







更新:非常抱歉,经过交流讨论,发现一处我的代码错误,Merge 模型中最前面应该加上对应的 SFCN,我写了 SFCN 但是却没加入到 Merge 模型中。
更新:我自己用 tf 实现的 SPLERGE 代码已开源在 github 和 gitee,因为数据很少,模型效果是 over-fitting 的,仅供学习。
SPLERGE
之前已经简单介绍过 SPLERGE 和其第一个阶段 split 阶段,在此很多东西不再赘述,本篇主要讲解 SPLERGE 中的第二个阶段 merge 阶段。
整体还是那几个方面,数据准备、模型搭建、模型训练和模型评估。因为我整体战线拉得比较长,split 早先是单独先做的,所以到 merge 阶段部分有些东西比如数据准备和训练等,就没完全再去当时 split 里面适应两个阶段,而是直接新建 merge 专用的,说是专用也是有些参数一致,有些参数需要单独改。
数据准备
在准备数据前要先弄清楚 merge 的输入到底是什么,还有就是训练 merge 还需要的 label 信息哪里来。论文在 merge 阶段并没有再画出来模块或者 merge 部分的模型结构,基本是靠语言描述的。按照我的理解,merge 是以原始图片信息 + split 的结果 + split 结果的衍生综合起来为输入的。这也注定了 merge 阶段的 label 是随着 split 结果变化而变化的。如果使用的 split 模型不一样,分隔效果不一样,merge 阶段的输入和 label 都会不一样。
如果训练 merge 阶段时,只使用唯一一个 split 模型,那么理论上也可以把 merge 阶段的训练数据全写一份存起来,每次去读就好了,对应的 label 也就计算一遍,然后存起来再读就好了。但是为了能在训练过程中随意更换 split 模型,我并没有存储信息,而是每次都重新计算。
回到开头的问题,输入是什么?合起来有 8 通道的输入,分别是 3 通道原始图片信息 + 1 通道 split 预测的行分隔扩展到二维 + 1 通道 split 预测的列分隔扩展到二维 + 1 通道行分隔图割后扩展到二维 + 1 通道列分隔图割后扩展到二维 + 1 通道字符位置信息。
继续回答,label 是什么?原论文有讲解,比如 split 的结果是 M 行 N 列,这样就有行列线划分出来的 M × N 个格子,那么 label 信息就应该是每个格子是否要向下或者向右合并,合并的原则通俗一点就是有没有“压线”。如果把所有的文字块画成一个与原图宽高大小一致的 mask,以格子 (i, j) 是否需要向右合并也就是和格子(i, j + 1) 合并,就得看这两个格子中间那条竖线段是否在那个位置“压”到了 mask 这个位置的文字块,如果压到了就合并,如果没有那就不合并。
这样看来输入部分并不需要增改 tfrecords 中的信息,但是 label 部分需要有一个字块的 mask。所以与 split 不同的部分,就是加了个 mask 的图。
还有一点很重要的是,样本占比。应该保证需要 merge 的情况较多地出现,不然在训练 merge 时会出现正负样本偏差过大的情况。(虽然但是,我也没太多数据,/(ㄒoㄒ)/~~)
模型搭建
有关 merge 部分的模型,原文主要靠文字表述,没有直接画图讲解。不过整体来看,一共有 4 个分支用来预测每个格子向上下左右四个方向 merge 的概率,每个分支包含 3 个 block。这里的 block 和 split 阶段中的 block 很像,到后面也有两个分支,但有一些细微的差异,比如就没有投影池化了,变成了网格池化。最前面也算是一个 SFCN,只不过也和 split 不太一样,略有不同。
# SFCN
class SFCN(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(filters=18, kernel_size=7, padding='same', activation='relu')
self.conv2 = tf.keras.layers.Conv2D(filters=18, kernel_size=7, padding='same', activation='relu')
self.avg_pool1 = tf.keras.layers.AvgPool2D(pool_size=(2, 2), padding='same')
self.conv3 = tf.keras.layers.Conv2D(filters=18, kernel_size=7, padding='same', activation='relu')
self.conv4 = tf.keras.layers.Conv2D(filters=18, kernel_size=7, padding='same', activation='relu')
self.avg_pool2 = tf.keras.layers.AvgPool2D(pool_size=(2, 2), padding='same')
@tf.function
def call(self, input):
c1 = self.conv1(input)
c2 = self.conv2(c1)
c2_pool = self.avg_pool1(c2)
c3 = self.conv3(c2_pool)
c4 = self.conv4(c3)
c4_pool = self.avg_pool2(c4)
return c4_pool
# Block
class Block(tf.keras.Model):
def __init__(self, block_num, mode=None):
super().__init__()
self.block_num = block_num # start from index 1
self.mode = mode
self.conv1 = tf.keras.layers.Conv2D(filters=6, kernel_size=3, padding='same', activation='relu')
self.conv2 = tf.keras.layers.Conv2D(filters=6, kernel_size=3, padding='same', activation='relu', dilation_rate=2)
self.conv3 = tf.keras.layers.Conv2D(filters=6, kernel_size=3, padding='same', activation='relu', dilation_rate=3)
self.branch1 = tf.keras.layers.Conv2D(filters=18, kernel_size=1, padding='same', activation='relu')
self.branch2 = tf.keras.layers.Conv2D(filters=1, kernel_size=1, padding='same')
return
# @tf.function
def call(self, input, grid_loc):
c1 = self.conv1(input)
c2 = self.conv2(input)
c3 = self.conv3(input)
c = tf.concat([c1, c2, c3], axis=3)
branch1 = self.branch1(c)
branch1 = grid_pool(branch1, grid_loc)
branch2 = self.branch2(c)
branch2 = grid_pool(branch2, grid_loc)
branch2 = tf.keras.activations.sigmoid(branch2)
