







在学习完之前的Spark原理篇和分布式原理篇之后,本文正式进入spark实战操作部分,
本文将从实战操作、代码精讲两部分着重对Spark部署、Spark作业、Spark和MR三个部分进
行系统全面深度挖掘;Spark作业会分为Local和yarn两个模式。介于文章的连续性和严谨
性,故从0开始一步一步进行环境搭建部署,因此篇幅可能会很长,但笔者将去繁为简,将着
重描述重要的部分;会将实操、源码和数学原理结合起来一起解析,除此之外,本文会涉及
到之前的分布式和Spark基础知识,不了解或者不清楚的朋友可以看笔者之前写的文章。(链
接如下)
【Spark】分布式系统解密:核心概念与CAP解析_分布式计算-CSDN博客文章浏览阅读679次,点赞25次,收藏25次。概念一:分布式由于课程只讲述了分布式的分类,并且并未深度解析该概念,在此将做一个全面的介绍以供深入理解分布式的概念和应用场景。_分布式计算https://blog.csdn.net/A_Real_Beast/article/details/149234031?spm=1001.2014.3001.5501【Spark】Spark与MapReduce:谁更胜一筹?-CSDN博客文章浏览阅读461次,点赞19次,收藏8次。深入理解Spark、Spark概述、mapreduce和spark架构的区别
https://blog.csdn.net/A_Real_Beast/article/details/149470696?spm=1001.2014.3001.5501
从0开始的Spark部署
笔者笔记本系统为win11,考虑到性能和其他方面的因素,遂将Spark环境安装在Linux
系统上。
基础环境配置:
设备信息
虚拟机软件
VMWare Workstation17(不会安装的朋友的请自行移步至以下链接)
Linux系统
CentOS7系统 (不会安装的朋友的请自行移步至以下链接)
CentOS7(Linux)详细安装教程(手把手图文详解版)-CSDN博客![]() https://blog.csdn.net/qq_57492774/article/details/131772646
https://blog.csdn.net/qq_57492774/article/details/131772646
终端软件和交互软件
Xshell和Xftp(不会安装的朋友的请自行移步至以下链接)
虚拟机和xshell和主机的网络互通请朋友们自行解决~
安装Spark软件至虚拟机上
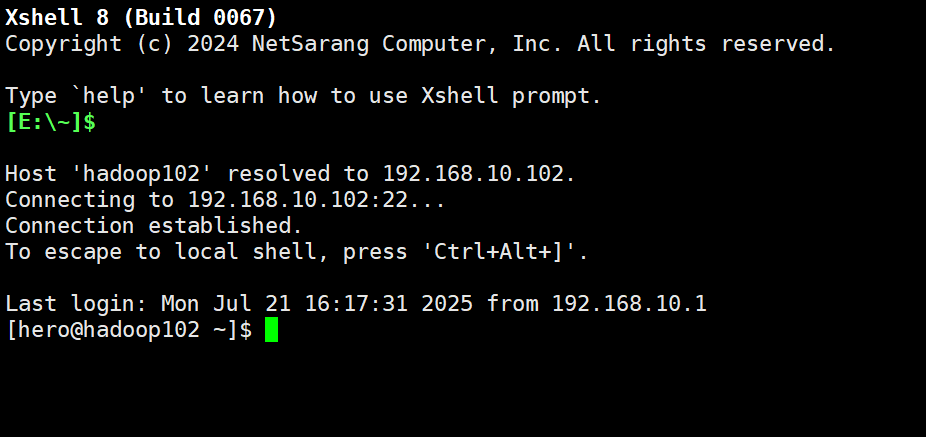
首先进入虚拟机并用xshell进行远程链接,成功连接如下图所示
然后进入根目录中的opt目录并创建一个名为sotfware的目录,以下是相关Linux命令
cd / cd opt/ mkdir software
