







 本文详细探讨了IM系统的基础架构,包括其应用场景、常见术语以及企业级IM的核心架构,重点介绍了如何保证消息可靠投递、离线消息服务的高效实现以及海量历史聊天数据的存储策略,涉及RocketMQ和Redis等技术的应用。
本文详细探讨了IM系统的基础架构,包括其应用场景、常见术语以及企业级IM的核心架构,重点介绍了如何保证消息可靠投递、离线消息服务的高效实现以及海量历史聊天数据的存储策略,涉及RocketMQ和Redis等技术的应用。
一、IM系统概述
1、应用场景
IM系统就是即时通讯(Instant Messaging)系统的简称。
IM其实并不局限于聊天、社交这类“典型”应用中,实际上它已经广泛运用于我们身边形形色色的软件中。聊天、直播、在线客服、物联网等所有需要实时互动、高实时性的场景等,都需要应用IM技术。
1)微信、qq、钉钉等主流IM应用:这是IM技术的典型应用场景;
2)微博、知乎等社区应用:它们利用IM技术实现了用户私信等点对点聊天;
3)抖音、快手等直播/短视频应用:它们利用IM技术实现了与主播的实时互动;
4)米家等智能家居物联网应用:利用IM技术实现实时控制、远程监控等;
5)滴滴、Uber等共享家通类应用:利用IM技术实现位置共享;
6)在线教育类应用:利用IM技术实现在线白板。

2、IM系统常见术语
0)用户:系统的使用者。
1)消息:是指用户之间的沟通内容(通常在IM系统中,消息会有以下几类:文本消息、表情消息、图片消息、视频消息、文件消息等等)。
2)会话:通常指两个用户之间因聊天而建立起的关联。
3)群:通常指多个用户之间因聊天而建立起的关联。
4)终端:指用户使用IM系统的机器(通常有Android端、iOS端、Web端等等)。
5)未读数:指用户还没读的消息数量。
6)用户状态:指用户当前是在线、离线还是挂起等状态。
7)关系链:是指用户与用户之间的关系,通常有单向的好友关系、双向的好友关系、关注关系等等。
8)单聊:一对一聊天。