# 这里为了得到 M×N 需要对 branch 取平均?
output = tf.concat([branch1, c, branch2], axis=3)
return output, branch2
# Grid pool
def grid_pool(inputs, structure):
# structure 包含网格信息就可以 用什么形式呢? 列表吧,两个列表
b, h, w, c = inputs.shape
row_loc, col_loc = structure
M, N = len(row_loc) - 1, len(col_loc) - 1 # M 行 N 列
for _b in range(b):
whole = []
for _idxr in range(M):
hori = []
for _idxc in range(N):
y0, y1 = row_loc[_idxr], row_loc[_idxr + 1]
x0, x1 = col_loc[_idxc], col_loc[_idxc + 1]
temp_mean = tf.reduce_mean(inputs[:, y0: y1, x0: x1, :], axis=1, keepdims=True)
temp_mean = tf.reduce_mean(temp_mean, axis=2, keepdims=True)
temp_mean = tf.image.resize(temp_mean, (y1 - y0, x1 - x0))
hori.append(temp_mean)
hori = tf.concat(hori, axis=2)
whole.append(hori)
whole = tf.concat(whole, axis=1)
return whole
def grid_pool_downsize(inputs, structure):
b, h, w, c = inputs.shape
row_loc, col_loc = structure
M, N = len(row_loc) - 1, len(col_loc) - 1 # M 行 N 列
for _b in range(b):
whole = []
for _idxr in range(M):
hori = []
for _idxc in range(N):
y0, y1 = row_loc[_idxr], row_loc[_idxr + 1]
x0, x1 = col_loc[_idxc], col_loc[_idxc + 1]
temp_mean = tf.reduce_mean(inputs[:, y0: y1, x0: x1, :], axis=1, keepdims=True)
temp_mean = tf.reduce_mean(temp_mean, axis=2, keepdims=True)
hori.append(temp_mean)
hori = tf.concat(hori, axis=2)
whole.append(hori)
whole = tf.concat(whole, axis=1)
return whole
# Branch
class Branch(tf.keras.Model):
def __init__(self):
super().__init__()
self.Block1 = Block(1)
self.Block2 = Block(2)
self.Block3 = Block(3)
return
def call(self, input, grid_loc):
op1, br1 = self.Block1(input, grid_loc)
op2, br2 = self.Block2(op1, grid_loc)
op3, br3 = self.Block3(op2, grid_loc)
br2 = grid_pool_downsize(br2, grid_loc)
br3 = grid_pool_downsize(br3, grid_loc)
return br2, br3
# Merge
class Merge(tf.keras.Model):
def __init__(self):
super().__init__()
self.branch_u = Branch()
self.branch_d = Branch()
self.branch_l = Branch()
self.branch_r = Branch()
return
def call(self, input, grid_loc):
# 每一个 都是 M × N 矩阵
matrix_u2, matrix_u3 = self.branch_u(input, grid_loc)
matrix_d2, matrix_d3 = self.branch_d(input, grid_loc)
matrix_l2, matrix_l3 = self.branch_l(input, grid_loc)
matrix_r2, matrix_r3 = self.branch_r(input, grid_loc)
return matrix_u2, matrix_u3, matrix_d2, matrix_d3, matrix_l2, matrix_l3, matrix_r2, matrix_r3
模型训练
(1)学习率和 split 阶段一样,batchsize 不再赘述还是 1。