由于笔者之前已经创建好了目录,因此在这只放一张完成好的示意图
以下是spark软件的安装链接
链接: https://pan.baidu.com/s/1POzhTlVVpl3-7vDH76o4bQ?pwd=1234 提取码: 1234
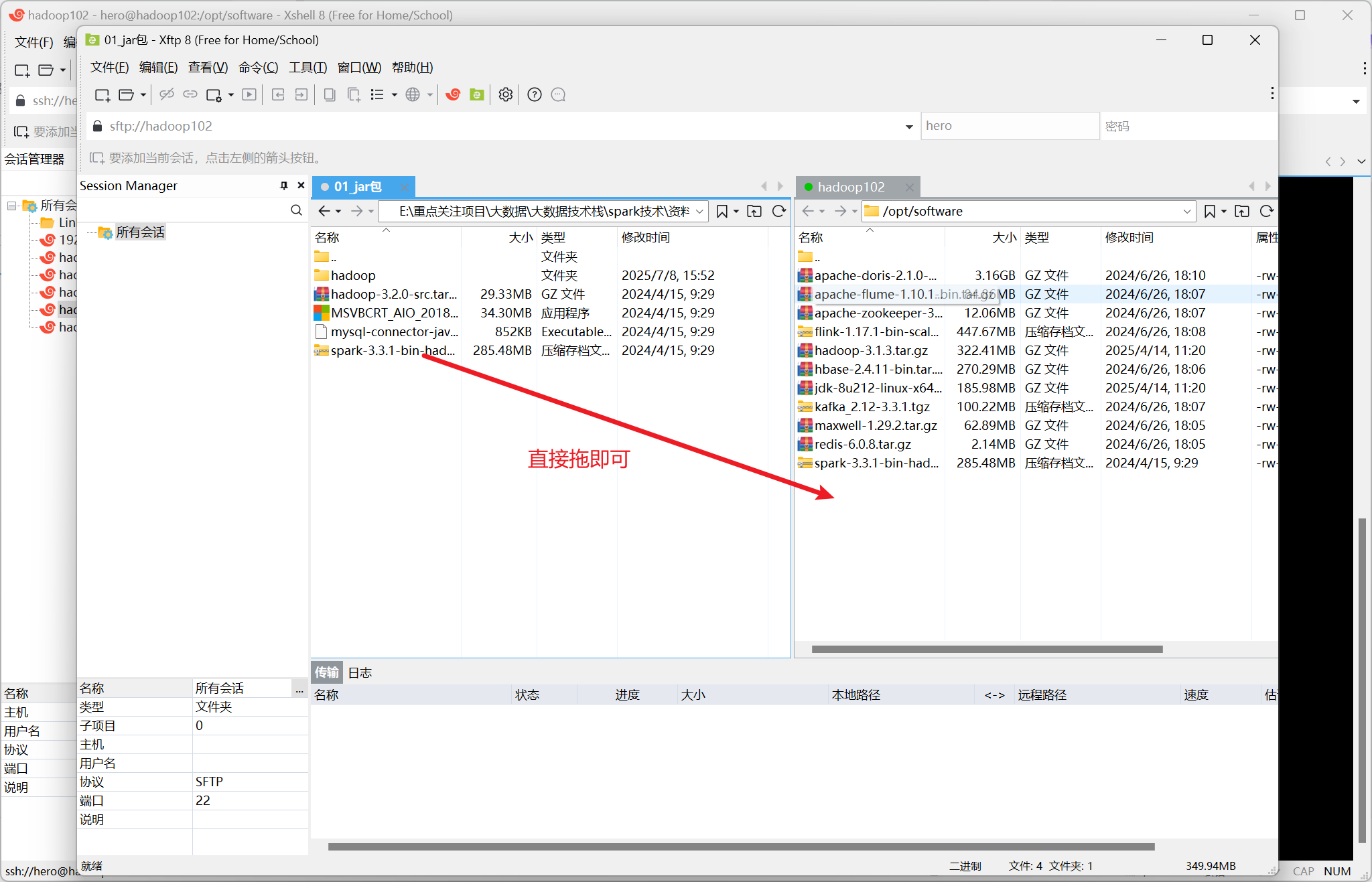
打开Xftp
安静等候传输完成
然后查看是否安装完成
紧接着返回上一级目录,并创建module目录
cd .. mkdir module
由于笔者已经创建好了目录,因此只放完成后的示意图
接着将压缩包解压至module目录下(注意必须在software目录中执行以下指令)
tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module/
接着进入software目录并将spark软件改名为spark-local
mv spark-3.3.1-bin-hadoop3 spark-local到此为止,spark环境已经部署完成啦~



第一个Spark作业
Local模式
如下图所示
指令解析
bin/spark-submit --class org.apache.spark.examples.SparkPi \ --master local[2] \ ./examples/jars/spark-examples_2.12-3.3.1.jar \ 100作为整个Spark系统的统一入口,在后面讲到的yarn模式下的指令类似
第一行
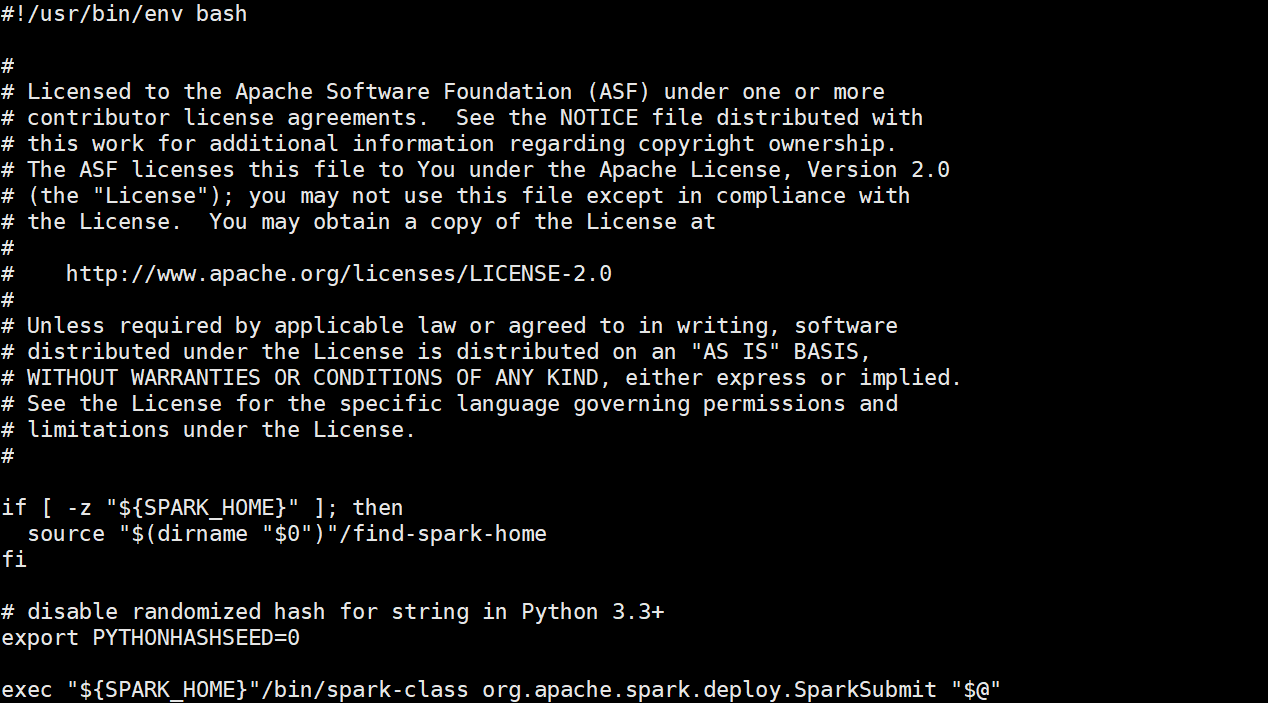
bin /spark-submit这里定位到spark-local目录中的bin目录,然后调用spark-submit脚本文件,找到该脚本如下
spark-submit脚本
这段脚本的大致的作用是作为整个Spark系统的统一入口,并有以下三个主要作用
1.找到spark的环境变量,否则执行find-spark-home脚本
2.禁止随机化,防止之后的shuffle分区不一致、join出错而导致数据倾斜等问题,确保
集群的hash一致性
3.使用exec命令替换当前的进程,调用spark-class脚本给主类SparkSubmit传递当前
脚本的所有参数
以下是三个部分的源码(find-spark-home、SparkSubmit、spark-class)
find-spark-home脚本
主要作用:自动确定SPARK_HOME环境变量的值
