







目录
1. Probabilities: Joint to Conditional 概率:从联合到条件
1.1 The Markov Assumption 马尔可夫假设
1.2 Maximum Likelihood Estimation 最大似然估计
1.3 Book-ending Sequences 书籍结尾序列
2.1 Laplacian (Add-one) Smoothing
2.8 Interpolated Kneser-Ney Smoothing
如今,预训练的语言模型是现代NLP系统的骨干
1. Probabilities: Joint to Conditional 概率:从联合到条件
我们的目标是得到一个任意的m个词的序列的概率
![]()
第一步是应用链式规则,将联合概率转换为条件概率
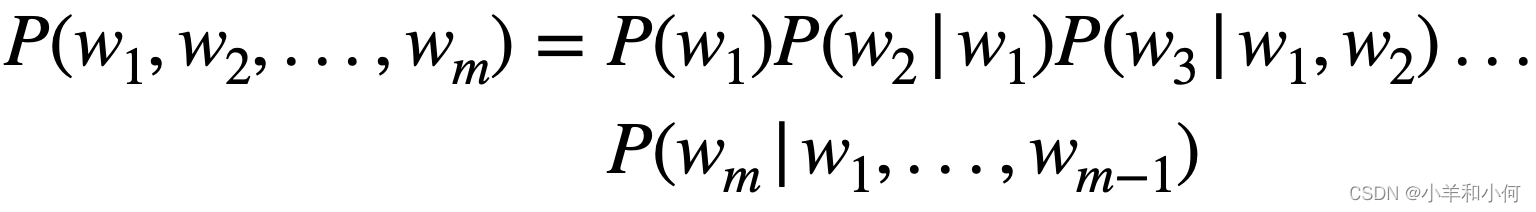
1.1 The Markov Assumption 马尔可夫假设
还是很棘手,所以做一个简单的假设:

1.2 Maximum Likelihood Estimation 最大似然估计
我们如何计算概率?根据语料库中的计数进行估计:
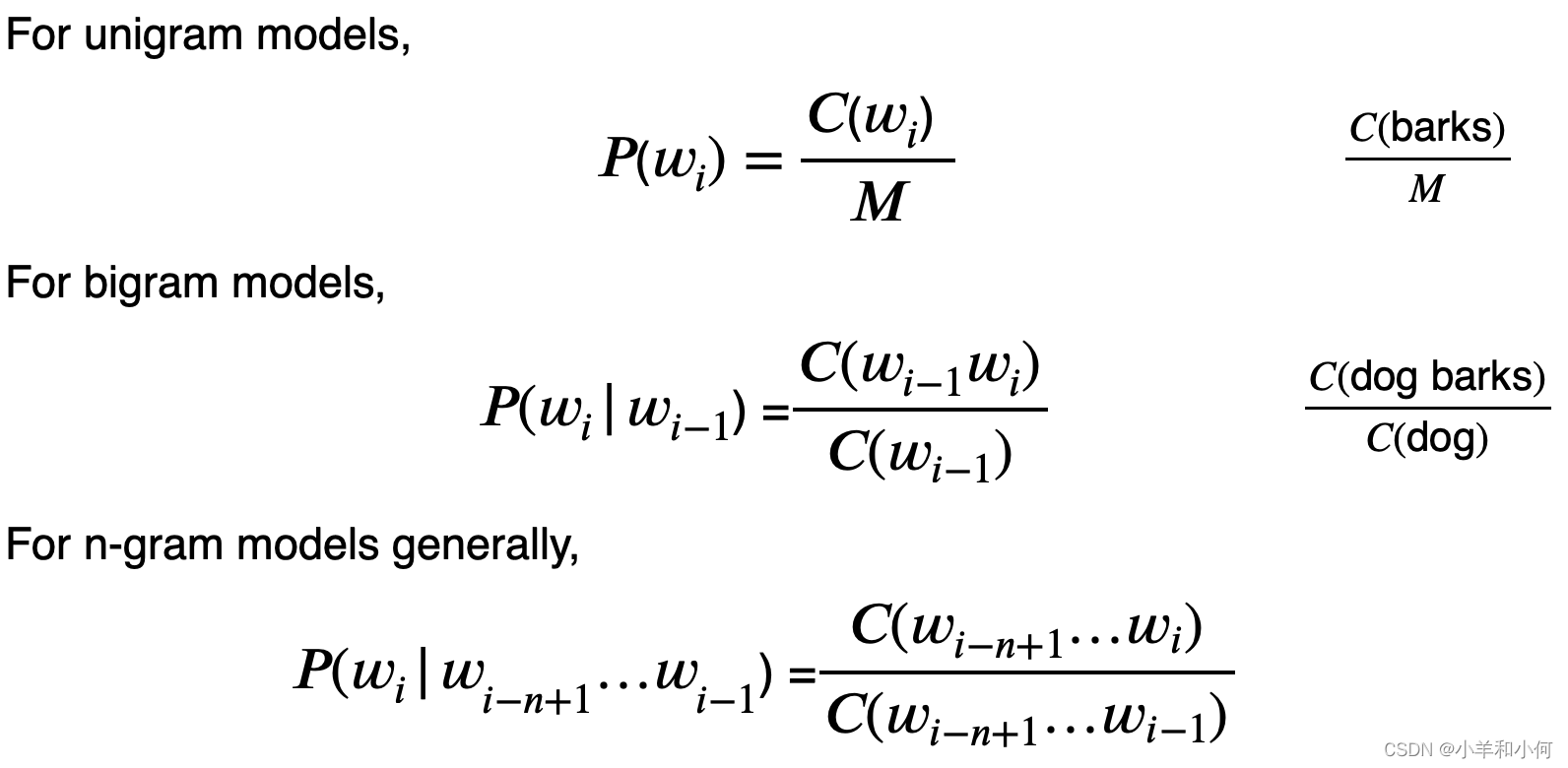
1.3 Book-ending Sequences 书籍结尾序列
用于表示序列的开始和结束的特殊标记
- <s> = sentence start
- </s> = sentence end
1.4 Trigram example