9)群聊:多人聊天。
10)客服:在电商领域,通常需要对用户提供售前咨询、售后咨询等服务(这时,就需要引入客服来处理用户的咨询)。
11)信箱:收发消息的Timeline、收发消息的队列。
3、IM系统基础架构
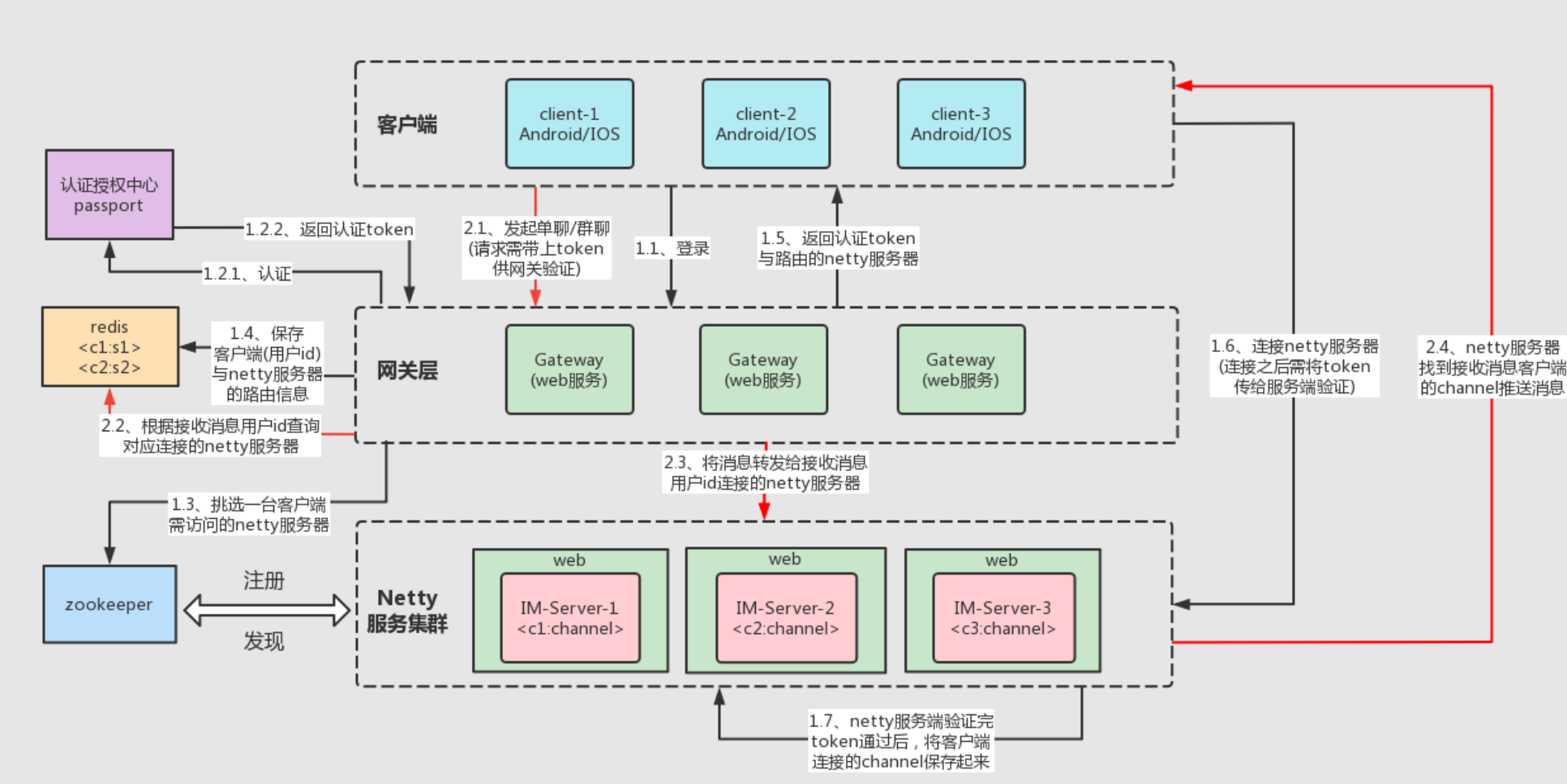
如上图所示,IM基础架构中的各分层职责如下:
1)客户端:作为与服务端进行消息收发通信的终端
2)网关层:也叫接入层,为客户端收发消息提供入口
3)服务层:负责IM系统各功能的核心业务逻辑实现,比如聊天服务、离线消息服务、红包服务、直播服务等
4)存储层:负责IM系统相关数据的持久化存储,包括消息内容、账号信息、社交关系链等
二、企业级IM系统核心架构
1、架构图
web层接收长连接/短连接。
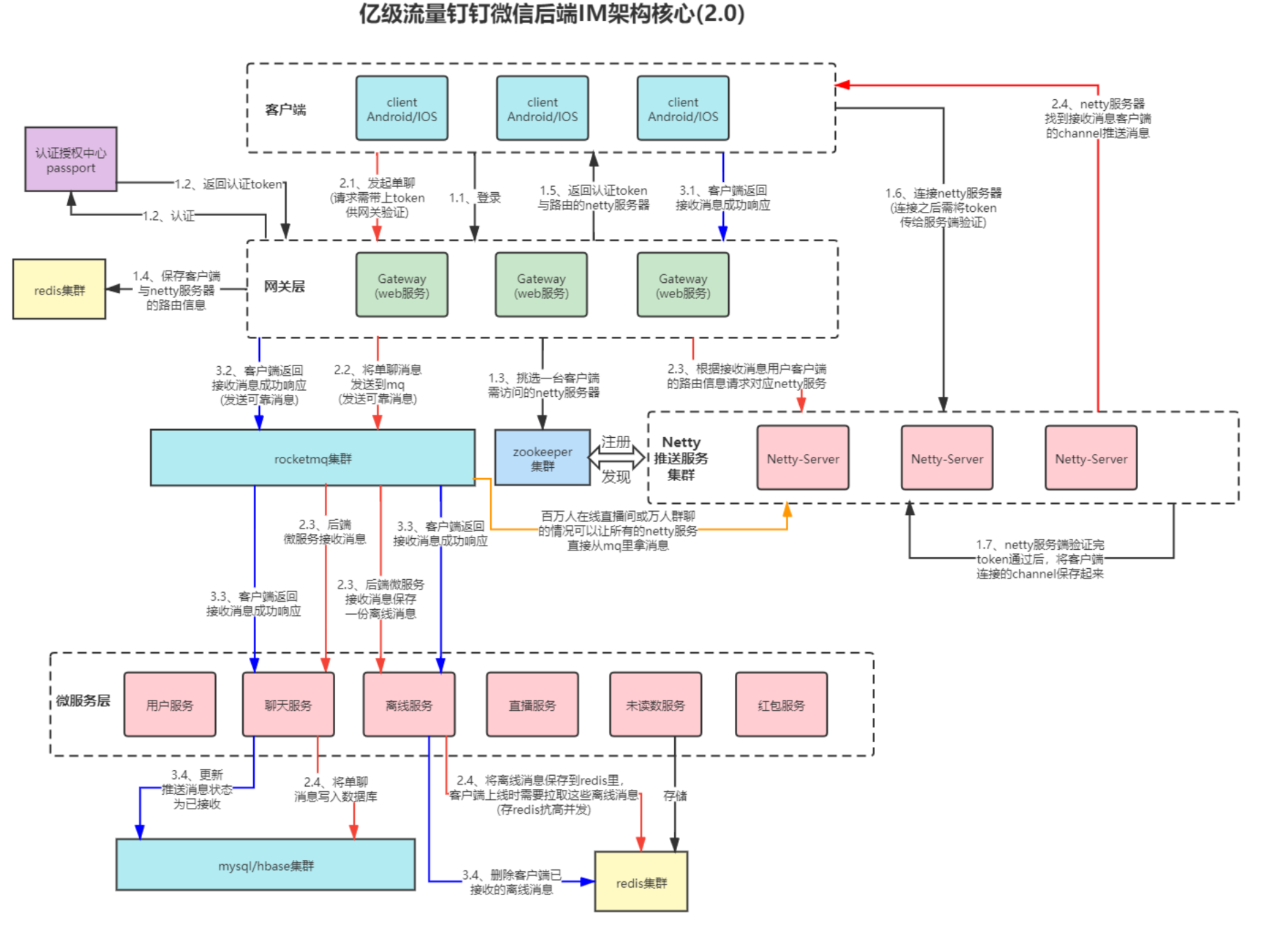
2、如何保证聊天系统消息的可靠投递(不丢消息)
- IM客户端发送消息如果超时或失败需要重发,客户端在发送消息时需要给每条消息生成一个id,IM服务端根据此id做好去重机制
- 为保证服务端消息不丢失,我们可以使用Rocket MQ的可靠消息机制来保证
- 通过客户端的ACK确认接收消息的机制来保证不丢消息
3、离线消息服务保证IM系统的高性能
- 离线消息就是用户不在线时别人发给他的消息,到用户上线时这些消息需要接收到,因为用户上下线可能是非常频繁的操作,一般是在用户上线时会主动拉取服务端的离线消息,如果直接从数据库里拉,则会对数据库造成极大的压力,所以对于离线消息我们一般会选择一些高性能的缓存来存储,比如Redis,这样能抗住高并发的访问压力。
- 当然Redis肯定是集群架构,而且会是很多节点,当然有同学也会担心这些离线消息肯定也是非常多的,Redis集群能存下吗,在大厂里Redis都是有很多节点的,可以存储很多T的数据,据说十年前新浪微博后端的Redis存储数据就已经达到几百T级别了,当然我们是可以设置一些存储策略的,比如,限制只存储最近一周或一个月的数据,然后再加一个存储消息的条数限制,比如一个用户的离线消息最多就存储最近的1000条。或者都按照存储条数的限制。
