处理管道(Pipelines) | 自定义数据处理管道类,对爬取数据进行处理、清洗和存储等操作 | 需要手写 |
| 引擎(Engine) | 控制整个爬虫流程,处理数据流、触发事件等 | Scrapy已实现 |
| 调度器(Scheduler) | 接受引擎传来的request请求,按照算法确定请求顺序,发送给下载器 | Scrapy已实现 |
| 下载器(Downloader) | 下载请求的网页内容并返回给引擎,实现请求发送和页面下载功能 | Scrapy已实现 |
| 中间件(Middleware) | 插件机制,处理请求和响应的流程,进行请求发送前和响应返回后的处理,如设置请求头、代理等 | 可手写 |
| 扩展(Extensions) | 提供机制,用户可自定义功能如监控、日志、统计信息等 | 可手写 |
【2】Scrapy生命周期图
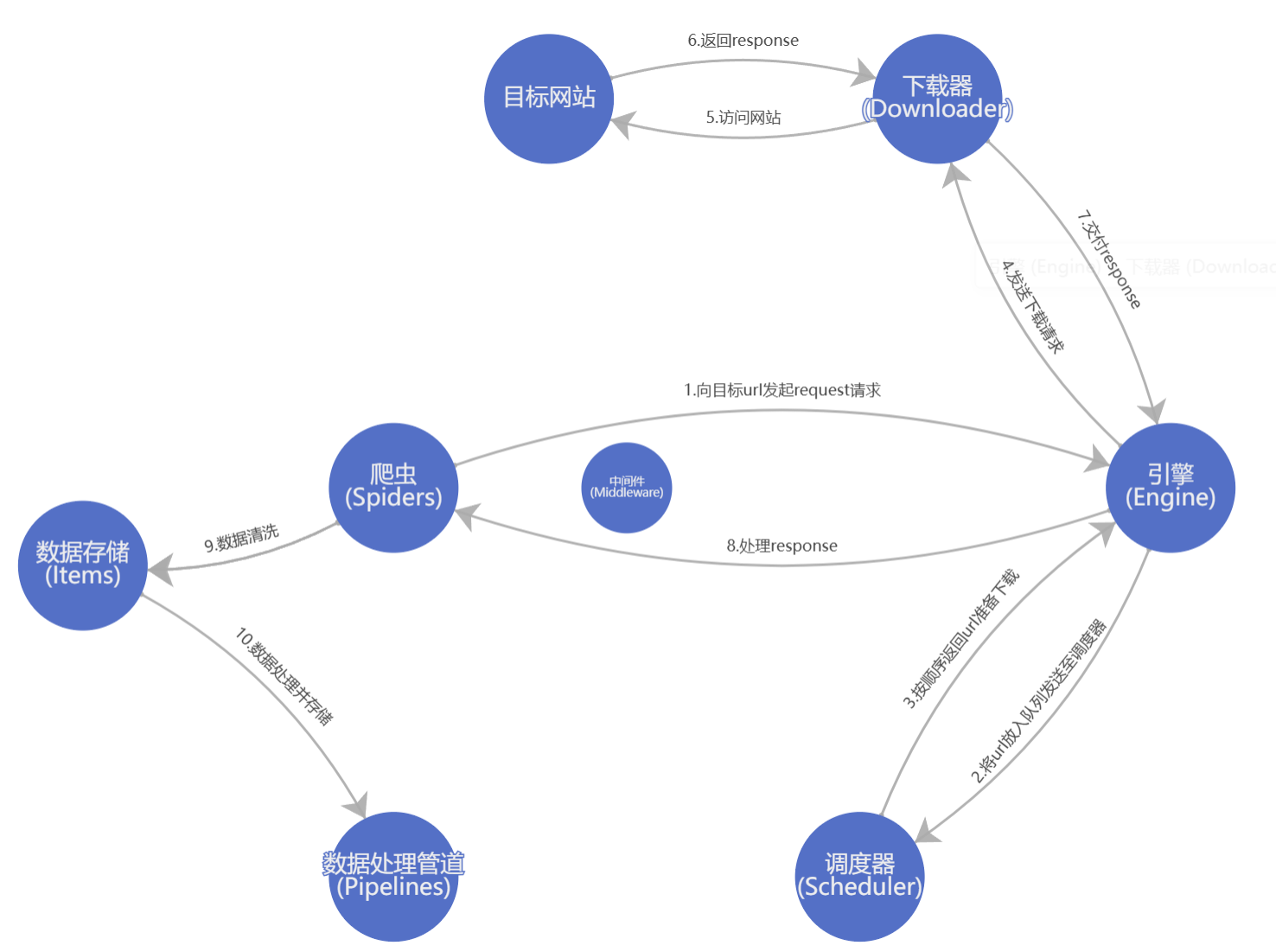
- 开始请求发送:爬虫引擎开始处理初始请求,并将它们发送到调度器
- 请求调度:调度器接收请求并根据调度算法将它们发送到下载器
- 下载网页:下载器下载网页并将响应发送回引擎
- 解析响应:引擎接收响应并将其发送到Spider处理