1.5 Several Problems
- 语言具有长距离效应ー 需要大的 n
- 上周的讲座是关于预处理的。
- 由此产生的可能性通常非常小
- 使用对数概率来避免数值底流
- 那看不见的文字呢?
- 表示它们的特殊符号(例如 < UNK >)
- Unseen n-grams?

- 需要平滑 LM!
2. Smoothing
- 基本思路:给出一些你以前从未见过的可能性
- 必须是 P (everything) = 1
- Many different kinds of smoothing
- Laplacian (add-one) smoothing
- Add-k smoothing
- Absolute discounting
- Kneser-Ney
- And others…
2.1 Laplacian (Add-one) Smoothing
简单的想法:假装我们已经看到了每个 n-gram 比我们多一次。


2.2 Add-k Smoothing
- 加一往往是太多了
- 相反,添加一个分数 K
- 又称利德斯通平滑法
- 需要选择一个合适的 K
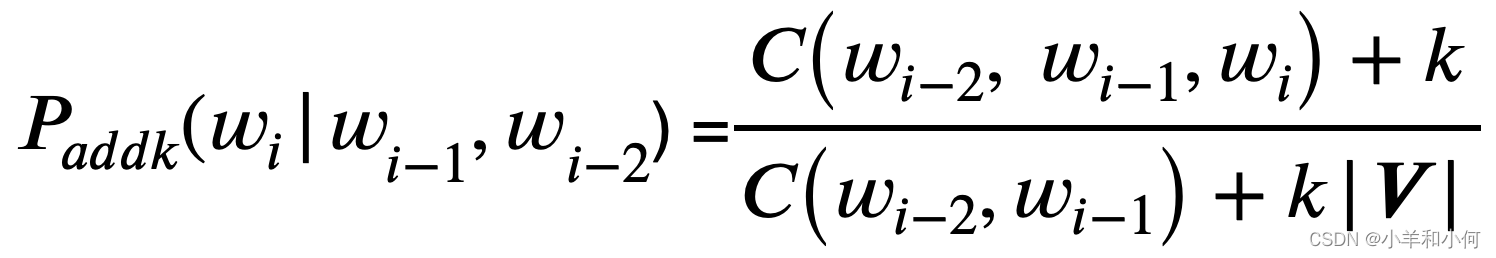
2.3 Lidstone Smoothing