- 因为本身用户上线后查看离线消息很少会把历史所有的离线消息全部看完的,我们就展示最近的一些离线消息,如果用户一直往上翻离线消息,后面的消息可以从数据库查询,这种小概率的操作让数据库抗下来是没问题的。
4、海量历史聊天消息数据存储方案详解
- 消息存储结构参考数据库表结构设计(
分为收件箱和发件箱) - 发送消息处理
用户1给用户2发送一条消息,需要在消息内容表里存储一条记录,同时需要在用户信箱消息索引表存储两条记录,一条是用户1的发件箱,一条是用户2的收件箱,为什么要存储两条记录,因为会存在消息的收发方各自删除记录的情况。 - 查询聊天消息处理
查看用户1跟用户2的聊天记录,首先可以先分页查询聊天消息索引的id,select mid,box_type from im_user_msg_box t where t.owner_uid = 1 and t.other_uid = 2 order by mid;(注意要分页查),然后再for循环在im_msg_content表查每条消息内容展示。
因为聊天消息数据巨大,我们肯定要考虑数据库的分库分表方案,im_user_msg_box表我们可以按照 owner_uid 来分,这样我们正常的聊天记录查询是不需要跨表查询的,im_msg_content表我们可以按照 mid 来分,因为查询消息基本都是按照消息id主键来查,性能非常高。 - 关于表设计的解释
这里解释下为什么将收发消息分为用户信箱消息索引表和消息内容表两张表来存储,因为很多时候消息内容会比较大,所以分成两张表来存储的好处在于,如果我们有时候只是需要读取一些消息收发的关系,而不关注消息内容的时候我们只需要查询用户信箱消息索引表即可,而不需要查询消息内容这种大数据表,对性能有一定提升。收发消息方可能存在各自删除消息的情况,所以要存储两份消息索引,因为我们将消息索引和消息内容是分开存储的,所以也不会导致消息内容这种大数据被存储多份。