- 爬取数据:Spider处理响应并从中提取数据,然后生成新的请求
- 数据处理:爬虫处理管道接收提取的数据并执行后续处理,如数据清洗、存储等
- 存储数据:处理后的数据被存储到指定的数据存储介质中,例如Mysql
- 处理异常:在处理过程中可能发生异常,需要通过异常处理机制进行处理。
- 爬虫关闭
【3】Scrapy安装
pip install scrapy
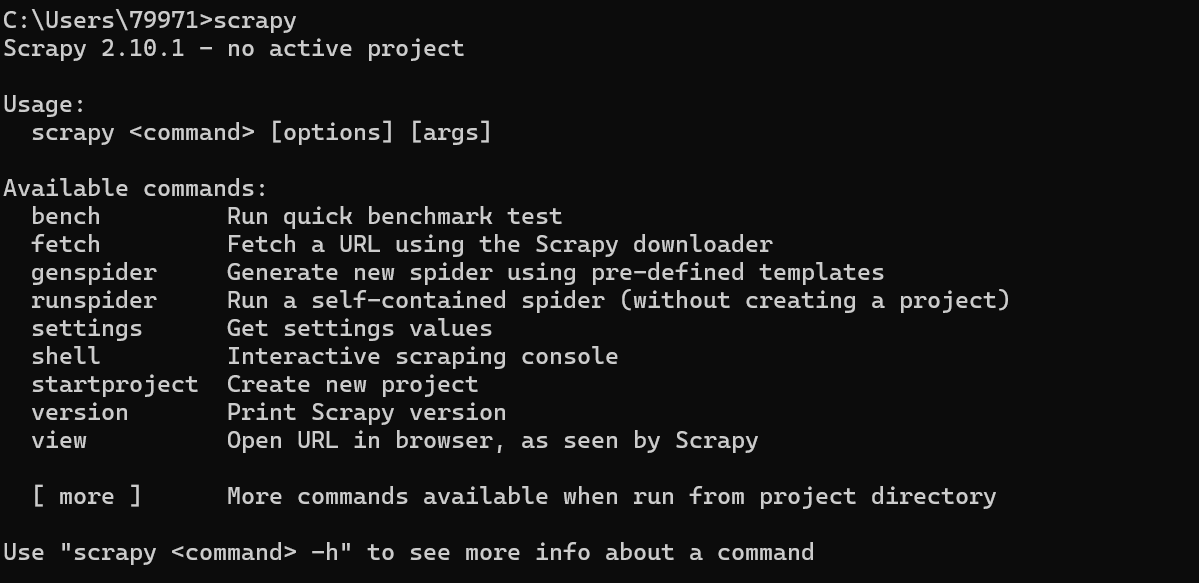
检查安装是否成功:
cmd输入scrapy有以下信息说明安装成功
【4】创建第一个Scrapy爬虫
【1】新建项目目录
方式1
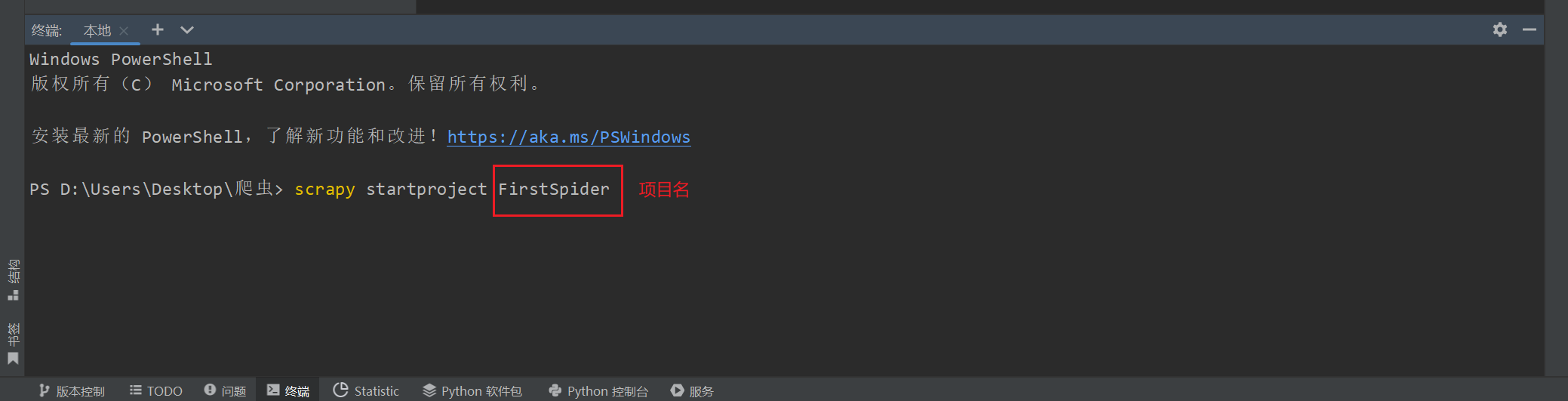
【1】新建一个文件夹用pycharm打开

【2】终端输入scrapy startproject FirstSpider
FirstSpider是自己取的项目名
方式2
【1】新建文件夹双击路径输入cmd
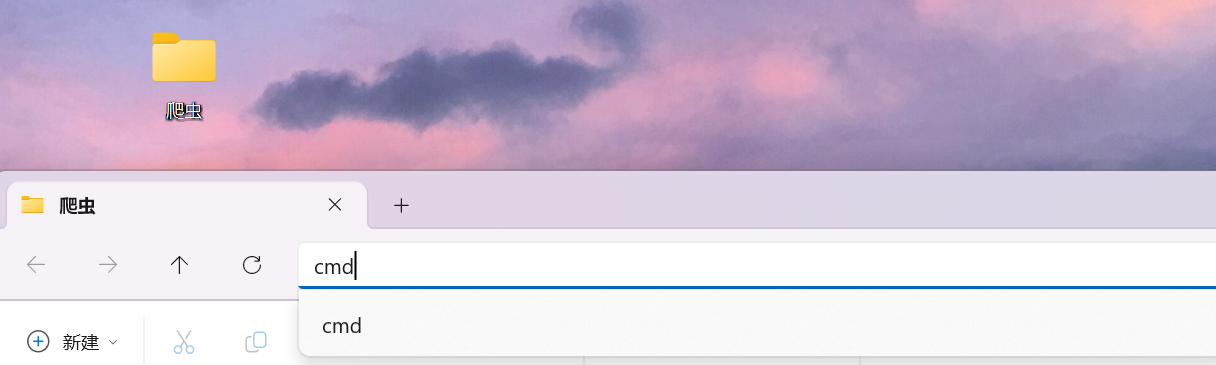
此时cmd会自动打开于当前目录路径
【2】输入scrapy startproject FirstSpider
【2】创建爬虫文件
完成上述操作后可以系统会创建这样一个目录结构