2.4 Absolute Discounting
- 从观察到的 n 克计数中借用一个固定的概率质量
- 将其重新分布为不可见的 n-gram

2.5 Backoff
- 对于所有看不见的 n 克,绝对贴现重新分配概率质量
- Katz Backoff: 基于低阶模型(例如 unigram)重新分配质量


2.6 Kneser-Ney Smoothing
- 根据低阶 n-gram 的通用性重新分配概率质量
- AKA "continuation probability"
- What is versatility?
- 高通用性 -> 与许多独特的单词同时出现 e.g. glasses - men’s glasses, black glasses, buy glasses, etc
- 通用性低 -> 与几个独特的单词同时出现,e.g. francisco - san francisco

- Intuitively the numerator of Pcont counts the number of unique wi-1 that co-occurs with wi
- High continuation counts for glasses
- Low continuation counts for Franciso
2.7 Interpolation
- 一种更好的方法来组合不同顺序的 n-gram 模型
- 越来越短的上下文中概率的加权和
- Interpolated trigram model 内插三元模型:

2.8 Interpolated Kneser-Ney Smoothing
插值代替后退
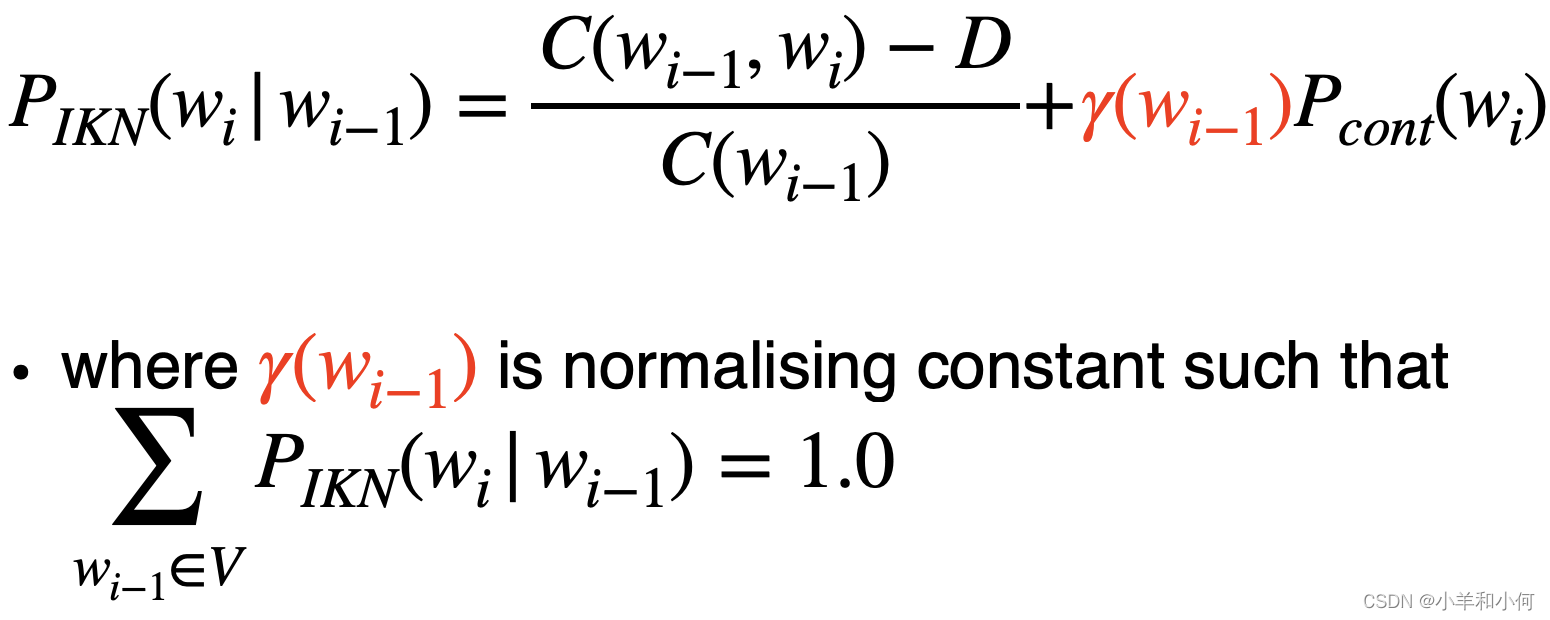
3. Generating Language
3.1 Generation
- 给定一个初始单词,根据语言模型产生的概率分布绘制下一个单词
- 为 n-gram 模型包含 (n-1) <s> 标记,以提供上下文来生成第一个单词
- 永远不要生成 <s>
- 生成 </s> 终止序列
3.2 Generation (Bigram LM)