三、feed流场景设计
1、feed流场景核心
feed流场景核心动作:关注、取关、发布feed、拉取feed。
核心数据:好友关系数据、feed数据。
2、订阅(关注)关系存储
好友关系,可以考虑使用图数据库,或者使用双向的K->List结构存储。
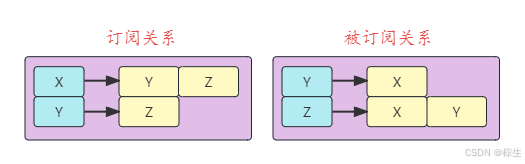
用户 X 订阅了 Y 和 Z,那么在 “订阅关系” 中,Key 是 X,List 中元素包括 Y 和 Z;用户 Y 订阅了 Z,那么在 “订阅关系” 中,Key 是 Y,List 中元素包括 Z。
在 “被订阅关系” 中,Y 被 X订阅,则 Key 是 Y,List 中元素包括 X; Z 被 X 和 Y 订阅,则 Key 是 Z,List 中元素包括 X 和 Y。
3、(微信消息的)读扩散与写扩散
(1)写扩散
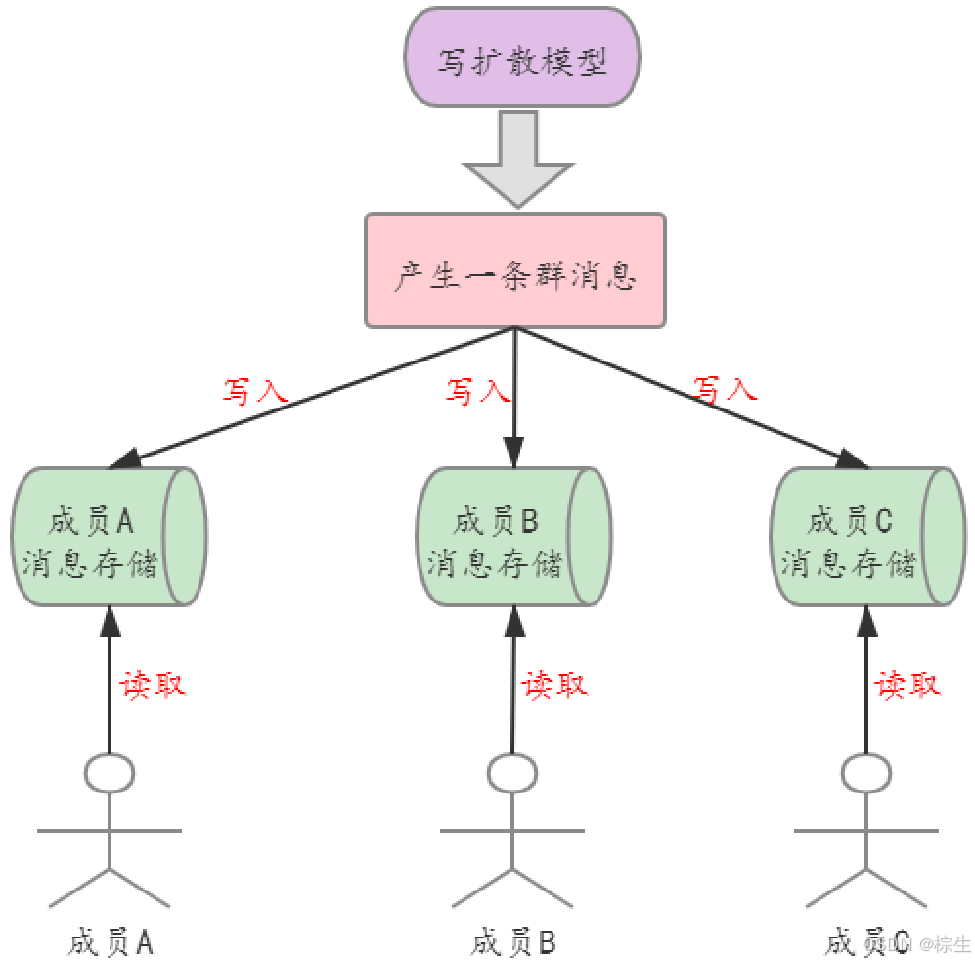
在 IM 的写扩散模型中,每一个群成员都有自己独立的 “信箱”(即消息存储);当产生一条群消息时,需要分别投递(写入)到每个成员的信箱中;每个成员对群消息进行读取时,只需要从自己的信箱中拉取消息即可。
写扩散模型最大的优点就是读取逻辑非常简单,尤其是在大规模用户高并发读取时,避免了锁操作,有较大的性能优势;同时,因为存储隔离,方便了消息的定制化处理。
写扩散模型最大的缺点就是消息的存储成本很大,发送消息操作较为耗时,思考一下,为什么微信群成员数量的上限是 500? 同时,写扩散队列在落地实现时有非常高的技术复杂度。
写扩散模型通常应用在群成员数量不高,读多写少的业务场景中。
IM 写扩散模型中,每产生一条消息,需要分别投递到每个成员的独立信箱中;该模型读取逻辑简单,方便消息的定制化处理,在高并发读时有较大的性能优势;但是该模型的存储成本很大,写扩散队列落地复杂。
