







Python机器学习 学习笔记与实践
环境:win10 + Anaconda Python3.8
该篇总结各类监督学习算法的实践使用方法
朴素贝叶斯分类器
scikit-learn中实现了三种朴素贝叶斯分类器:
GaussianNB、BernoulliNB 和 MultinomialNB。
GaussianNB 可应用于任意连续数据;
BernoulliNB 假定输入数据为二分类数据;
MultinomialNB 假定输入数据为计数数据。
1、BernoulliNB的理解
BernoulliNB 分类器计算每个类别中每个特征不为 0 的元素个数。下面通过一个小例子理解:
import numpy as np
X=np.array([[0,1,0,1],[1,0,1,1],[0,0,0,1],[1,0,1,0]])
y=np.array([0,1,0,1])
# 对每个类别进行遍历
# 计算(求和)每个特征中1的个数
counts = {}
for label in np.unique(y):
counts[label] = X[y == label].sum(axis=0)
print("Feature counts:\n{}".format(counts))
运行结果:

也就是说,类别为0的元素中,第一个特征不为0的元素有0个,第二个特征不为0的元素有1个…以此类推。
2、练习使用GaussianNB分类器:
from sklearn.naive_bayes import GaussianNB
import mglearn
import numpy as np
import matplotlib.pyplot as plt
#观察数据
X, y = mglearn.datasets.make_forge()
print('The shape of X is : {}'.format(X.shape))
print('The shape of y is : {}'.format(y.shape))
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
plt.show()
#训练模型,并给出预测的分类
cli = GaussianNB()
cli.fit(X,y)
test=np.array([[[8,0],[8,6],[11,1],[11,5]]])
for sample in test:
print(cli.predict(sample))
本例使用的数据集如下所示,每个样本有两个特征,一个为横坐标,另一个为纵坐标:
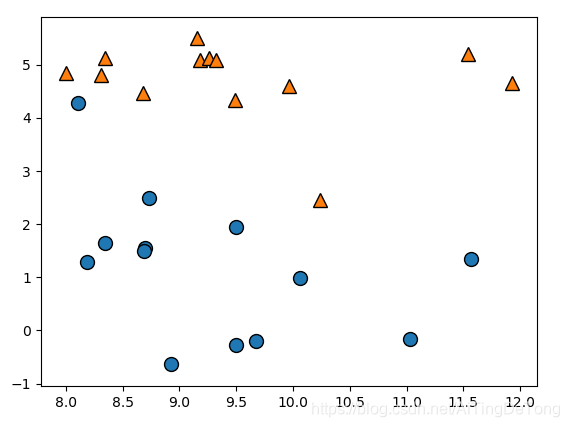
运行结果:

可见,在代码中我们使用[8,0],[8,6],[11,1],[11,5]四条样本数据进行测试,在图中分别位于左下、左上、右下、右上,从预测结果看到,模型分类正确。















 127
127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









