







本文用CUDA实现两矩阵相乘。下图为C=A*B的直观解释,C的每个元素为A对应行向量与B对应列向量的点积。可见,为了计算元素C(i,j),需要访问全局内存A.width + B.height次。为了提升计算效率,矩阵乘法还可以用共享内存实现。首先按照Block大小将A,B,C拆分成子矩阵形式,那么C中一个Block内的所有Thread可以同步访问A,B对应的子区域(从全局内存拷贝到共享内存,共享内存设置成Block区域大小),然后进行子区域的乘积计算。实际上利用共享内存可以将全局访问次数降低为A.width/BLOCK_SIZE + B.height/BLOCK_SIZE.
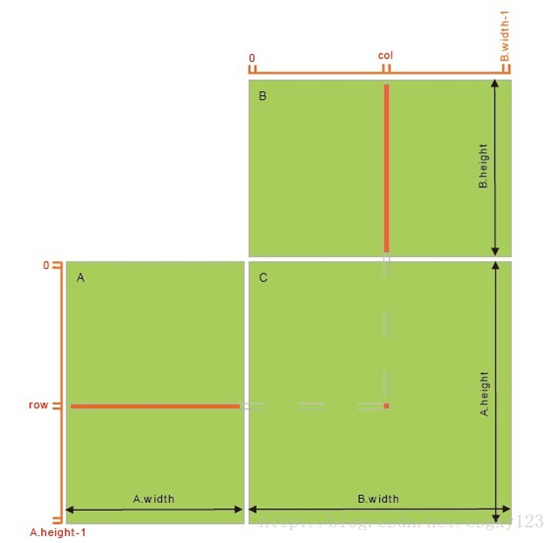
矩阵相乘原理图
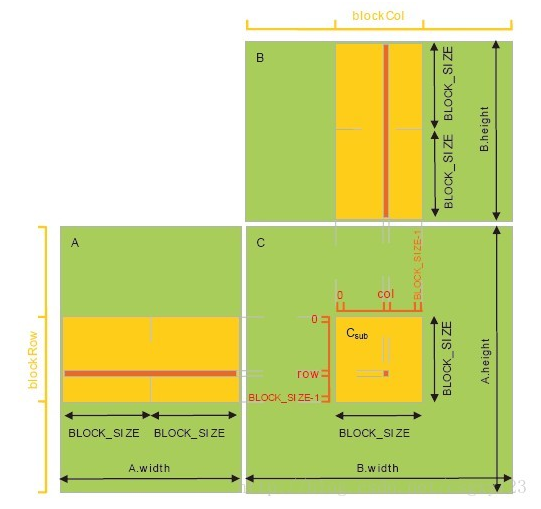
利用共享内存可以提高计算效率
以下Code参照SDK VectorAdd代码示例改下,用来计算两个1024*1024方阵的乘机,并且添加了CPU和GPU计时功能,可以方便对比运算时间。
/**
* 两矩阵(方阵)相乘示例,
使用共享内存 比 不使用共享内存 效率高出一倍
*/
#include <stdio.h>
#include <time.h>
// For the CUDA runtime routines (prefixed with "cuda_")
#include <cuda_runtime.h>
/**
* CUDA Kernel Device code
*
* Computes the matrix multiplication of A and B into C.