(2)读扩散
当一个群成员的数量是 10 或 100 时,我们可以使用 “写扩散模型” 解决方案,当群成员数量是 1000 或 10000 时,写扩散模型会因为冗余写导致非常高的写延时,这肯定是不可取的,此时可以使用 “读扩散模型” 方案,见下图。
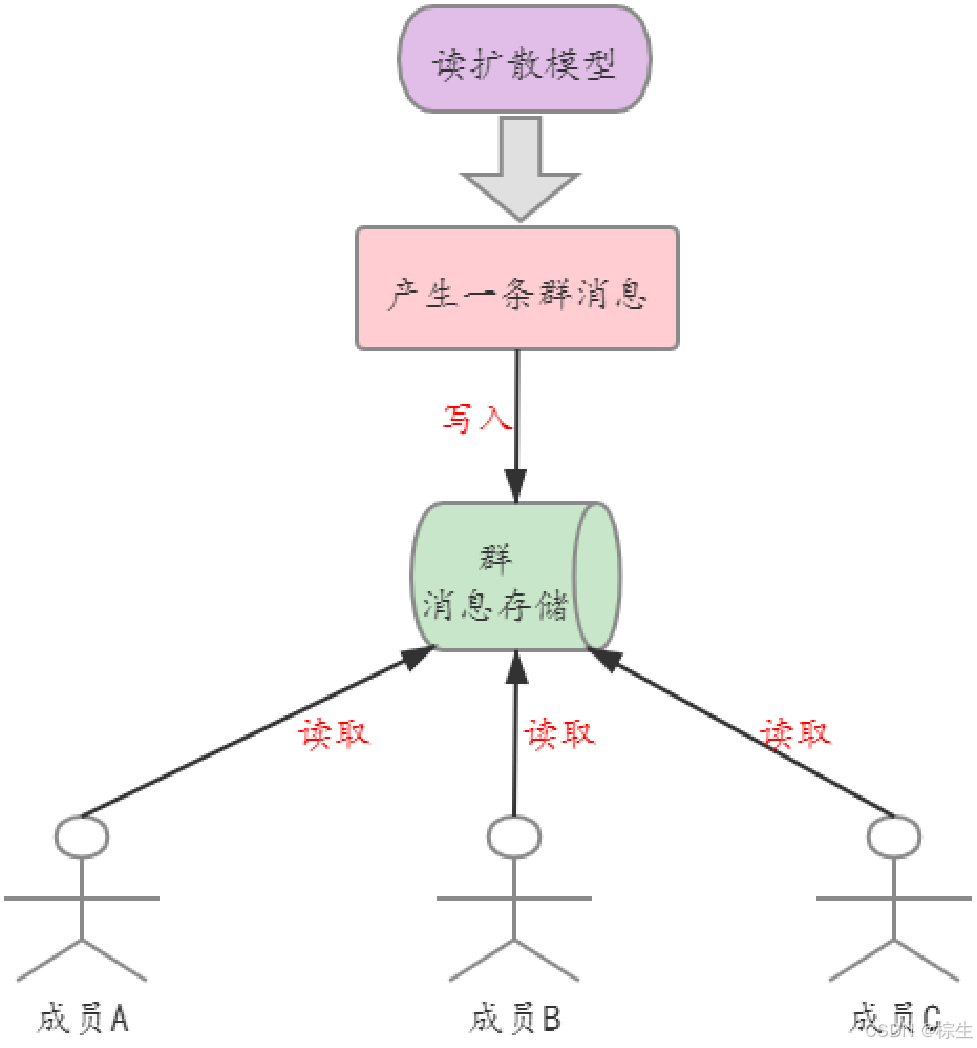
在 IM 的读扩散模型中,所有的群成员共享同一个信箱(群消息存储);当产生一条群消息时,只需要将一条群消息记录投递(写入)到信箱中即可;然后所有的群成员从这一个信箱中读取群消息。
看到这里,细心的同学肯定会发出疑问,这样的设计方式,消息的定制化处理怎么做呢?比如:成员 A 删除了一条群消息,这肯定不能影响到其他群成员对这条群消息的浏览。这就是读扩散模型的核心了:需要专门设计一张 “群消息删除表” 来记录删除的群消息id,每个群成员从信箱中读取群消息后,再读取 “群消息删除表”,以此判断该群消息是否展示。
读扩散模型最大的优点就是消息的写入逻辑简单(毕竟只写一条记录即可),消息的存储成本较低,写入的实时性好,没有时延问题。
读扩散模型最大的缺点就是数据的读取逻辑复杂,不仅要读取消息存储表,还要读取其他业务表后进行数据聚合;另外一个非常关键的问题是多用户并发读取时会形成 IO 的热点,造成性能的急剧下降。
读扩散模型通常应用在群成员数量很高,读少写多的业务场景中。
IM 读扩散模型中,每产生一条消息,只需写一条记录即可;该模型消息的写入逻辑简单,存储成本低,实时性好;不过数据的读取逻辑复杂,在多用户并发读取时会有 IO 热点问题。
4、(朋友圈的)读写扩散
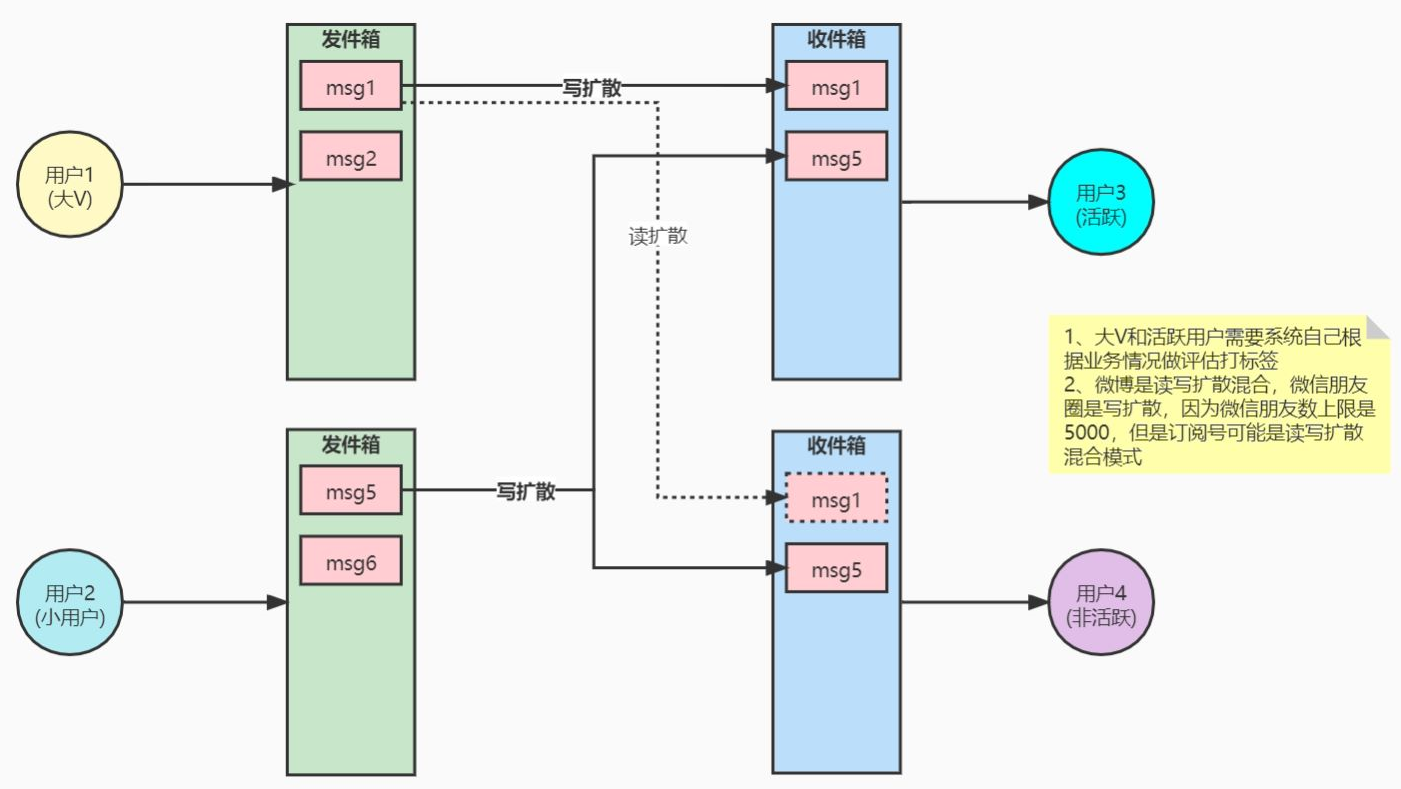
读扩散(拉模式):
每次都需要获取所有的好友,然后拉取好友的朋友圈进行时间排序。
缺点:每次涉及大量的读取和内存排序操作。
缺点:热点数据会成为瓶颈(关注者比较多的人的数据)。
写扩散(推模式):