object SparkSubmit { // Cluster managers private val YARN = 1 private val STANDALONE = 2 private val MESOS = 4 private val LOCAL = 8 private val ALL_CLUSTER_MGRS = YARN | STANDALONE | MESOS | LOCAL // Deploy modes private val CLIENT = 1 private val CLUSTER = 2 private val ALL_DEPLOY_MODES = CLIENT | CLUSTER // Special primary resource names that represent shells rather than application jars. private val SPARK_SHELL = "spark-shell" private val PYSPARK_SHELL = "pyspark-shell" private val SPARKR_SHELL = "sparkr-shell" private val SPARKR_PACKAGE_ARCHIVE = "sparkr.zip" private val R_PACKAGE_ARCHIVE = "rpkg.zip" private val CLASS_NOT_FOUND_EXIT_STATUS = 101 // scalastyle:off println // Exposed for testing private[spark] var exitFn: Int => Unit = (exitCode: Int) => System.exit(exitCode) private[spark] var printStream: PrintStream = System.err private[spark] def printWarning(str: String): Unit = printStream.println("Warning: " + str) private[spark] def printErrorAndExit(str: String): Unit = { printStream.println("Error: " + str) printStream.println("Run with --help for usage help or --verbose for debug output") exitFn(1) } private[spark] def printVersionAndExit(): Unit = { printStream.println("""Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version %s /_/ """.format(SPARK_VERSION)) printStream.println("Using Scala %s, %s, %s".format( Properties.versionString, Properties.javaVmName, Properties.javaVersion)) printStream.println("Branch %s".format(SPARK_BRANCH)) printStream.println("Compiled by user %s on %s".format(SPARK_BUILD_USER, SPARK_BUILD_DATE)) printStream.println("Revision %s".format(SPARK_REVISION)) printStream.println("Url %s".format(SPARK_REPO_URL)) printStream.println("Type --help for more information.") exitFn(0) } // scalastyle:on printlnSparkSubmit源码
主要作用:Spark提交作业的类
if [ -z "${SPARK_HOME}" ]; then source "$(dirname "$0")"/find-spark-home fi . "${SPARK_HOME}"/bin/load-spark-env.sh # Find the java binary if [ -n "${JAVA_HOME}" ]; then RUNNER="${JAVA_HOME}/bin/java" else if [ "$(command -v java)" ]; then RUNNER="java" else echo "JAVA_HOME is not set" >&2 exit 1 fi fi # Find Spark jars. if [ -d "${SPARK_HOME}/jars" ]; then SPARK_JARS_DIR="${SPARK_HOME}/jars" else SPARK_JARS_DIR="${SPARK_HOME}/assembly/target/scala-$SPARK_SCALA_VERSION/jars" fi if [ ! -d "$SPARK_JARS_DIR" ] && [ -z "$SPARK_TESTING$SPARK_SQL_TESTING" ]; then echo "Failed to find Spark jars directory ($SPARK_JARS_DIR)." 1>&2 echo "You need to build Spark with the target \"package\" before running this program." 