










- 表格识别主要分为三个大的部分:文本检测 文本识别 表格结构识别。
- 将表格识别过程进行细分,见下图所示。
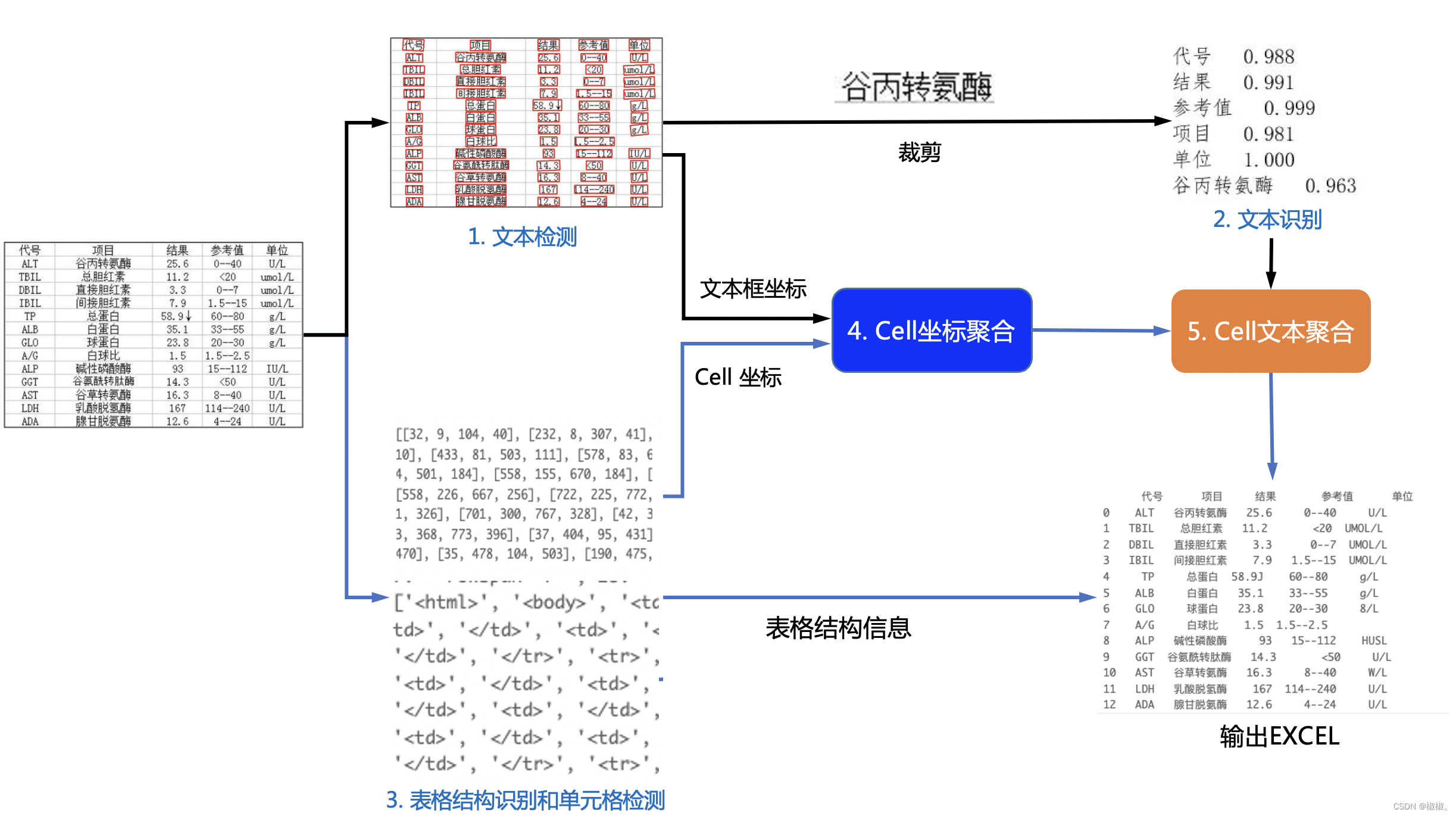
- 在整个表格识别过程中,主要包括三种模型: 文本检测模型:识别出文本的坐标值和文本框。 文本识别模型:识别出文本框中的值(文字)。
表格结构识别模型:识别出表格结构和单元格坐标。
详细的流程如图所示:
1、文本检测:将文本进行预处理成输入结构后,通过文本检测模型识别出文本所在的框和文本框的坐标值。
2、将识别出的文本框结合坐标值从原图中将文本进行裁剪,得到文本识别的输入数据。
3、将数据输入到文本识别模型中识别出单个图像中存在的文本值和文本的坐标值。
4、表格结构识别:表格结构识别,识别出框和单元格线及其框的坐标值。