用户发布朋友圈时,直接将朋友圈内容写入到每个好友和自己的收件箱中。
如果添加了新的好友,还需要同步朋友圈内容到新好友的收件箱中。
优点:用户查看朋友圈只需要查询自己的收件箱即可,没有热点数据瓶颈。
缺点:数据存储量大,每次发布朋友圈需要写入数据多。适合读多写少的场景。
5、写扩散的存储优化
可以在每个人收件箱,只存储消息的id,不存储消息的全部数据。
查询的时候,不要一次性全查出来,使用懒加载的方式进行数据查询。
四、微信红包系统设计
1、微信红包和微信支付的关系
可以理解为,微信红包是微信支付的一个商户。
微信红包卖的商品就是“钱”。
发红包相当于商品上架,抢红包相当于查商品详情……
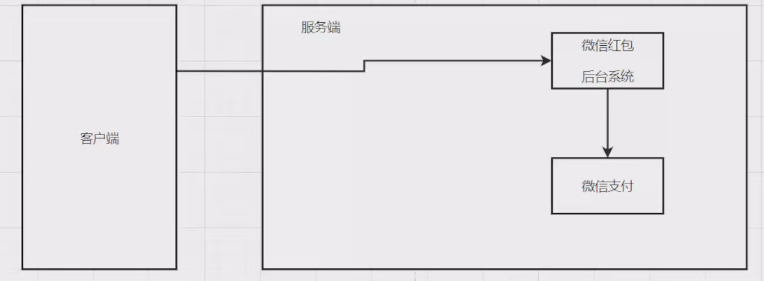
2、微信红包功能解析
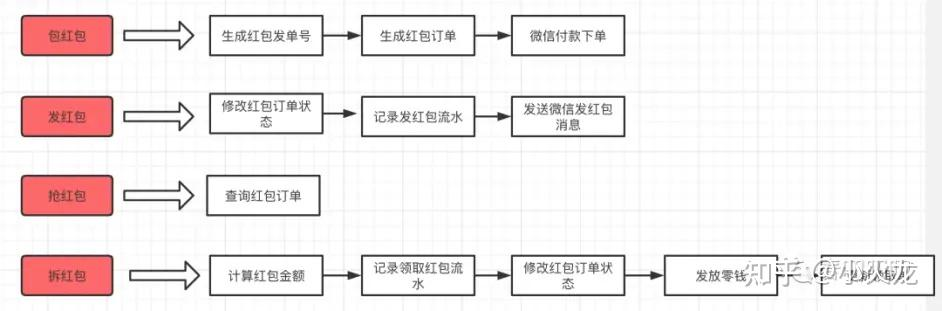
包红包:填写红包个数、金额。
1、生成红包订单ID,根据红包信息生成红包订单。
发红包:通过微信支付把红包发出去。
1、通过微信支付付款,支付成功后将订单状态更新为“已支付”,写入用户发红包记录流水。
2、将消息发送给接收红包的人。
抢红包:点红包进行抢红包。
1、点开红包,点击“抢”,这个过程就是抢红包。
2、判断红包是否被抢完,是否过期等等。
拆红包:服务器端进行拆红包。
1、查询红包是否被抢完。
2、计算金额。
3、抢成功后,记录抢红包记录。
4、微信支付,把红包变为我的零钱。
查红包:查询抢红包的结果。
1、查询红包记录。
3、基础数据库设计
1、用户余额表:用户ID、用户余额。
2、红包表:红包ID、发送者信息、红包类型、红包金额、红包数量、发送时间、过期时间、已经领取的红包、是否领完……
3、红包领取记录表:红包ID、领取者信息、领取金额、领取时间……
4、微信红包业务特点
1、海量业务并发。
每个红包,都相当于秒杀活动。
尤其是除夕、节假日。
2、资金交易,不能出错。
红包多抢一个、少抢一个都不可以,必须金额一分不差!