1>&2 exit 1 else LAUNCH_CLASSPATH="$SPARK_JARS_DIR/*" fi # Add the launcher build dir to the classpath if requested. if [ -n "$SPARK_PREPEND_CLASSES" ]; then LAUNCH_CLASSPATH="${SPARK_HOME}/launcher/target/scala-$SPARK_SCALA_VERSION/classes:$LAUNCH_CLASSPATH" fi # For tests if [[ -n "$SPARK_TESTING" ]]; then unset YARN_CONF_DIR unset HADOOP_CONF_DIR fi # The launcher library will print arguments separated by a NULL character, to allow arguments with # characters that would be otherwise interpreted by the shell. Read that in a while loop, populating # an array that will be used to exec the final command. # # The exit code of the launcher is appended to the output, so the parent shell removes it from the # command array and checks the value to see if the launcher succeeded. build_command() { "$RUNNER" -Xmx128m $SPARK_LAUNCHER_OPTS -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main "$@" printf "%d\0" $? } # Turn off posix mode since it does not allow process substitution set +o posix CMD=() DELIM=$'\n' CMD_START_FLAG="false" while IFS= read -d "$DELIM" -r ARG; do if [ "$CMD_START_FLAG" == "true" ]; then CMD+=("$ARG") else if [ "$ARG" == $'\0' ]; then # After NULL character is consumed, change the delimiter and consume command string. DELIM='' CMD_START_FLAG="true" elif [ "$ARG" != "" ]; then echo "$ARG" fi fi done < <(build_command "$@") COUNT=${#CMD[@]} LAST=$((COUNT - 