5、将3中得到的值与4的值进行聚合,进行文本表格还原,将表格单元格位置与文本框位置进行聚合,然后对文本框进行排序,从上到下,从左到右进行排序,然后根据文本坐标位置信息找到文字所在的单元格,然后对单元格内的文字进行拼接,最终得到单元格内的文字信息。
注意:1、其实在这个过程中,文本检测和文本识别这两个阶段就是OCR识别过程。
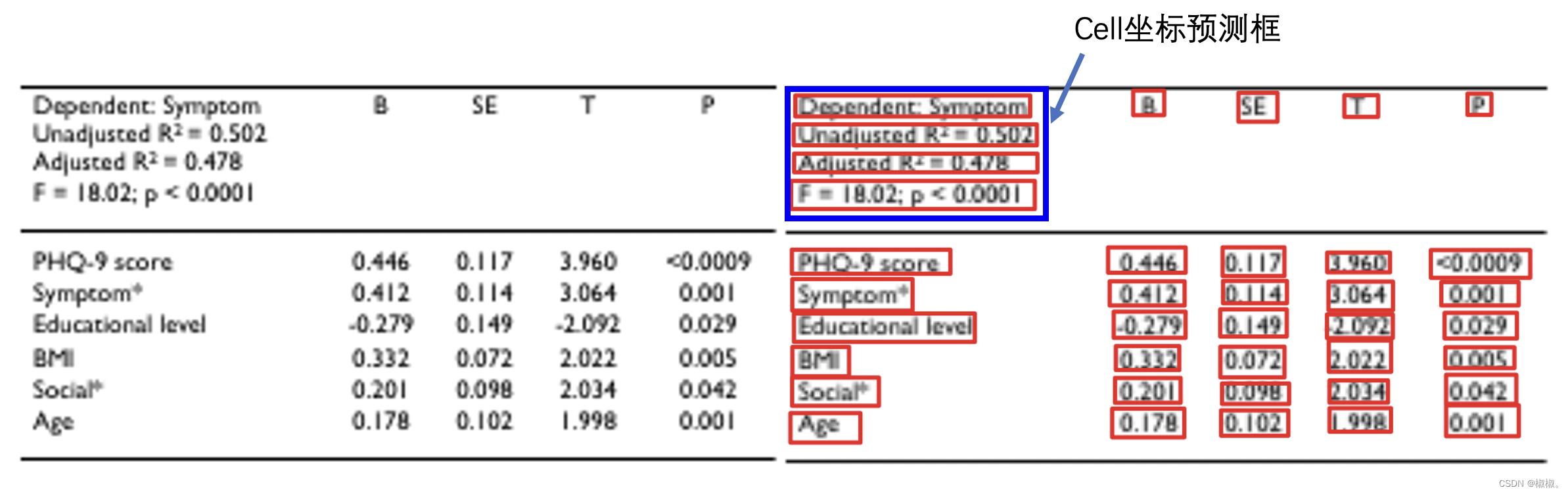
2、如下图所示:进行表格单元格与文本框聚合,通过判断IOU来决定是否要进行聚合。



















 1041
1041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