* without using shared memory
*/
__global__ void matrixMul_noSharedM(const float *A, const float *B, float *C, int N)
{
int col = blockDim.x * blockIdx.x + threadIdx.x;
int row = blockDim.y * blockIdx.y + threadIdx.y;
if (col < N && row < N)
{
C[row*N + col] = 0;
for (int i=0; i<N; i++)
{
C[row*N + col] += A[row*N + i] * B[i*N + col];
}
}
}
//using shared memory
__global__ void matrixMul_SharedM(const float *A, const float *B, float *C, int N)
{
__shared__ float Mds[32][32];
__shared__ float Nds[32][32];
int col = blockDim.x * blockIdx.x + threadIdx.x;
int row = blockDim.y * blockIdx.y + threadIdx.y;
if (col < N && row < N)
{
float pValue = 0.0;
for (int m=0; m<32; m++)
{
Mds[threadIdx.y][threadIdx.x] = A[row*N + m*32 + threadIdx.x];
Nds[threadIdx.y][threadIdx.x] = B[(threadIdx.y+m*32)*N + col];
__syncthreads(); //同步同一个block的所有thread
for(int k = 0; k < 32; k++)
{
pValue += Mds[threadIdx.y][k] * Nds[k][threadIdx.x];
}
__syncthreads();
}
C[row*N + col] = pValue;
}
}
/**
* Host main routine
*/
int main(void)
{
// Error code to check return values for CUDA calls
cudaError_t err = cudaSuccess;
// Define the squared matrix, and compute its size
int numElements = 32*32;
int size = numElements * numElements * sizeof(float);
int NN = numElements * numElements;
// Allocate the host input vector A
float *h_A = new float[size];//(float *)malloc(size);
// Allocate the host input vector B
float *h_B = new float[size];//(float *)malloc(size);
// Allocate the host output vector C
float *h_C = new float[size];//(float *)malloc(size);
// Verify that allocations succeeded
if (h_A == NULL || h_B == NULL || h_C == NULL)
{
fprintf(stderr, "Failed to allocate host matrix!\n");
exit(EXIT_FAILURE);
}
// Initialize the host input matrix
for (int i = 0; i < NN; i++)
{
h_A[i] = rand()/(float)RAND_MAX * 10.0;
h_B[i] = rand()/(float)RAND_MAX * 10.0;
}
// Allocate the device input matrix A
float *d_A = NULL;
err = cudaMalloc((void **)&d_A, size);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to allocate device matrix A (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Allocate the device input matrix B
float *d_B = NULL;
err = cudaMalloc((void **)&d_B, size);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to allocate device matrix B (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Allocate the device output matrix C
float *d_C = NULL;
err = cudaMalloc((void **)&d_C, size);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to allocate device matrix C (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Copy the host input matrix A and B in host memory to the device input matrix in
// device memory
// printf("Copy input data from the host memory to the CUDA device\n");
err = cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to copy matrix A from host to device (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
err = cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to copy matrix B from host to device (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Launch the Matrix multiplication CUDA Kernel
dim3 dimGrid;
dim3 dimBlock(32, 32);
dimGrid.x = numElements / dimBlock.x ;
dimGrid.y = numElements / dimBlock.y ;
cudaEvent_t start, stop; // measure GPU time
float time;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
//matrixMul_noSharedM<<<dimGrid, dimBlock>>>(d_A, d_B, d_C, numElements);
matrixMul_SharedM<<<dimGrid, dimBlock>>>(d_A, d_B, d_C, numElements);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&time, start, stop); printf("GPU time: %f \n", time);
cudaEventDestroy(start);
cudaEventDestroy(stop);
err = cudaGetLastError();
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to launch vectorAdd kernel (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Copy the device result matrix in device memory to the host result matrix
// in host memory.
// printf("Copy output data from the CUDA device to the host memory\n");
err = cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to copy matrix C from device to host (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Compute the groundtrueth
clock_t start2, finish; // measure CPU time
double duration = 0.0;
start2 = clock();
float* GT_C = new float[NN];
for (int r=0; r<numElements; r++)
{
for (int c=0; c<numElements; c++)
{
GT_C[r*numElements + c] = 0;
for (int i=0; i<numElements; i++)
{
GT_C[r*numElements + c] += h_A[r*numElements + i] * h_B[i*numElements + c];
}
}
}
finish = clock();
duration = (double)(finish - start2); //输出单位ms
printf("CPU time: %f\n", duration);
// Verify that the result vector is correct
for (int i = 0; i < NN; ++i)
{
//printf("%d %f %f\n", i, GT_C[i], h_C[i]);
if (fabs(GT_C[i] - h_C[i]) > 1e-5)
{
fprintf(stderr, "Result verification failed at element %d!\n", i);
exit(EXIT_FAILURE);
}
}
printf("Test PASSED\n");
// Free device global memory
err = cudaFree(d_A);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to free device matrix A (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
err = cudaFree(d_B);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to free device matrix B (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
err = cudaFree(d_C);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to free device matrix C (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Free host memory
delete []h_A;
delete []h_B;
delete []h_C;
// Reset the device and exit
err = cudaDeviceReset();
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to deinitialize the device! error=%s\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
printf("Done\n");
return 0;
}
参考:http://blog.csdn.net/csgxy123/article/details/10018531















 1088
1088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