1)) LAUNCHER_EXIT_CODE=${CMD[$LAST]} # Certain JVM failures result in errors being printed to stdout (instead of stderr), which causes # the code that parses the output of the launcher to get confused. In those cases, check if the # exit code is an integer, and if it's not, handle it as a special error case. if ! [[ $LAUNCHER_EXIT_CODE =~ ^[0-9]+$ ]]; then echo "${CMD[@]}" | head -n-1 1>&2 exit 1 fi if [ $LAUNCHER_EXIT_CODE != 0 ]; then exit $LAUNCHER_EXIT_CODE fi CMD=("${CMD[@]:0:$LAST}") exec "${CMD[@]}"Spark-class源码
主要作用:用于启动JVM并指定执行类SparkSubmit
第一行代码总结
spark-submit核心代码部分 主要作用 find-spark-home 找到SPARK_HOME环境变量并将变量返回给spark-submit SparkSubmit
相应Spark-class的请求,并将作业提交到最终的集群 Spark-class 接收spark-submit传递的参数,并创建JVM进程,执行SparkSubmit主类
第二行
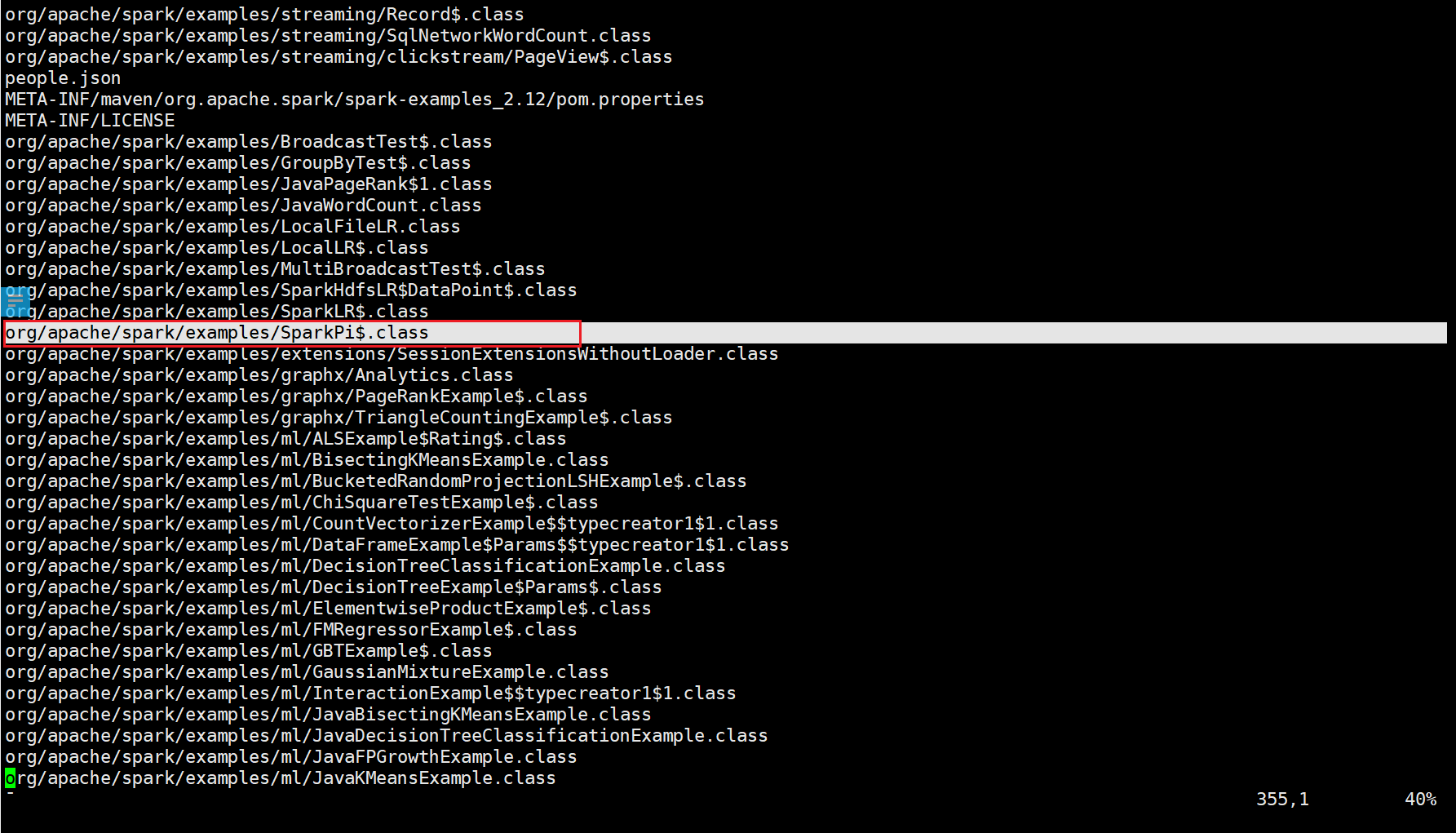
--class org.apache.spark.examples.SparkPi
这里打开spark-examples_2.12-3.3.1.jar包,找到如下类(画红色方框的)
将SparkPi的scala文件cv到idea中,如下图所示
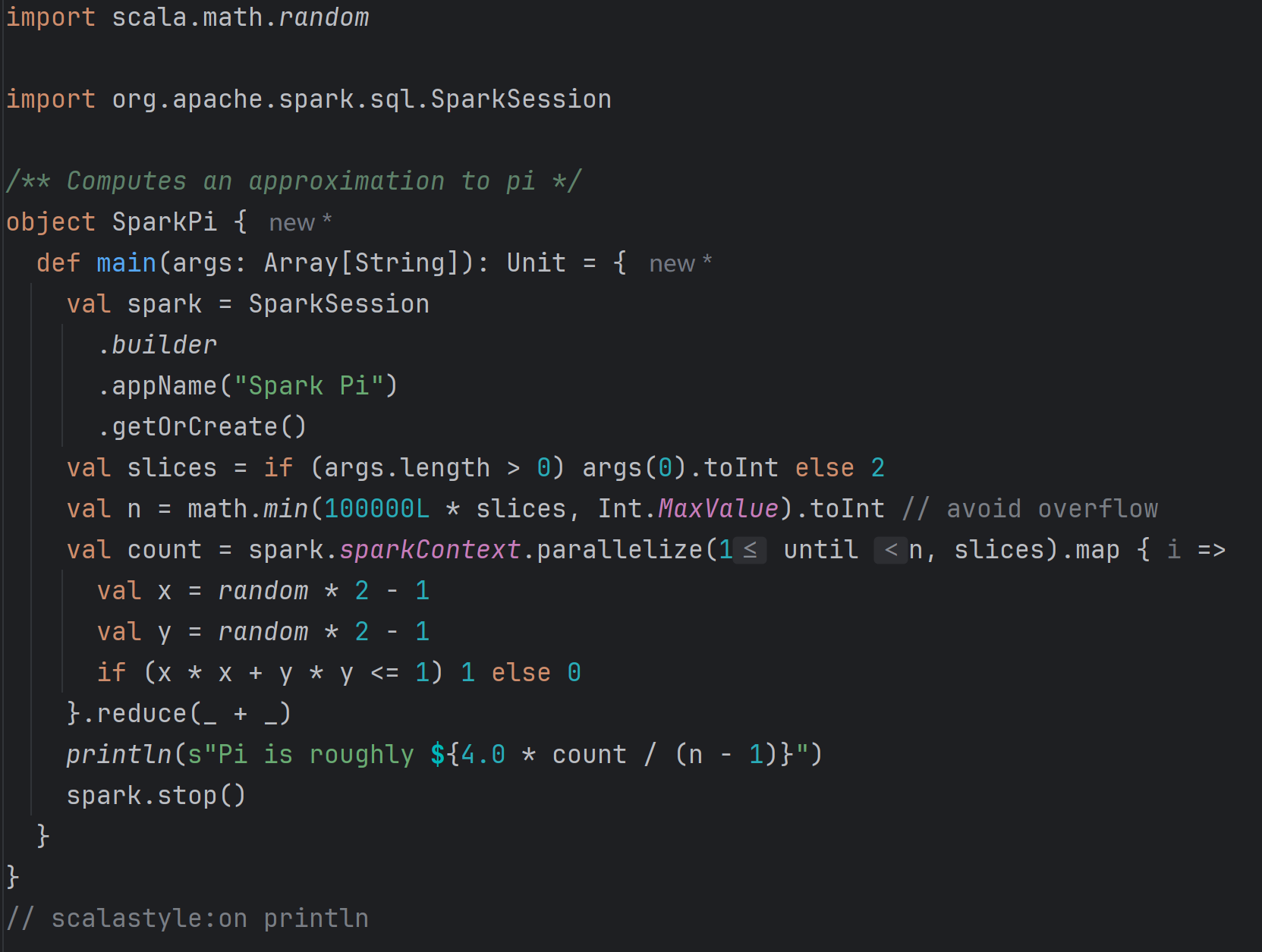
解析
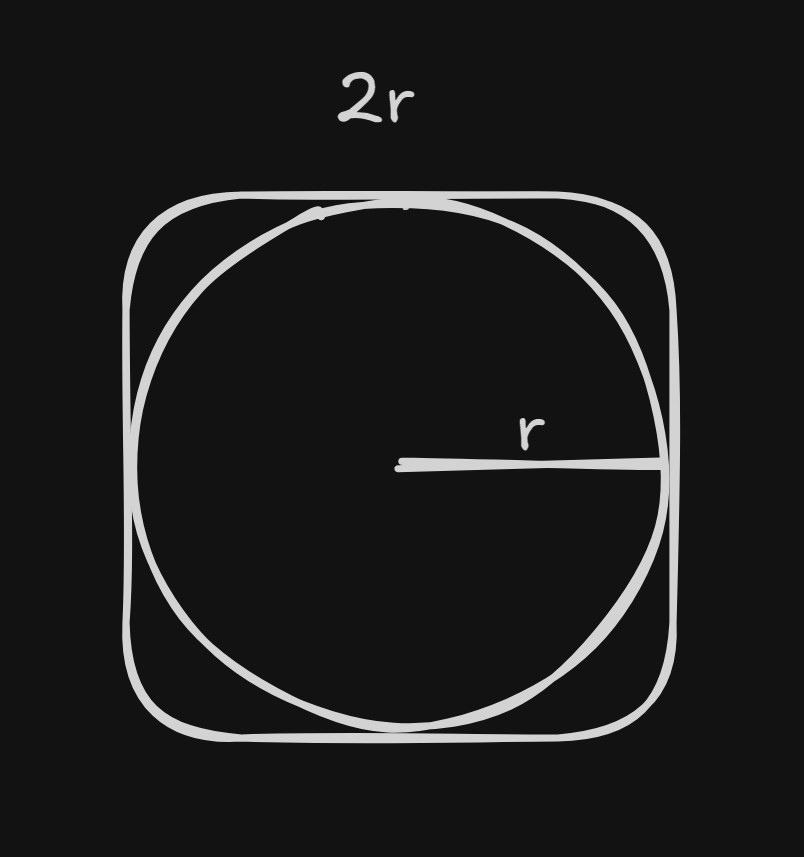
此方法采用了经典的“分布式蒙特卡洛方法”,计算Π的统计值。首先创建一个Spark会
话,然后设置参数slices和n,最后利用蒙特卡洛方法求得圆周率的统计值
蒙特卡洛数学原理(如图所示)
第三行
--master local[2]
输入bin/spark-submit之后查看相关参数如下
Options中的第一个参数解释
可知master是来指定集群管理器的,定义了Spark程序的运行地点,以及资源的分配
”Default: local[*]",表明默认是尽可能多的分配资源
Options中的第三个参数解释
