







内容提要
到现在监督式学习已经基本上学完了,这篇博客主要想写的是一些关于机器学习的理论,即什么时候用什么学习算法,什么样的学习算法有什么样的特点或者优点。在拟合的时候应该怎么选取拟合模型实际上是在欠拟合和过拟合之间做着权衡,我们训练集大小为多大时合适,最终得到的拟合函数效果怎么样,它的效果如何评价等等,下面我们主要介绍的经验风险最小理论,就是来回答这些问题。
经验风险最小
为了说明经验风险最小,我们首先介绍两个定理:
- (The union bound)假设 A1,A2...Ak 是 k 个不同的事件,那么
P(A1∪A2∪...∪Ak)≤P(A1)+P(A2)+...+P(Ak) 。你可以画一个文氏图去理解他。- (Hoeffding inequality)假设 Z1,Z2...Zm 是 m 个独立同分布(iid)服从伯努利分布的变量,参数为
ϕ 。即 p(Zi=1)=ϕ,p(Zi=0)=1−ϕ ,令 ϕ^=(1/m)∑mi=1Zi , ϕ^ 也是随机变量,对于任意的 γ>0 ,则有 P(|ϕ−ϕ^|>γ)≤2exp(−2γ2m)
Hoeffding inequality说明了伯努利分布参数的估计值与真值之间的误差是有上限的,并且可以看出随着 m 的增大,这个上限会越来越小,也就是说估计值越来越接近真值。
我们还是利用二维分类问题来说明这个理论,
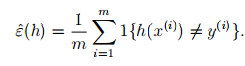
其实这个式子描述就是分类出错的比例,其中,1{.}指示器函数,即 1{true}=1;1{false}=0, y∈{0,1},m 是训练集的大小,即训练样本的个数。
同样的我们也定义一般误差(generalization error):
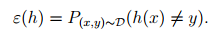
这个误差是我们理论上计算出来的误差,一般的在统计中带有“ ^ ”表示的估计量,估计的意思就是我们通过样本来计算这个变量的值。反之,一般理论值就不带“ ^ ”。
我们之前介绍过线性分类函数的一般形式, hθ(x)=θTx ,下载我们假设这样一个集合:
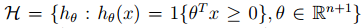
称为:假设集合(hypothesis class)。这是一个分类函数集合,因为 θ 的不同使得各个元素不同,分类函数可能是局部回归得到,逻辑回归得到的等等,总之可以解决我们当前问题的我们可以得到的分类函数。那么我们就像找出那个使得训练误差最小的 θ 作为我们分类函数的参数。
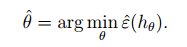
我们将这个过程称为:经验风险最小(empirical risk minimization (ERM))。和这个式子同样的道理我们可以得到训练情况下最优的分类函数。
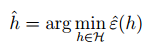
下面我们就依照假设集合 H 有限还是无限两方面进行讨论
H集合有限的情况
设假设集合中总共有
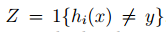
我们研究的问题 (x,y)∼D,hi∈H ,则 Z 就是独立同分布变量。下来就可以将训练误差表示成:
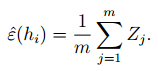
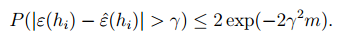
这个式子表明随着训练样本个数 m 的增大,训练误差是逐渐接近理论误差的。我们又令
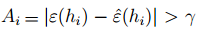
则:
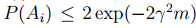
结合union bound进一步我们可以做出如下的推导:
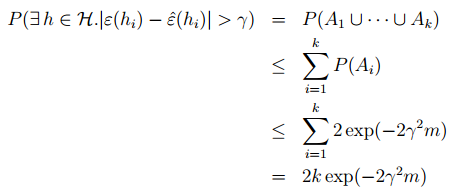