5、微信红包技术实现
1、微信红包的存储set化:
将红包ID根据Hash,分流到不同的服务和数据库中,这样相当于对流量和存储进行了拆分。
2、限制请求数量。(请求排队)
比如一个红包有5份,总共100个人抢,可以先剔除95个人,剩下的5个人再执行拆红包、转账。
3、双维度表设计
红包ID根据哈希进行拆分。
红包的历史数据与当前红包的数据分开存储,按天进行分离。(比如昨天发的红包,比今天发的红包热度肯定会下降很多,冷热分离)
4、异步队列
发红包:更新余额,记录发放记录等可以异步操作。
拆红包:也可以并行执行一些操作。
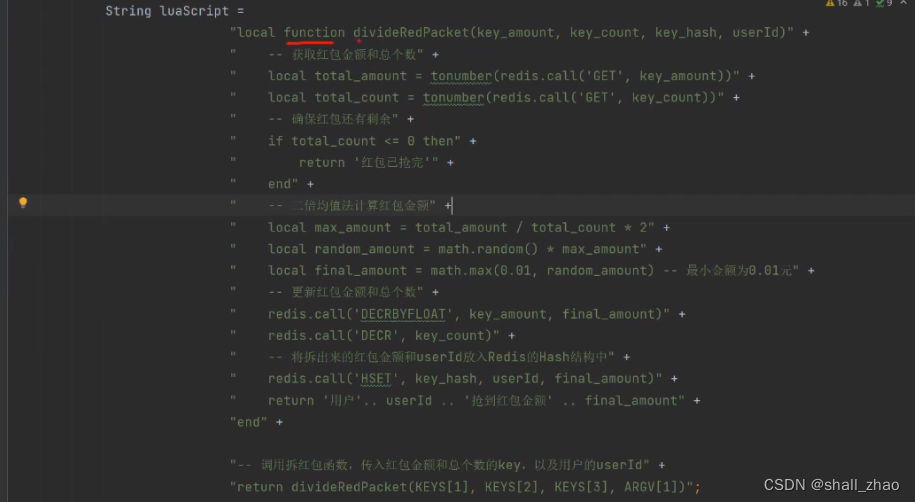
6、二倍均值算法实现微信拆红包:lua脚本
使用二倍均值算法实现微信拆红包

五、用户系统设计
登录、注册、联系人、添加好友、管理好友、群组、标签等功能……
1、联系人表结构设计
1、用户表(ID、昵称、手机号、状态、密码信息……等基础信息)
2、好友表(好友关系ID、用户ID1、用户ID2、状态),用来关联两个用户关系
3、分组表(分组ID、分组名称、分组所属用户ID、)
4、好友-分组关联表(关联表ID、分组ID、我的好友ID)
好友关系,可以考虑使用图数据库,或者使用双向的K->List结构存储。
用户 X 订阅了 Y 和 Z,那么在 “订阅关系” 中,Key 是 X,List 中元素包括 Y 和 Z;用户 Y 订阅了 Z,那么在 “订阅关系” 中,Key 是 Y,List 中元素包括 Z。
在 “被订阅关系” 中,Y 被 X订阅,则 Key 是 Y,List 中元素包括 X; Z 被 X 和 Y 订阅,则 Key 是 Z,List 中元素包括 X 和 Y。
2、消息表结构设计
1、消息表(消息ID、发送者ID、接受者ID、消息类型-文本图片音频视频、消息内容、时间……)
3、消息传递
文本视频图片音频等消息,通过服务器中转,可以有效解决用户不在线可以接收到消息。
(中心化的消息传输,可以有其他功能比如消息回执、已读标记、消息多端同步)
(服务器压力较大,用户隐私问题取决于服务器的处理)
消息的状态:未发送、已发送、发送成功。
消息发送成功后,为了保护用户隐私,可以将这条消息在服务器删除。

4、对讲机:点对点还是通过服务器?