表明了应用程序的主要执行类,例如本例中“--class org.apache.spark.SparkPi”,则指定
了用scala包下的SparkPi例子
第四行
./examples/jars/spark-examples_2.12-3.3.1.jar 100这里就是利用spark的example的jar包,里面有上百个字节码文件。后面的100是参数,
表示ags参数,最后会传递给SparkPi的main函数,并且启动十个进行蒙特卡洛计算的任务
找到这个jar包如下图
打开后发现通篇乱码(吓人)
后来发现打开方式有问题,应该使用vim或者vi打开才会正常
这个文件中包含了所有的案例,以供各位尝试
执行界面
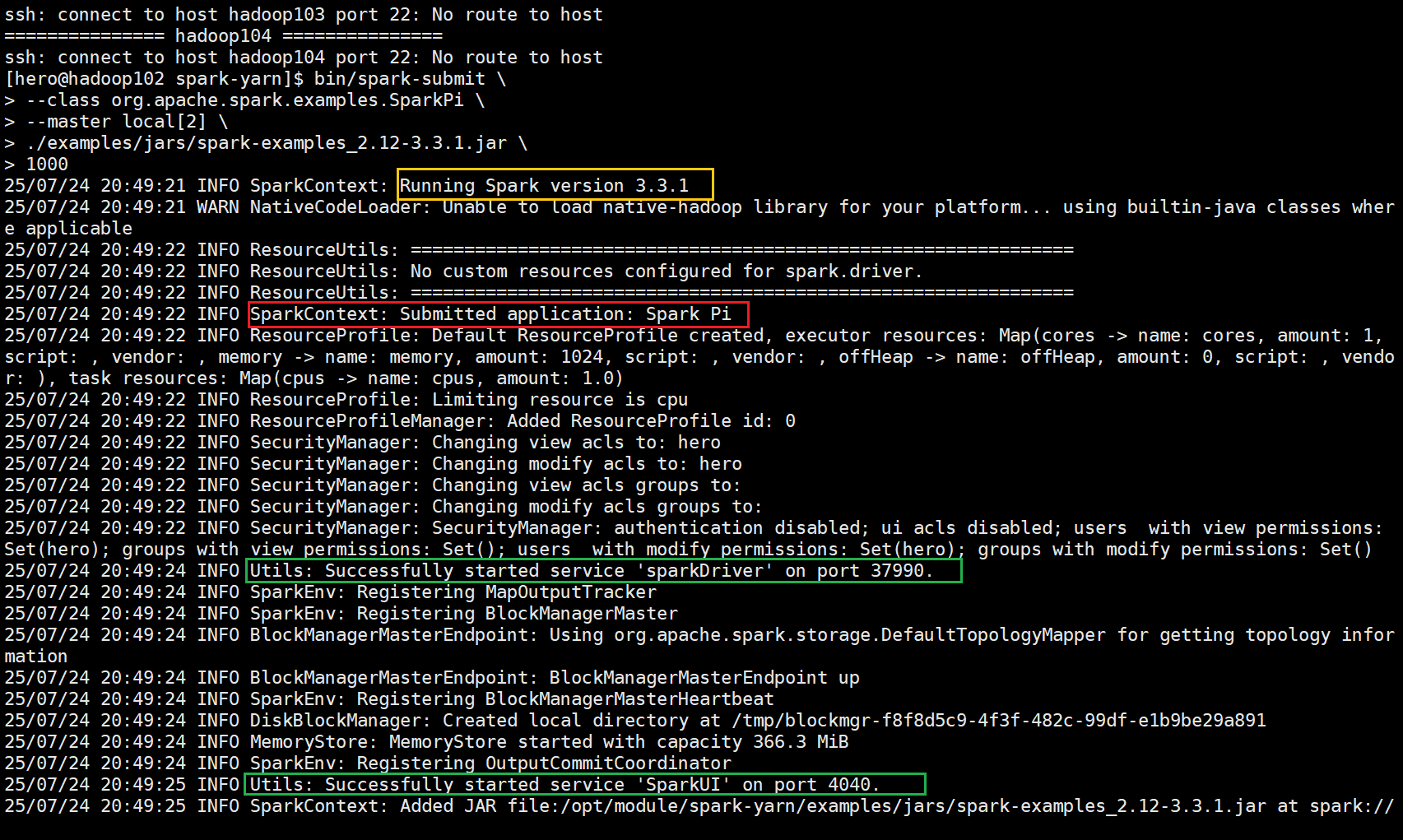
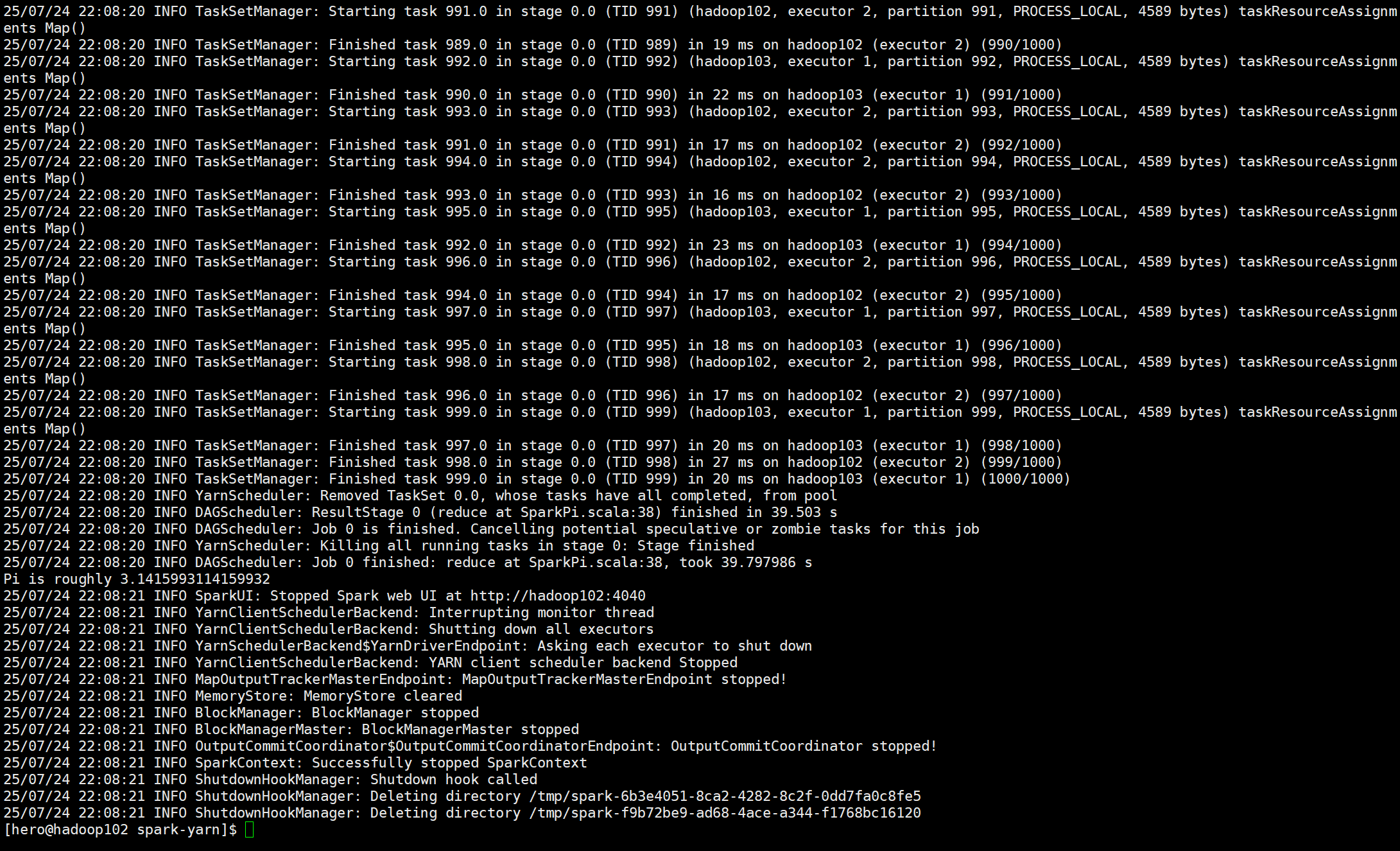
跑一次Local模式,监控其界面,对重要参数和内容进行具体分析
黄色部分展示Spark的版本信息
红色部分展示Spark任务的具体信息
绿色部分则是驱动Driver和UI界面的具体端口号
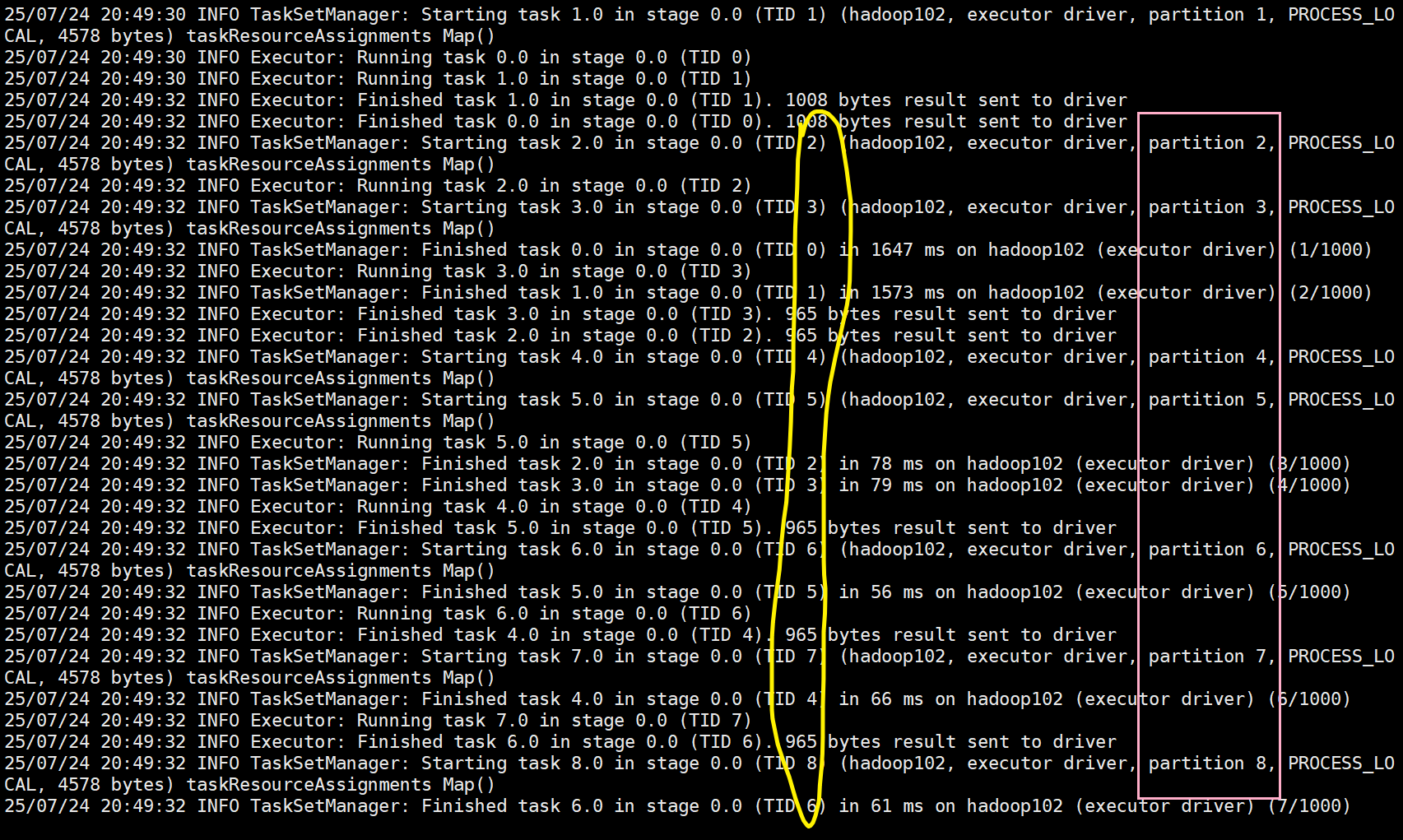
黄色部分则是具体的每个小Task,而粉红色部分则是具体的分区数,及1000个任务进行了
1000个分区
紫色部分和之前的黄色部分可以看出,Spark的计算是典型的并发计算,多个任务同时执行,
并且完成的先后顺序不定
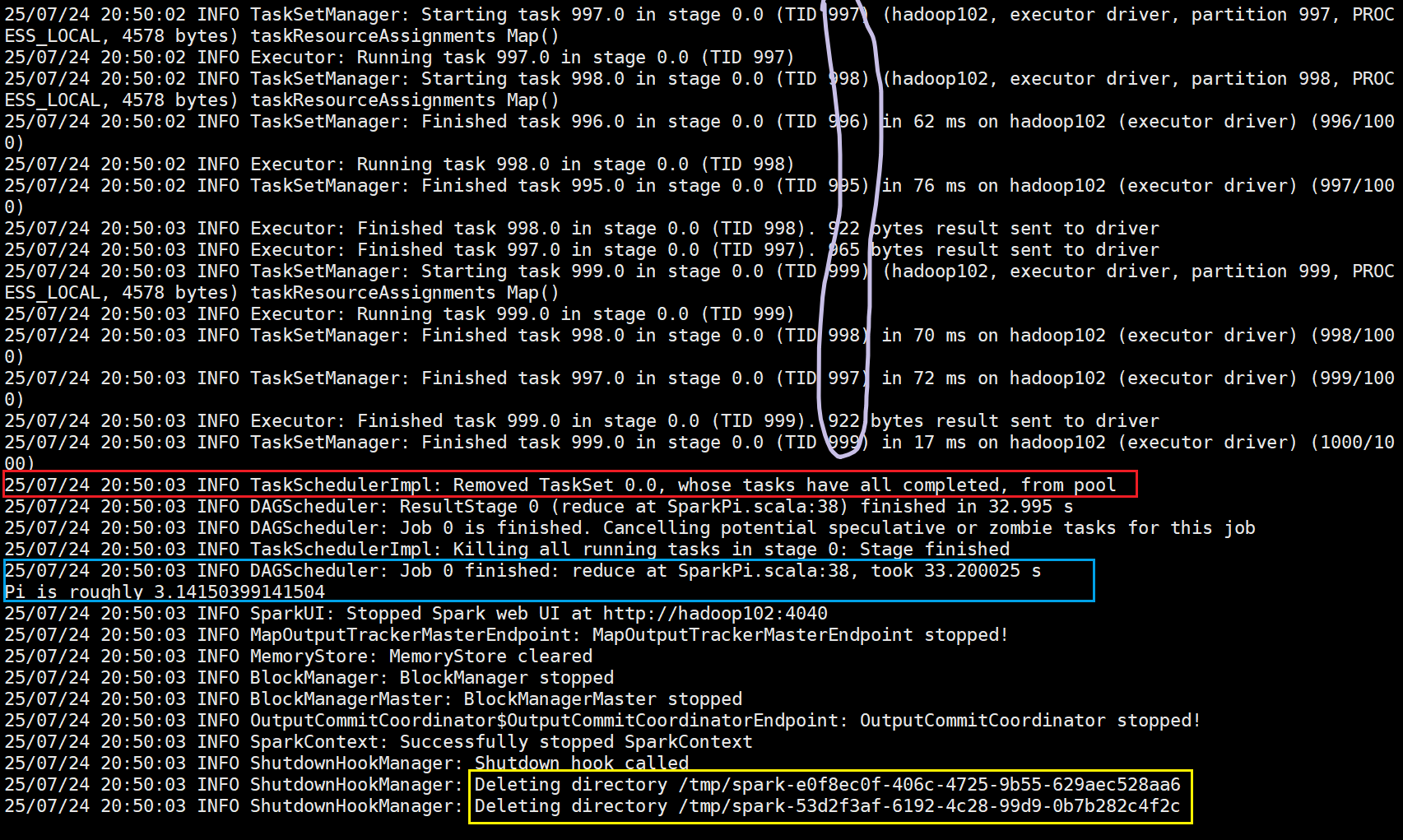
红色部分则是全部任务执行完之后就关闭相应的资源,这里是将任务集从池中丢弃
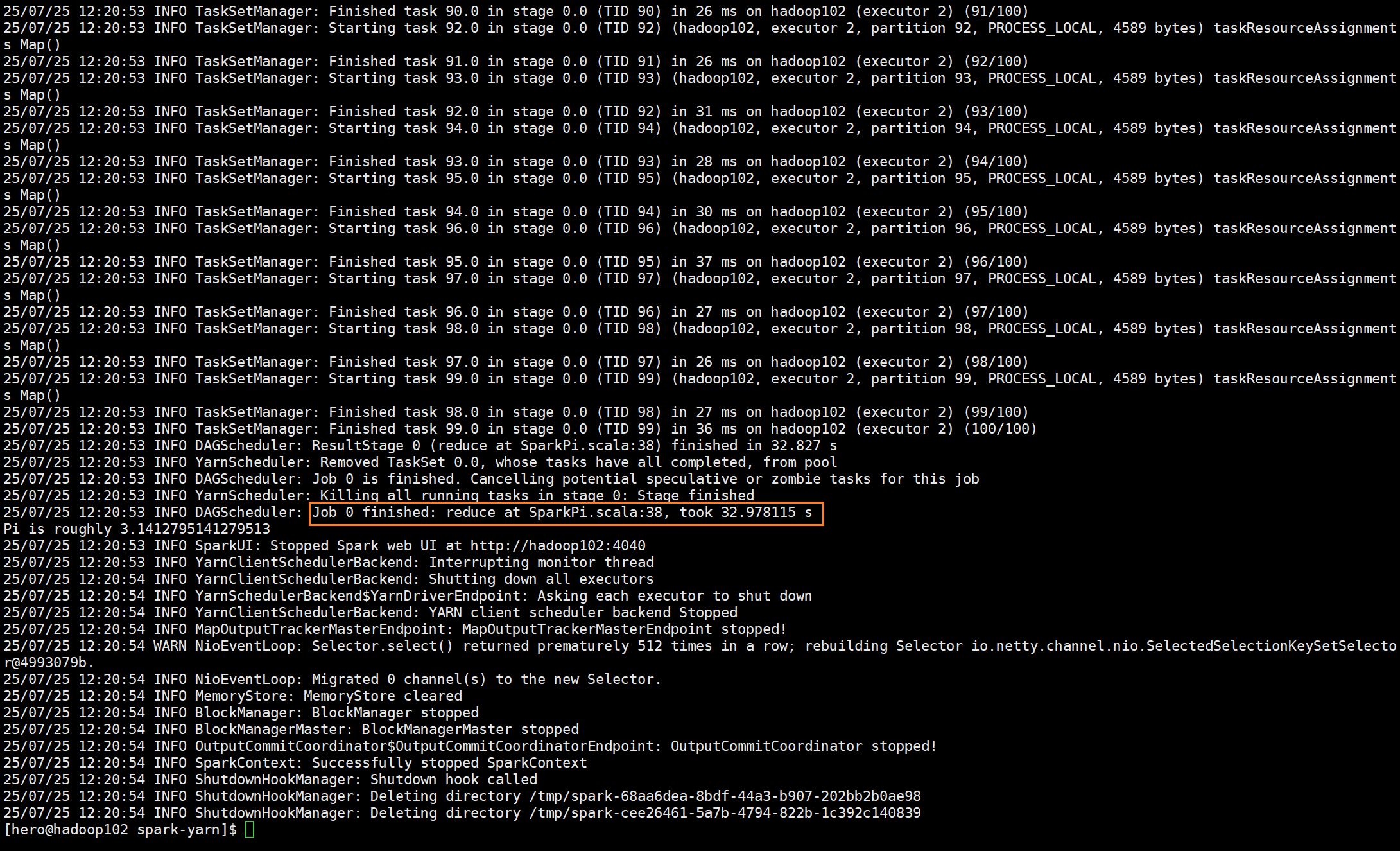
蓝色部分则是整个任务完成,reduce完成之后所花费的时间
黄色部分是由于yarn集群没有scala相应的环境,因此删除的部分其实是执行作业时上传的
scala相关的包和环境配置文件
Yarn模式
yarn模式需要重新解压并配置一遍文件,并找到spark-env.sh.template文件,在conf目录中
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop这里再将文件名修改
mv spark-env.sh.template spark-env.sh
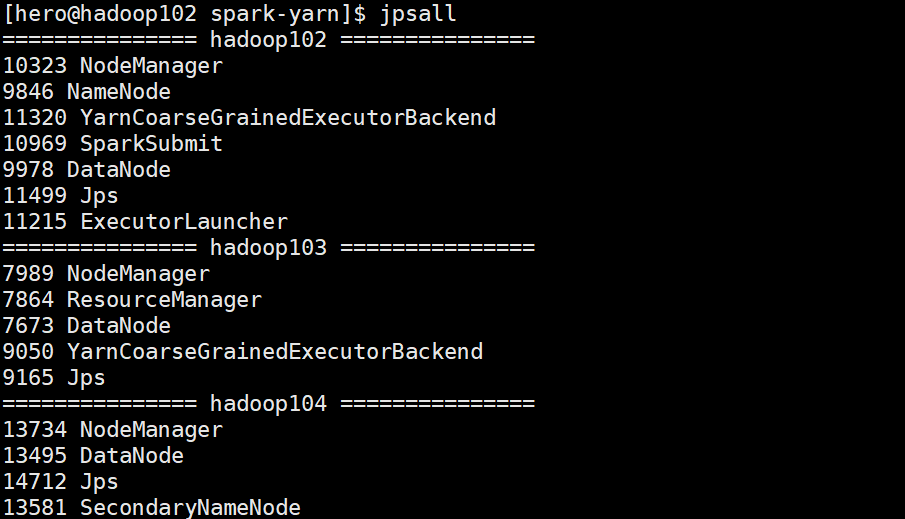
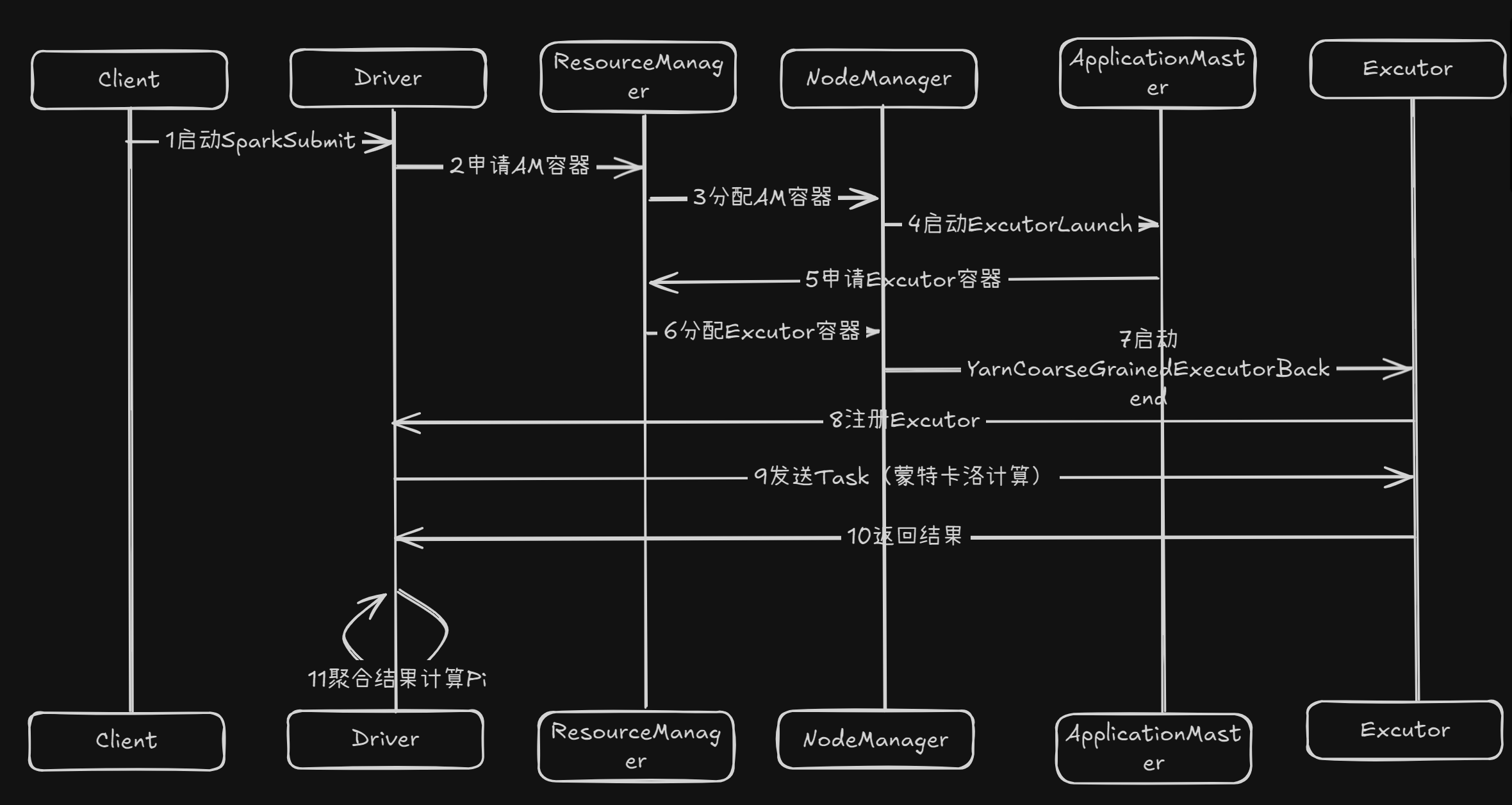
其中有三个重要的进程
分别是:SparkSubmit、YarnCoarseGrainedExecutorBackend、ExcutorLauncher
SparkSubmit是之前的老熟人了,它就在spark-submit脚本中,是spark-submit脚本启
动的JVM进程(Driver)并且通过这个进程启动SparkPi的main函数