利用基本的概率只是我们又可以得到下面的式子:
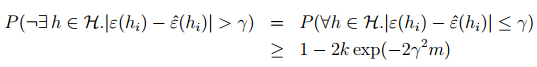
从这个式子可以看出理论误差和训练误差是有一个上界的。这一我们在这讨论的一个原因,我们想知道这个上界。除此之外,我们还想知道后面的这个概率是多少。我们前面说了,随着训练集大小
在给定
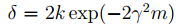
可以得到,当
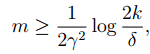
可以保证对于任意的 hi∈H,|ε(hi)−ε^(hi)|≤γ 的概率下界是 1−δ 。在这里可以看出,训练集 m 的大小影响着算法的有效性,所以我们也将他称之为算法的样本复杂度。
同样的在给定
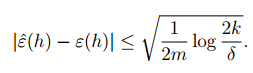
其中
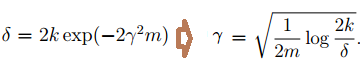
下来我们在定义:
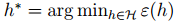
h∗ 是 H 中最合理的假设函数,那么我们可以得到下面的推导:
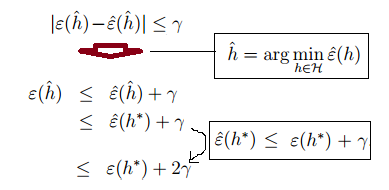
经过上面的这些证明,我们可以得到这样一个定理:当
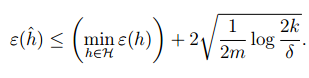
推论: |H|=k,∀m,δ 时,为了
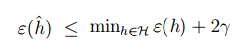
则:
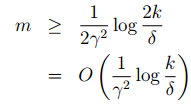
H集合无线的情况
首先我们来介绍分散的概念:给定一个集合 S={x(i),...,x(d)} ,如果假设集H中存在 hi 可以将S中的所有点按标签分开( {y(1),...,y(d)} ),我们就说H可以分散S
VC维(Vapnik-Chervonenkis dimension):给定一个假设集合H,这个H可以分散集合S的最大个数为VC维,记为 VC(H)=d ,如果H可以将任意的S分散,我们就说这个H的VC为无穷大,记为 VC(H)=∞
举一个简单的例子:假如S中有3个点,给定一个线性分类函数的假设集合, y∈{0,1} ,我们总是可以找到一条直线将正负标签的点分隔开来。如下图:
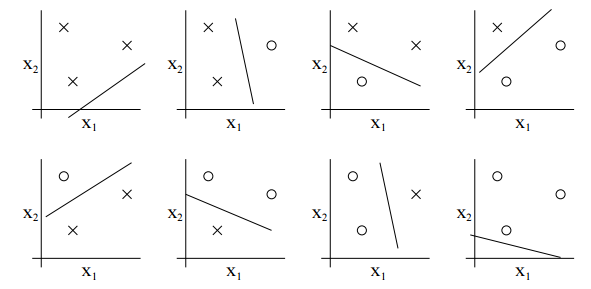
需要说明的是,这是一种存在性的计算。意思就是只要这三个点给定一个排列方式,然后取遍所有标签的情况,我们都可以在这个假设集合H中找到 hi 将他们完美的分隔开来。只要存在这么一种情况,并且再增加一个点这个结论就不成立了。比如这个例子中,当点增加至4个时,就不满足上面的情况(你随便画画,就可以看到当这个点根据y的不同进行重组时,是无法用一条直线将他们分开的)。所以说线性假设集的VC维维3
下面再来看一个定理,这是数学家证明的,过程比较复杂,所以我们只看结论。
给定一个假设集H,并且VC(H) = d,在至少满足
1−δ
这个概率的情况下,我们可以在H中找到一个h满足下面这个不等式:
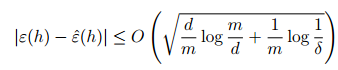
和前面一样我们可以得到下面这个不等式:
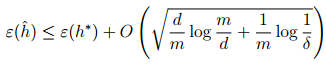
从这个式子可以看出来,当VC维是有限的情况下,当m趋于无穷大的时候,训练误差是收敛的。我们也可以得到如下的推论:
对于H中的所有h,
|ε(h)−ε^(h)|≤γ
至少以
1−δ
的概率成立,所以
m=Oγ,δ(d)
这个式子中的
O
的下标表示
end
















 445
445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