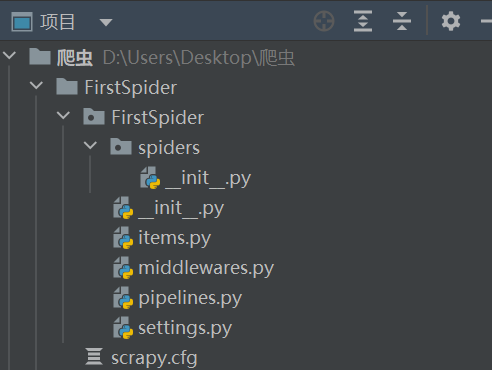
├── NewsPro # 项目名 │ ├── __init__.py │ ├── items.py # 管道 │ ├── middlewares.py # 中间件 │ ├── pipelines.py # 管道---> 处理持久化 │ ├── settings.py # 项目配置文件 │ └── spiders # 里面放了自定义的爬虫 │ ├── __init__.py │ ├── baidu.py # 自定义爬虫文件 │ └── wangyi.py # 自定义爬虫文件 └── scrapy.cfg # 项目上线配置
创建目录后spiders里是空的,这时候就需要我们创建第一个爬虫文件
scrapy genspider 爬虫名 域名
记得要切换到spiders目录下

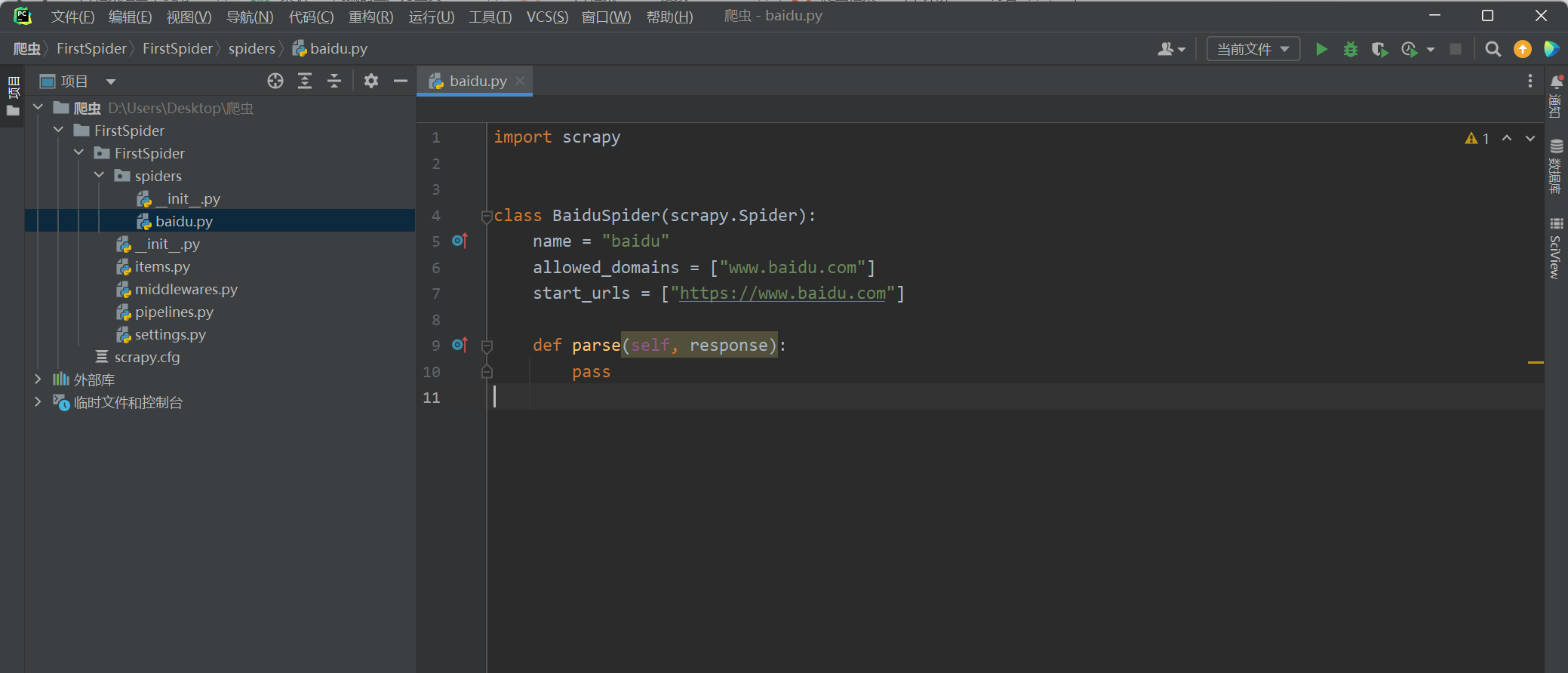
此时第一个爬虫文件就已创建成功了
【5】settings.py
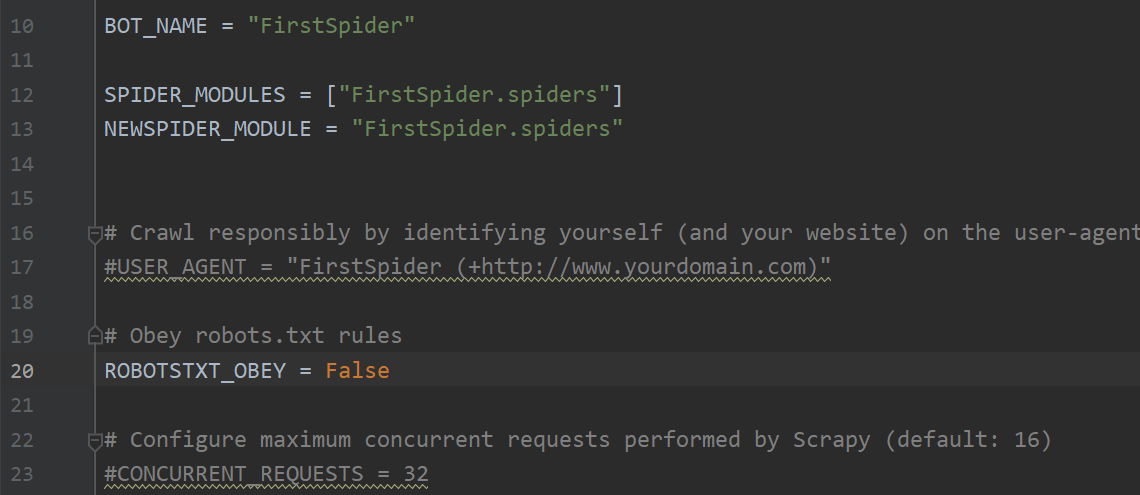
- BOT_NAME:
BOT_NAME定义爬虫的名称
- SPIDER_MODULES:
SPIDER_MODULES是一个包含爬虫模块的列表,指定了Scrapy应该查找爬虫的模块
- NEWSPIDER_MODULE:
NEWSPIDER_MODULE用于指定新建爬虫时的默认模块,当使用scrapy genspider命令创建新爬虫时,新爬虫文件将被放置在指定的模块中
- USER_AGENT:
- 用户代理,默认注释,这个东西非常重要,
如果不写很容易被判断为电脑,简单点设置一个Mozilla/5.0即可
- 用户代理,默认注释,这个东西非常重要,
- ROBOTSTXT_OBEY:
ROBOTSTXT_OBEY控制是否遵守 robots.txt 协议,如果设置为True,Scrapy 将遵守网站的 robots.txt 规则,但是会有很多数据爬不到,因此我们设为False
- CONCURRENT_REQUESTS:
- 最大并发数,也就是允许同时开启多少爬虫线程
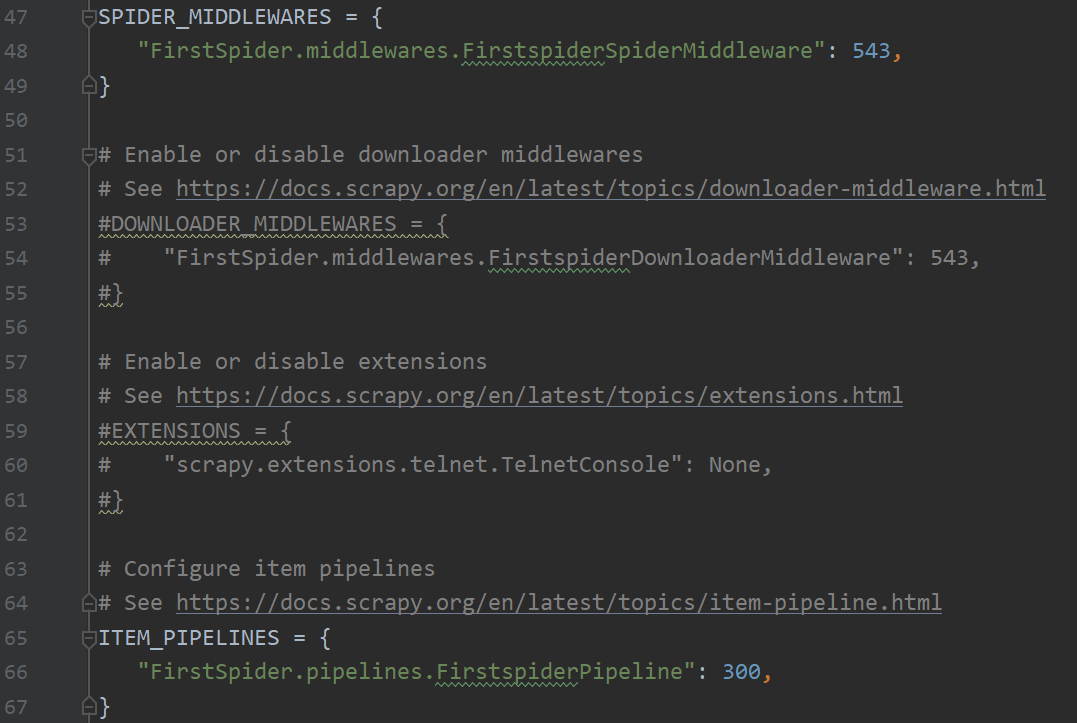
- SPIDER_MIDDLEWARES:
- 用于配置 Spider 中间件,键是中间件的路径,值是中间件的顺序,数值越小表示中间件优先级越高。
- ITEM_PIPELINES:
- 用于配置 Item 管道,控制数据的处理和存储过程。键是管道的路径,值是管道的顺序,数值越小表示管道优先级越高
- 管道会影响数据的处理和存储过程,如数据清洗、数据存储到数据库等操作
【6】items.py
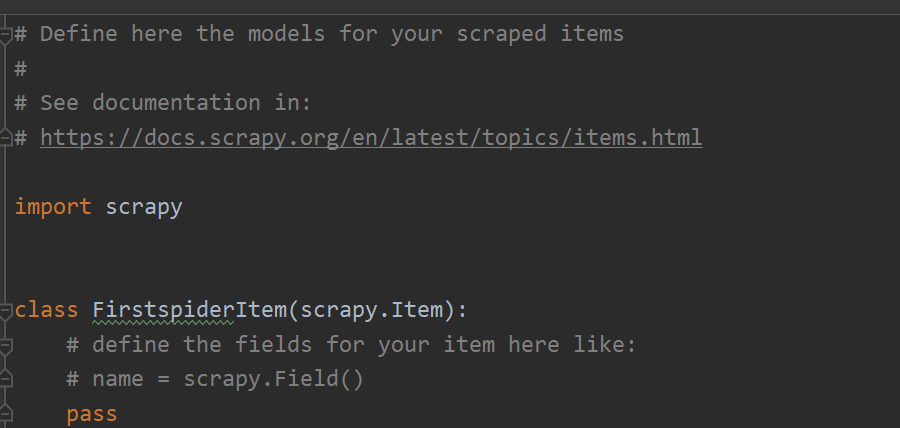
这是创建scrapy项目后默认创建的管道类,也可以自行新建别的管道,这里一般就会用来接受spider传过来的数据并对其进行**[打包]**
【7】pipelines.py
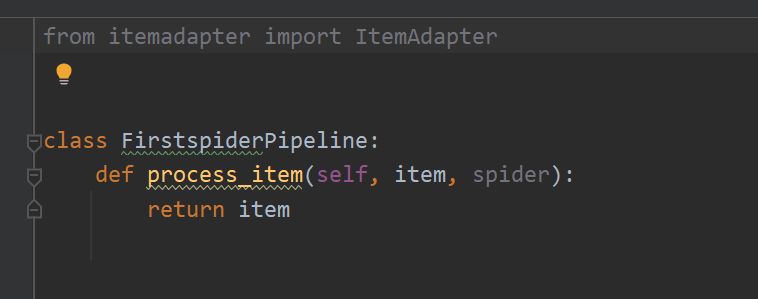
scrapy创建时会自动创建默认的item类,这里一般用于处理数据和持久化存储,例如将数据处理后存入数据库,也可以根据需求自行创建,但是创建新的item类时需要去settings中注册
【8】启动爬虫
在spider文件中随便打印一下response
import scrapy
class BaiduSpider(scrapy.Spider):
name = "baidu"
allowed_domains = ["www.baidu.com"]
start_urls = ["https://www.baidu.com"]
def parse(self, response):
print(f'这是响应:{response}')
启动爬虫的两种方式
方式1
直接终端启动,但是需要将路径切换到spiders.py所在的目录下
PS D:\Users\Desktop\爬虫\FirstSpider\FirstSpider> scrapy crawl baidu

成功
方式2
在主目录下创建启动文件
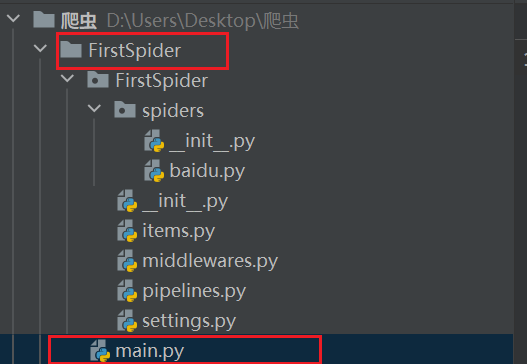
这里将启动文件main.py定义在项目路径上级目录
# main.py
from scrapy.cmdline import execute
import sys
import os
# 定义项目路径
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
# 模拟命令行命令[scrapy crawl baidu]
execute(["scrapy", "crawl", "baidu"])

成功,内容和正常输出相同,只是字体红色














 18万+
18万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