答案:通过服务器中转。
点对点无法做到群发。
5、每次登录后数据同步方案
方案一:
客户端发送快照到服务端,服务端校验快照与当前用户等数据,将差异信息发给客户端,实现客户端的同步。
缺点:客户越多快照越大,每次都要计算服务器压力较大。
方案二:
根据时间戳/版本号进行同步,对数据做好顺序标记。不需要每次都同步,校验版本号之间的差异即可。
缺点:服务器要存储所有的版本?不需要吧,只需要存储最终版本即可。
六、跨国、多数据中心方案
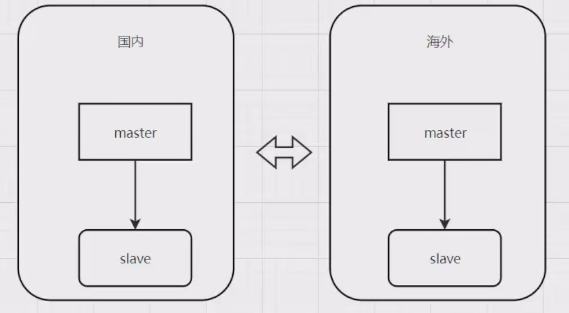
1、pnuts数据同步方案
弱一致性解决方案:pnuts方案:
对用户进行切分(按照地理位置切分)
每个用户写在自己归属的数据中心(主从模式),多master之间数据异步同步。
2、用户只访问自己数据中心方案
判断用户是访问自己的数据,还是需要跨数据中心访问别人的数据。
判断用户是否发生了漫游,需要判断访问哪个数据中心。
用户访问自己的数据,永远会访问到自己所在的数据中心。
但是用户访问别人的头像、朋友圈等信息,对数据一致性要求不高的话(大部分),可以等数据同步到自己的数据中心后就会查到。
如果对数据一致性要求较高,比如说改一个微信号,可以业务上加一个审核功能,或者提供一个唯一的微信号申请服务来做唯一性。
数据同步是一定要做的!为了数据安全、多副本,也不能保证用户一辈子不会出国
3、两个数据中心之间数据的同步
两个目标:准、快。
最朴素的方法:顺序、异步。
4、两地三中心
两地:距离很远的两地,不会特大灾难同时发生的两地。
三中心:生产中心、灾备中心、备份中心。
5、异地多活
(1)三种方案
同城异区:部署在同一个城市的不同机房。
可以享受到高速网络,可以实现负载均衡。
可以解决单机房断电等90%常见问题。
但是无法解决城市规模地震、海啸等极端天气与自然灾害。
跨城异地:部署在不同城市,距离较远。
可以避免城市级规模地震海啸等极端天气与自然灾害。
网络延迟较大,数据不能实时一致。
跨国异地:部署在不同国家不同机房。
网络延迟更高。
政策有限制。
常用于跨国用户,或者只读业务。
(2)设计
设计角度:
1、保证核心业务异地多活。
2、保证核心数据的最终一致性,设置中间状态(支付中等)。
3、允许多种手段同步数据(同步、异步、二次读取-如果数据没有就从多个数据中心都查询一遍,防止没同步完,重新生成-如果session登录失败重新登录)。
4、保证绝大部分用户的可用。
5、如果从技术上无法解决,就从业务入手。
设计步骤:
1、业务分级(按访问量、业务使用、收益)
2、数据分类(按数据量、数据是否唯一、实时性、可丢失性、可恢复性)
3、数据同步(主从同步、消息队列同步)
4、异常处理(多通道同步-主从+消息队列多种方式多种网络同步、同步和访问相结合-读取的时候顺便同步-被动同步、补偿机制)
6、三园区容灾
1、同时提供服务(可以保证流量切换时的顺利、资源闲置的问题)
2、数据要强一致。(比如mysql1主2从,redis集群主从)
3、故障自动切换。(故障识别-通过故障阈值比如连续三次失败、故障切换-转发、故障恢复-比如连续三次成功就恢复)
4、容灾效果持续检验。(时不时进行故障演习)
七、朋友圈系统设计
1、小王发了一个朋友圈发生了什么
1、小王上传图片和内容:直接上传CDN,实际小王手机只存储图片和内容的URL
把服务端的压力交给客户端。
2、小王点击发布之后,服务器的发布列表存储发布ID、URL、小王的ID,
同时,小王的发布列表存储ID、发布ID
发布ID相当于一个指针,指向URL内容。
3、触发批处理动作,小王所有的好友的收件箱都会存储发布ID,并且小王的收件箱也会存储一份,这就相当于写扩散。
如果设置了可见范围,就只针对可见范围进行投递。
(微信慢5000好友会自动关闭朋友圈功能)
2、小李刷朋友圈发生了什么
1、小李刷到自己的收件箱,根据时间顺序获取到最新的发布ID。
2、根据发布ID查到URL,然后从CDN获取到内容。就可以看到朋友圈的内容了。


















 1174
1174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