(2)训练速度慢多了,前面也说了,我是在训练过程中随时计算的 merge input 和 label。差不多 4~5 分钟训练一轮。
loss 主干代码:
def loss_merge(inputs, grid_loc, mask_char, merge, loss_fn=tf.keras.losses.binary_crossentropy):
b, h, w, c = inputs.shape
M, N = len(grid_loc[0]) - 1, len(grid_loc[1]) - 1
if M <= 1 or N <= 1:
return False, 0, 0, 0
matrix_u2, matrix_u3, matrix_d2, matrix_d3, matrix_l2, matrix_l3, matrix_r2, matrix_r3 = merge(inputs, grid_loc)
D2 = cal_D(matrix_u2, matrix_d2)
D3 = cal_D(matrix_u3, matrix_d3)
R2 = cal_R(matrix_l2, matrix_r2)
R3 = cal_R(matrix_l3, matrix_r3)
mask_char = np.reshape(np.frombuffer(mask_char[0].numpy(), dtype=np.uint8), (h, w))
label_D, label_R = gen_merge_label(mask_char, grid_loc)
accD, accR = cal_merge_acc(label_D, label_R, D3, R3)
loss_merge_d = tf.reduce_sum([tf.multiply(0.25, loss_fn(label_D, D2)), loss_fn(label_D, D3)]) # reduce_sum
loss_merge_r = tf.reduce_sum([tf.multiply(0.25, loss_fn(label_R, R2)), loss_fn(label_R, R3)])
loss_merge_total = tf.add(loss_merge_d, loss_merge_r)
return True, loss_merge_total, accD, accR
def cal_D(matrix_u, matrix_d):
# input: M * N; output: M-1 * N
D = tf.add(tf.multiply(0.5, tf.multiply(matrix_u[0, 1:, :, 0], matrix_d[0, :-1, :, 0])),
tf.multiply(0.25, tf.add(matrix_u[0, 1:, :, 0], matrix_d[0, :-1, :, 0])))
return D
def cal_R(matrix_l, matrix_r):
R = tf.add(tf.multiply(0.5, tf.multiply(matrix_l[0, :, 1:, 0], matrix_r[0, :, :-1, 0])),
tf.multiply(0.25, tf.add(matrix_l[0, :, 1:, 0], matrix_r[0, :, :-1, 0])))
return R
模型评估
2021.06.07 更新
这里早在之前发布时就有评估和实际运行效果的,经提醒发现上面代码和这部分全都没了,我要晕过去了。之前就有一次在线写文档 csdn 显示已保存但实际没保存一长篇都白写了,这次都发布过的竟然还会丢,csdn 坑我。话说今天高考我竟然在补这个,我今天登录是要干别的啊,感觉像作文被撕了要重写,一点心劲儿也没了。/(ㄒoㄒ)/~~
首先这个评估过程本身就有一点自欺欺人的,因为 split 阶段就已经过拟合了,况且 merge 数据更少了。在 split 结果上做 merge 也仅仅是试验了,几乎是不可能达到泛化特别好的效果。所以我就只记录了验证的,没记测试的。
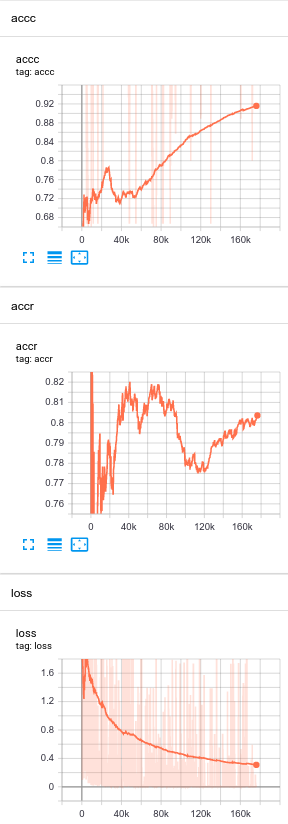
可以看到 merge 训练过程相比 split 长多了,而且整体来看好像列的合并列更“简单”(accc 的值比 accr 的值高),这跟 split 阶段是一致的。考虑到至少数据集中的表格一般都不是特别大,且确实列分隔更明显,而行分隔确实比较密集(行间距比较小)。所以,学习需要 merge 列分隔应该比学习 merge 行分隔要简单一点。就补到这儿了,不想写了/(ㄒoㄒ)/~~
训练过程情况:依次是列合并、行合并以及 merge 的 loss。
实际效果如下:红色横线和黄色竖线是 split 的结果,不是 merge 的。在此 split 结果上,我们可以看到全图需要 merge 的地方很少,纵向有 0 处,横向只有 2 处,在最上面。第 0 行 第 1 列 需要向右 merge;第 0 行 第 3 列需要向右 merge。
下图就是横向 right 需要 merge 的概率信息,可以看到只有前面说过的位置概率是 1 ,其他几乎都是 0。

下图是纵向 down 需要 merge 的概率信息,全为 0。
















 1765
1765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