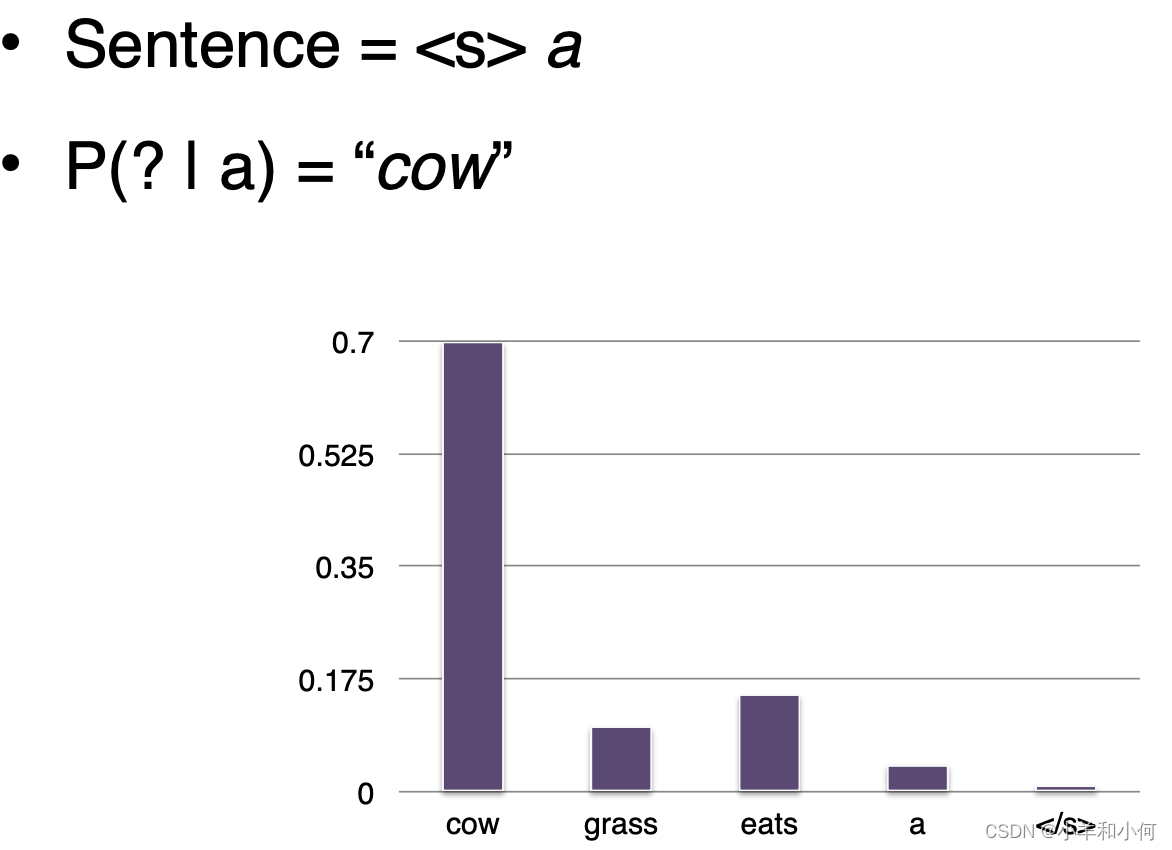




3.3 How to Select Next Word?
- Argmax:每回合获得概率最高的单词
- 贪婪搜索
- 光束搜索解码 :
- 每轮跟踪前 N 个概率最高的单词
- 选择能产生最佳句子概率的单词顺序
- 从分布中随机抽取样本
4. A Final Word
- N-gram 语言模型是一个简单而有效的方法来捕捉语言的可预测性
- 可以在无监督的情况下进行培训,可扩展到大型语料库
- 需要平滑才能有效
- 现代语言模型使用神经网络














 575
575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