YarnCoarseGrainedExecutorBackend就是执行者,真正干活的人。这个进程在yarn集群,执行具体的Task任务
ExcutorLauncher是Excutor的启动者,它在Yarn的Nodemanager中被启动,并且会
向Resourcemanager申请Excutor的执行资源,但不参与运算,只监控各个Excutor
执行和UI界面
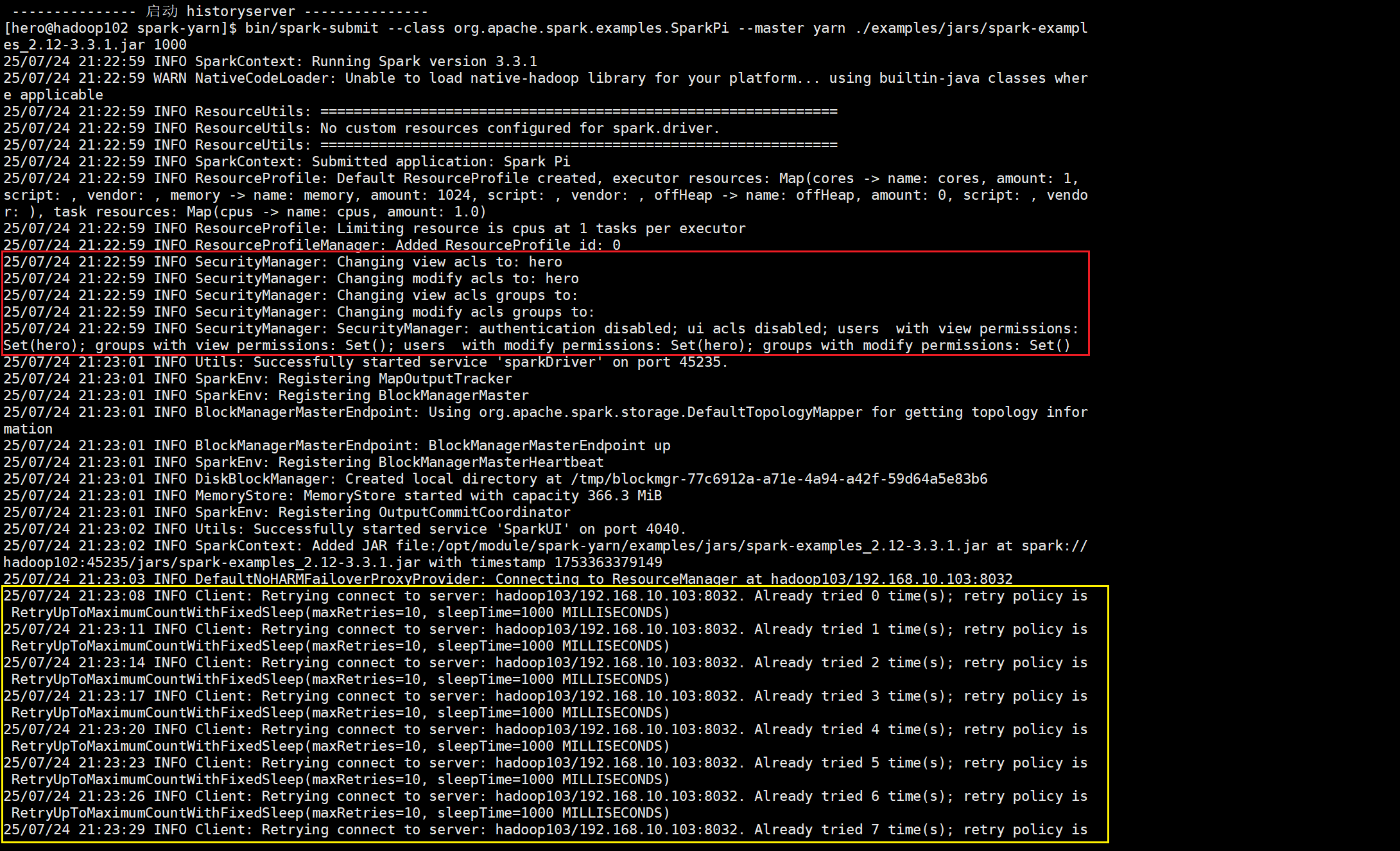
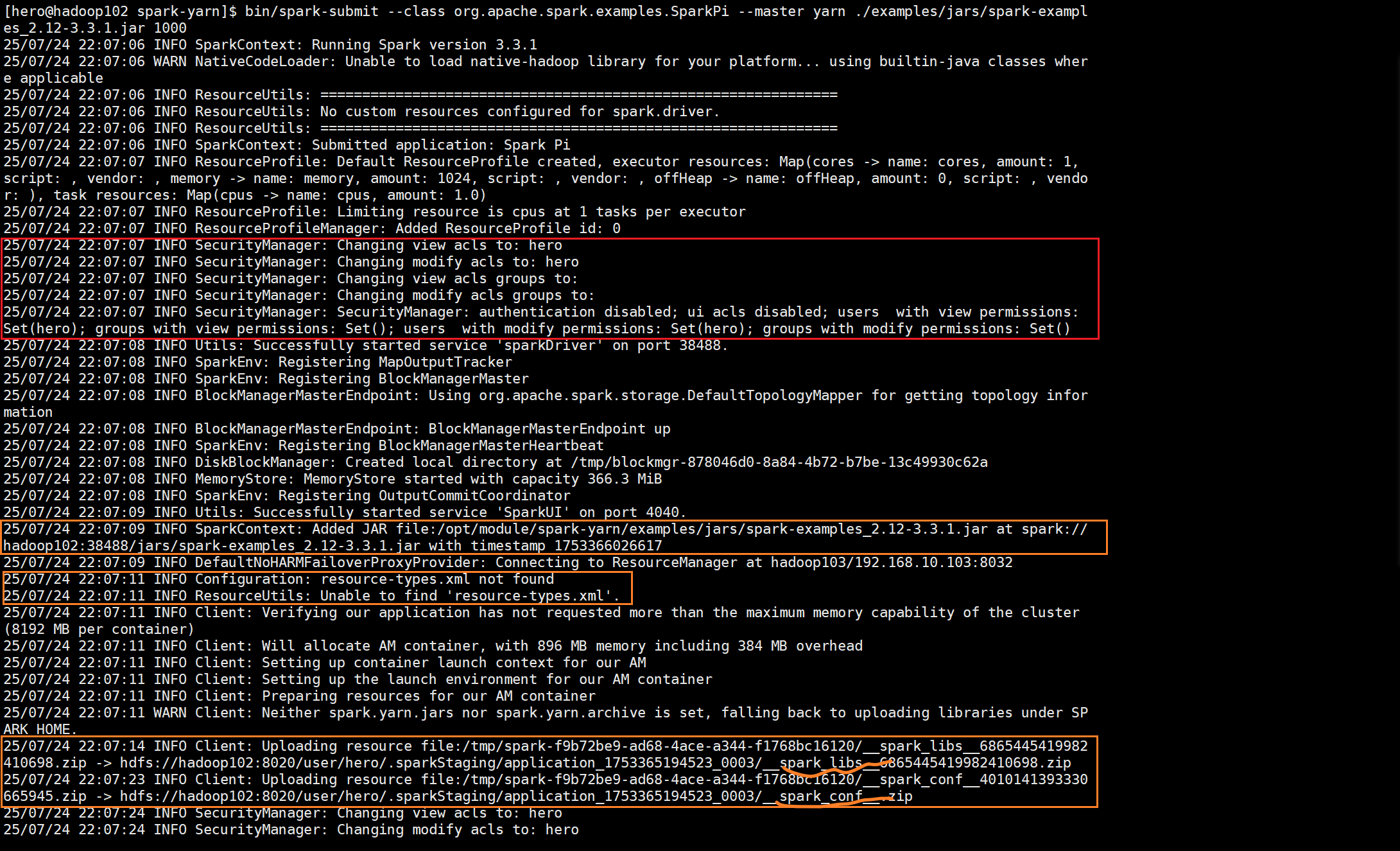
这里和之前的Local模式不同的是多出了安全检查和对集群的连接操作
第一个SparkContext(Spark会话)将本地的文件上传到集群服务器当中,客户端(也
就是本机“虚拟机”)将作业所需要的类库和配置文件上传到hadoop集群当中,因为hadoop集
群只有java类库和配置文件。
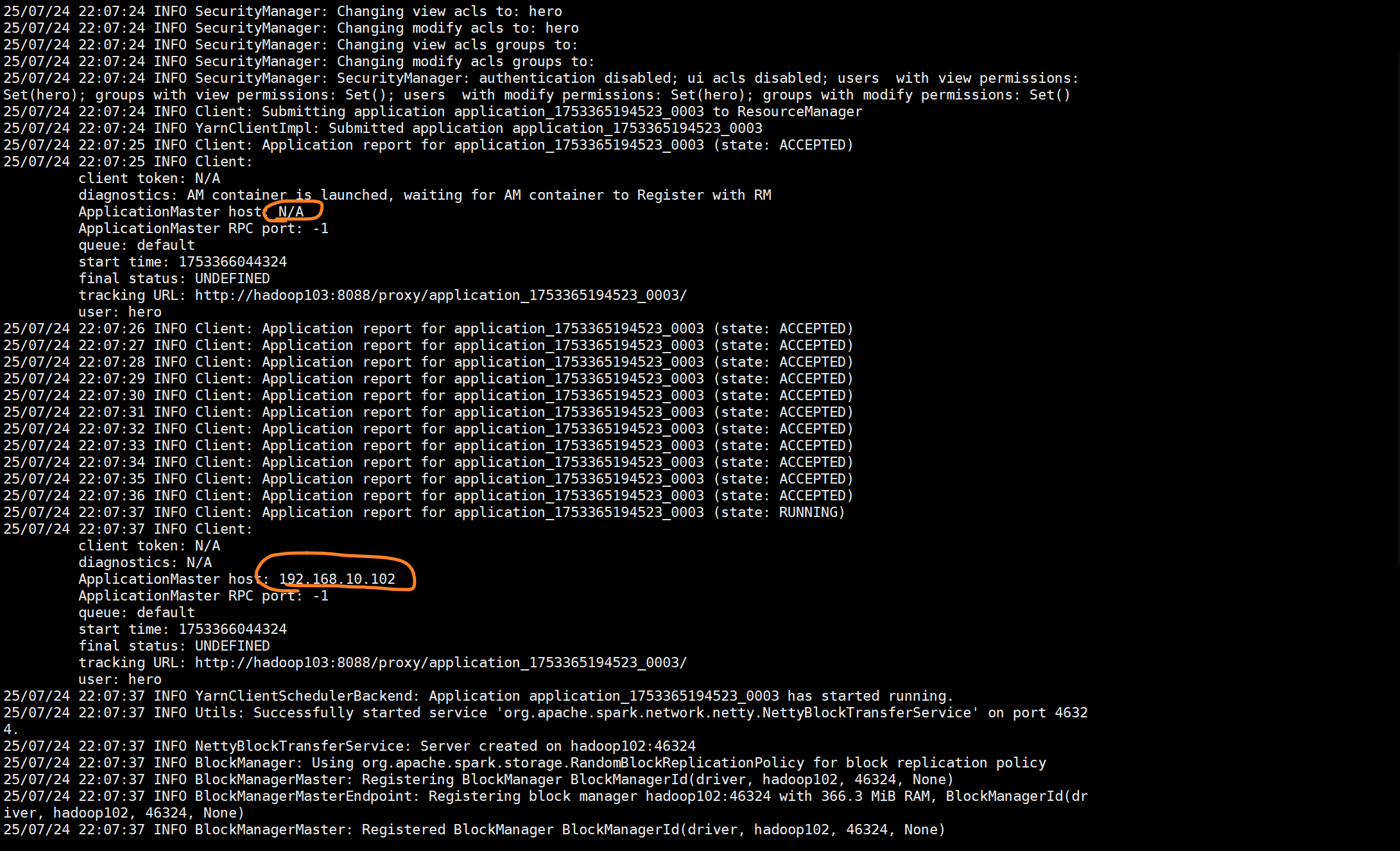
这里客户端和yarn集群在确认各种信息
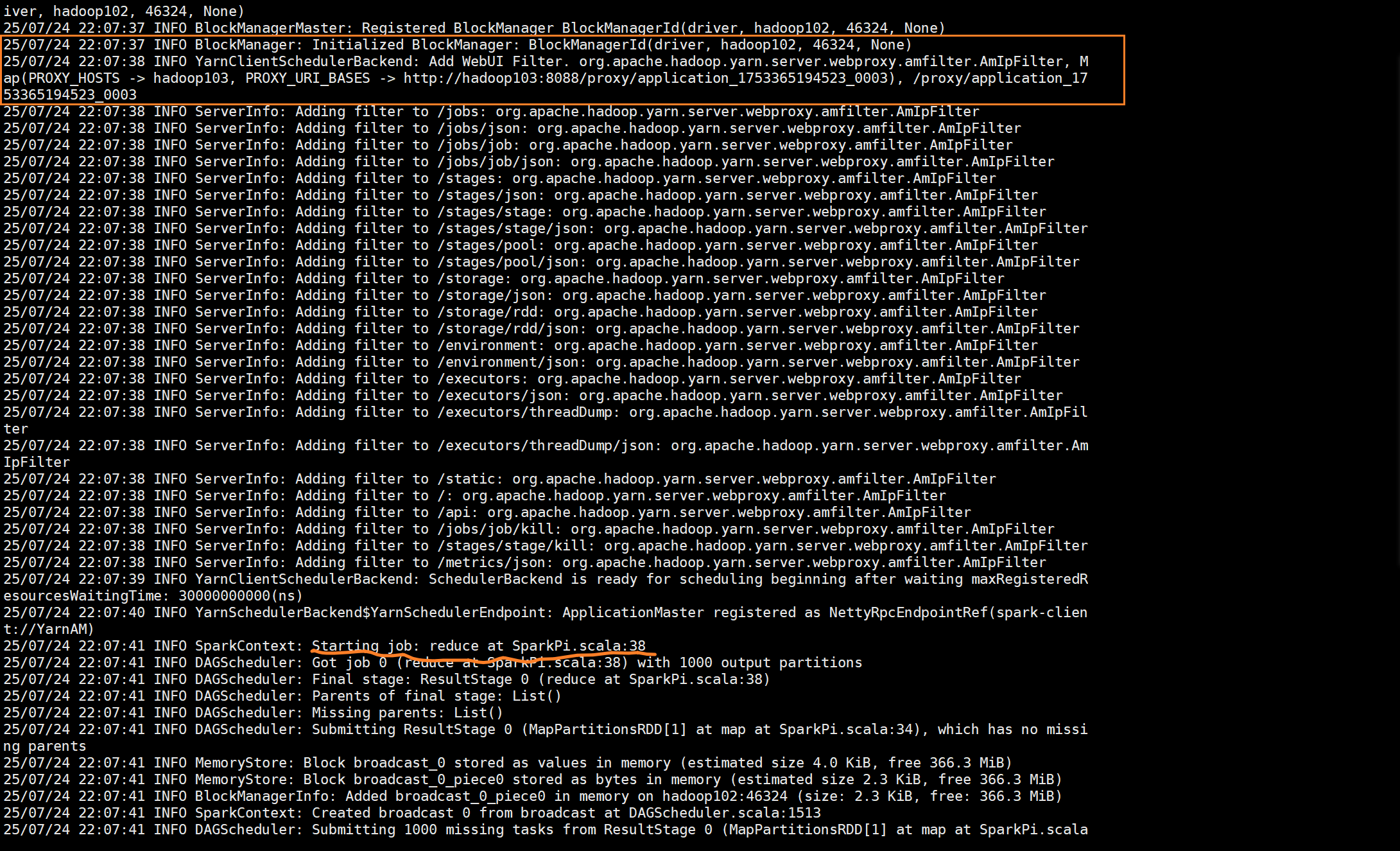
开始reduce工作
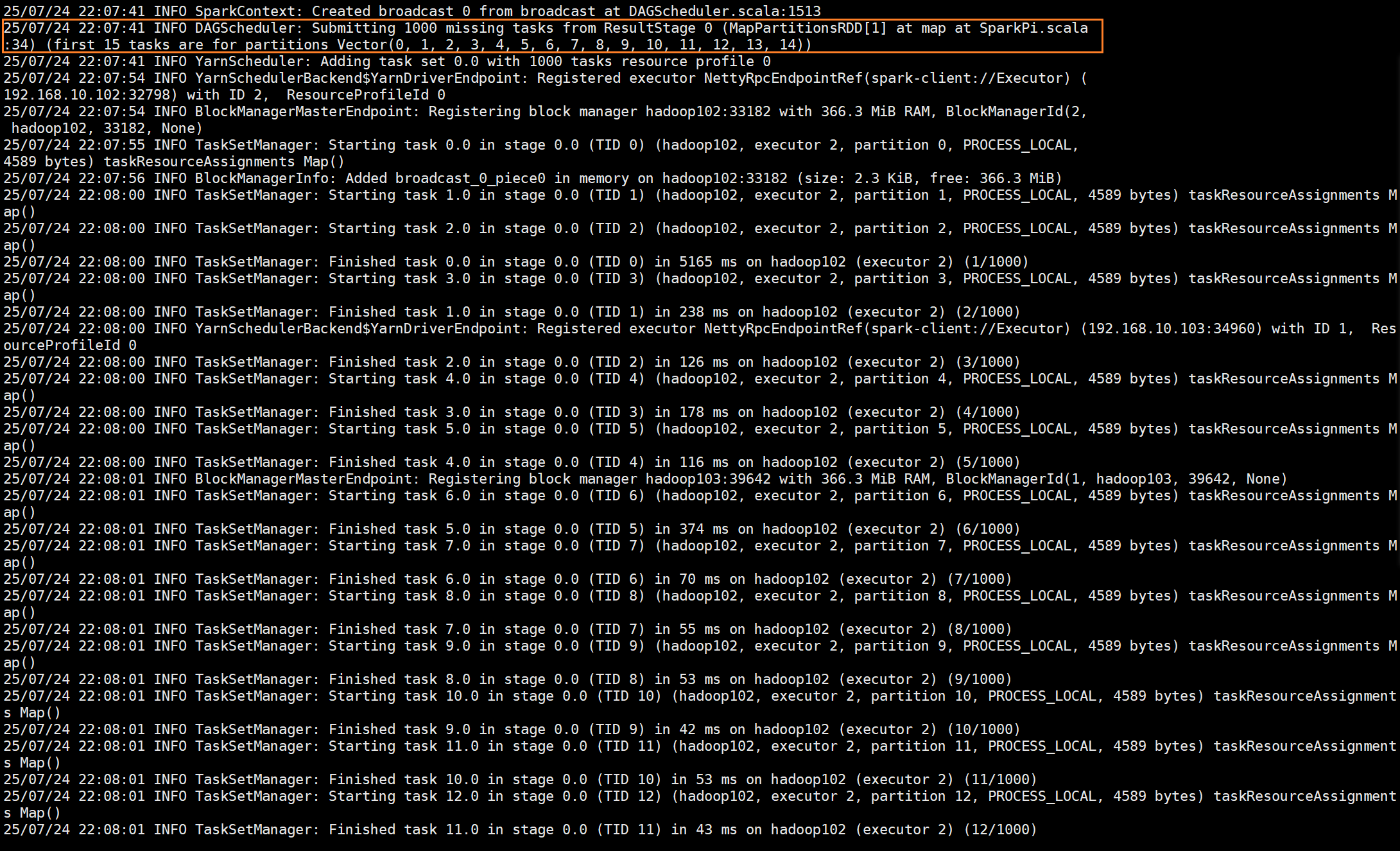
这里创建了一个广播,并且提交了1000份任务
最后完成的时候释放各种资源并卸载上传的内容
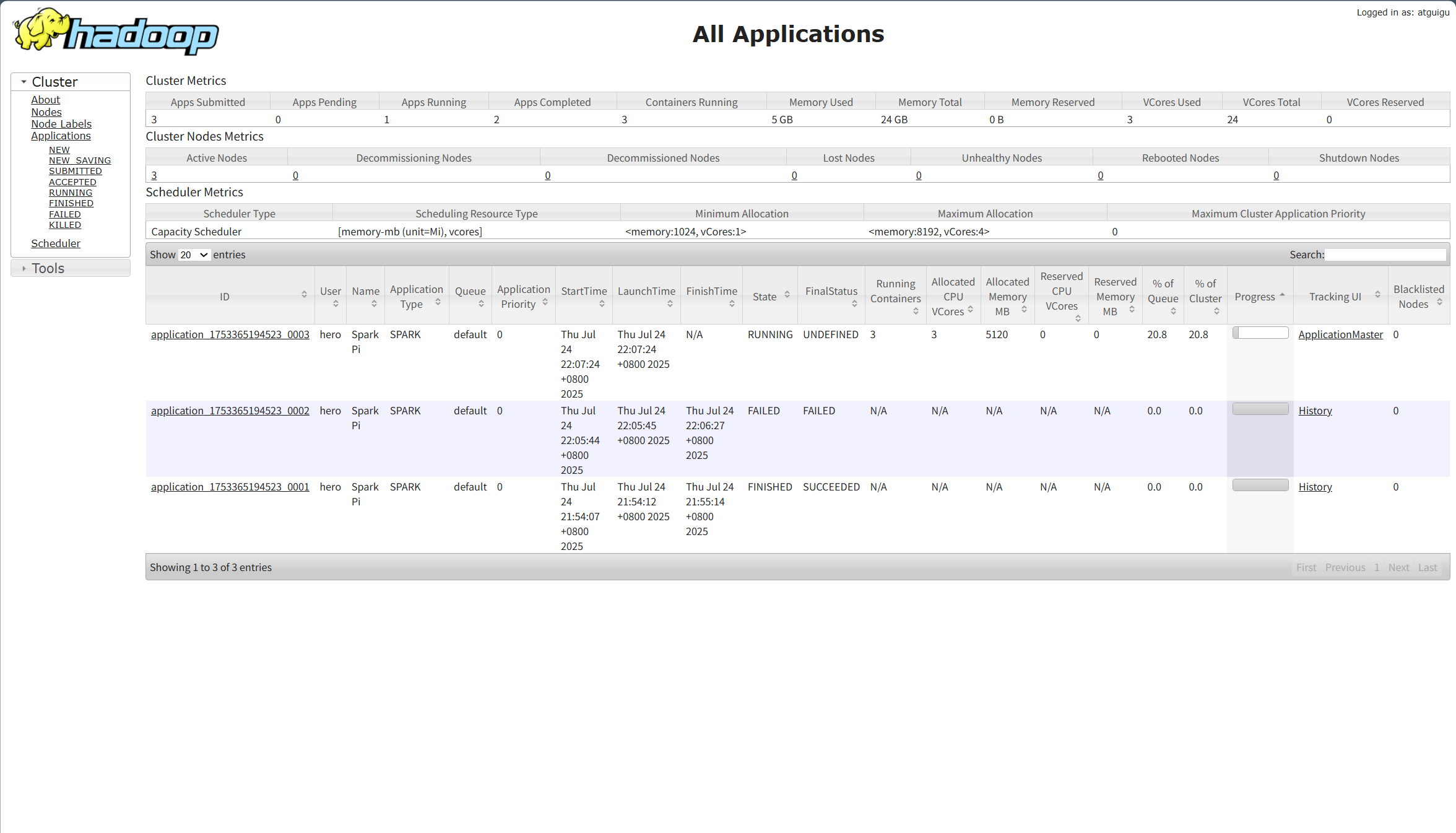
打开hadoop的MR任务界面可以清晰查看任务的运行情况和各种详情
这是完整的流程图~
逻辑图
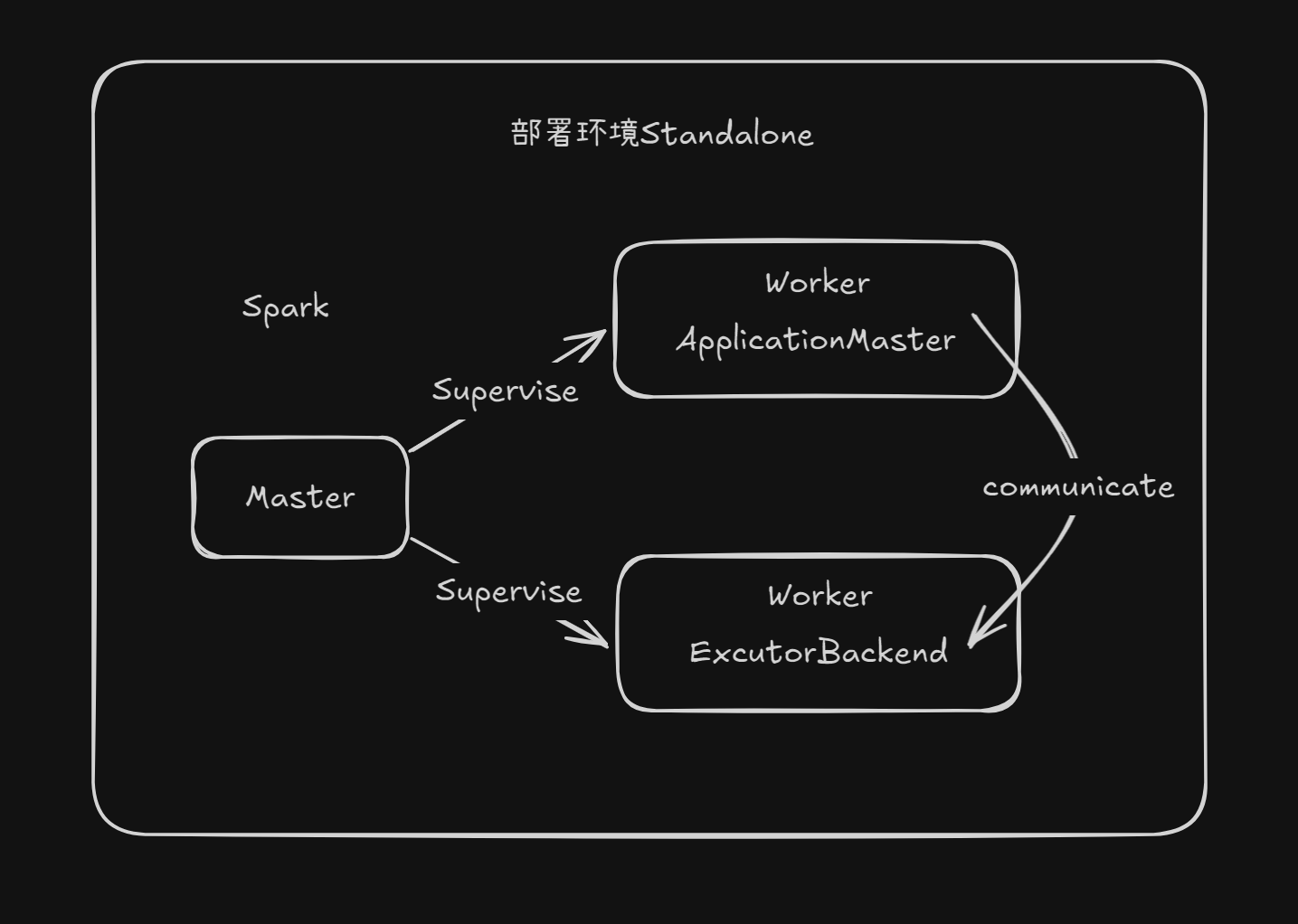
Standalone模式
Spark自带的资源调度引擎,并且由master和worker构成的Spark集群。(了解即可)
放一张架构图~
Mesos模式
Spark客户端直连Mesos;并且不需要额外搭建Spark集群。国内使用频率较低。
Spark和MR
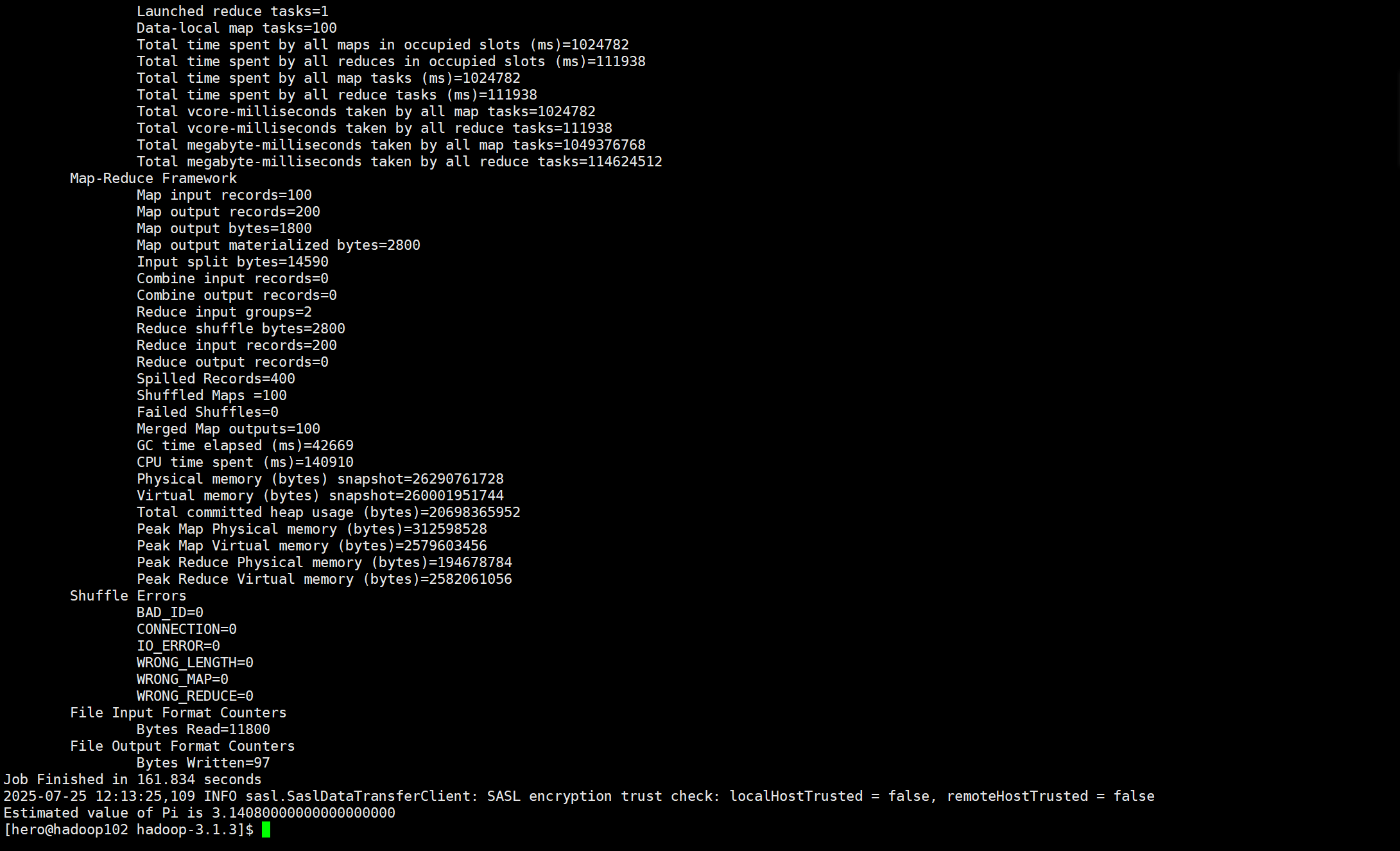
分别通过Spark的MR和hadoop的MR跑一次圆周率计算
PS:由于hadoop虚拟内存不够,从而在执行命令的时候抽风,花了几十分钟进行排错,重新配置文件等操作。。。
前面是Hadoop的MR:耗时161秒
后面是Spark优化过的MR耗时32秒
但是spark在执行任务前花费的时间也不少,但是前前后后花了一分多一点的时间,也远少于
hadoop的了
PS:创作不易,如果认为笔者写的还不错,请多点点免费的赞和收藏,并关注博主,Spark系列会持续更新!!!





















 1121
1121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









