







识别任务中混淆矩阵(Confusion Matrix)用于评价算法好坏的指标。下图是一个二分类问题的混淆矩阵:
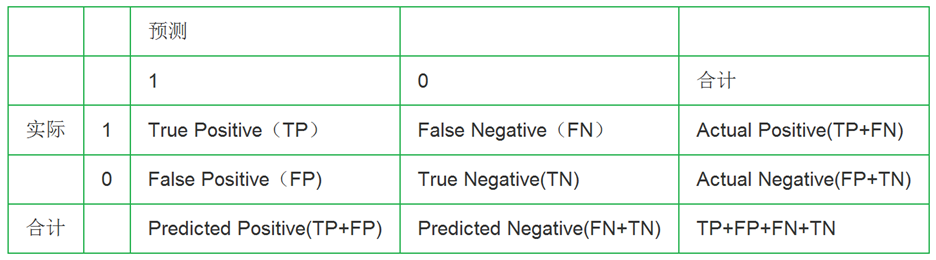
TP:正确肯定——实际是正例,识别为正例
FN:错误否定(漏报)——实际是正例,却识别成了负例
FP:错误肯定(误报)——实际是负例,却识别成了正例
 混淆矩阵是评估分类算法性能的重要工具,包括TP、FN、FP和TN。准确率和误分率是基本评价指标,Recall和Precision关注正样本的识别,ROC曲线通过AUC值评估模型优劣,FAR和FRR则用于衡量误报和拒真率。
混淆矩阵是评估分类算法性能的重要工具,包括TP、FN、FP和TN。准确率和误分率是基本评价指标,Recall和Precision关注正样本的识别,ROC曲线通过AUC值评估模型优劣,FAR和FRR则用于衡量误报和拒真率。
识别任务中混淆矩阵(Confusion Matrix)用于评价算法好坏的指标。下图是一个二分类问题的混淆矩阵:
TP:正确肯定——实际是正例,识别为正例
FN:错误否定(漏报)——实际是正例,却识别成了负例
FP:错误肯定(误报)——实际是负例,却识别成了正例
 282
2116
282
2116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章





















