







CNN来分类CIFAR10图像数据集
在 Tensorflow学习笔记:传统NN和CNN来分类MNIST手写数字数据集,我们研究了如何设计一个简单的Dense神经网络来分类手写数字的图像,然后简单介绍和设计了简单的CNN卷积神经网络结构,也简单说了一下这两个方法的区别。如果想自己练习,可以用tensorflow的keras.datasets.fashion_mnist数据集作分类,和MNIST手写的图像数据集类似。
这篇文章的目的是简单介绍一下卷积神经网络原理,然后和设计一个CNN和来分类CIFAR10图像数据集。
卷积神经网络原理
keras.datasets.mnist和keras.datasets.fashion_mnist两个数据集输入(图像)的维度为2,属于非常简单的数据。 现在我们将要处理通常由 3 个维度组成的图像数据。 这3个维度如下:
- 图像高度
- 图像宽度
- 颜色通道
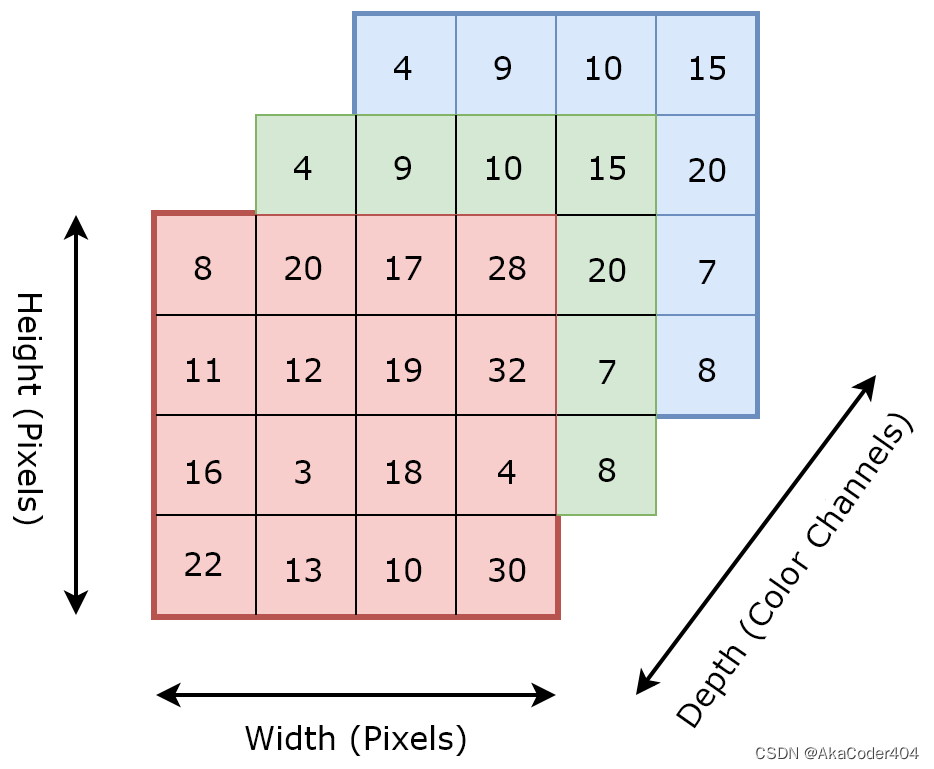
如果你只用过mnist数据集,可能不理解的唯一项目是颜色通道。 颜色通道的数量表示图像的深度,并与其中使用的颜色相关。 例如,具有三个通道的图像可能由 rgb(红、绿、蓝)像素组成。 因此,对于每个像素,我们都有 0-255 范围内的三个数值来定义其颜色。 对于颜色深度为 1 的图像(比如mnist),我们可能会得到一个灰度图像,其中每个像素定义一个值,同样在 0-255 的范围内。
每个卷积神经网络都由一个或多个卷积层(convolutional layers)组成。 这些层与我们之前看到的密集层不同。 他们的目标是从图像中找到可用于对图像或其部分进行分类的模式。 但这对我们在上一节中密集连接的神经网络所做的事情可能听起来很熟悉,那是因为它是。
密集层和卷积层之间的根本区别在于,密集层全局检测模式,而卷积层局部检测模式。 当我们有一个密集连接层时,该层中的每个节点都会看到前一层的所有数据。 这意味着该层正在查看所有信息,并且只能以全局容量分析数据。 然而,我们的卷积层不会密集连接,这意味着它可以使用该层的部分输入数据检测局部模式。
让我们看看密集连接层如何看待图像与卷积层如何。这是我们的形象; 我们网络的目标是确定这张图片是否是一只猫。

密集层:密集层将考虑整个图像。 它将查看所有像素并使用该信息生成一些输出。
卷积层:卷积层将查看图像的特定部分。 在此示例中,假设它分析下面突出显示的部分并在那里检测模式。
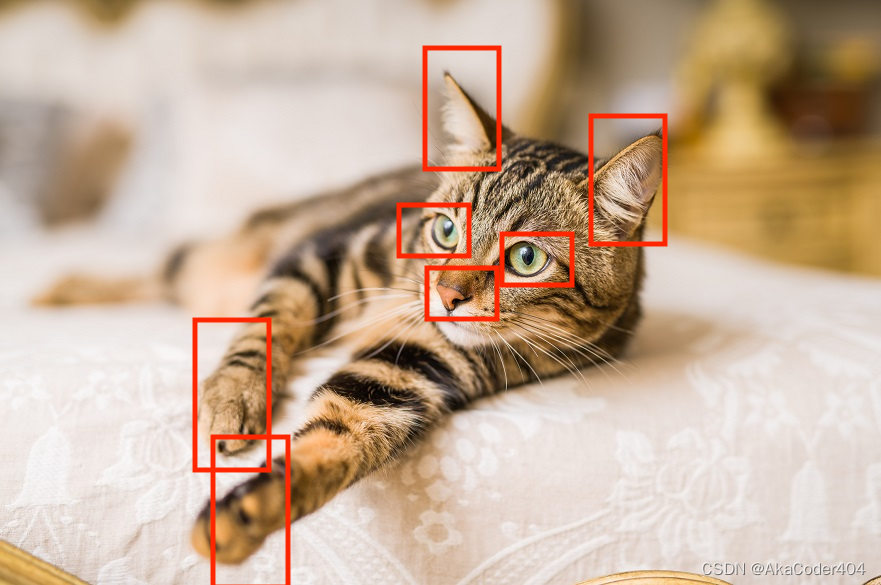
你能明白为什么这会使这些网络更有用吗?
密集的神经网络学习存在于图像的一个特定区域中的模式。这意味着如果网络知道的模式存在于图像的不同区域中,它将必须在该新区域中再次学习该模式才能检测到它。让我们考虑上面的猫的图像。
我们将考虑我们有一个密集的神经网络,它已经从猫图像样本中学习了眼睛的样子。假设如果方框中的位置存在眼睛,则确定图像很可能是猫。然后假设我们翻转图像。
由于我们密集连接的网络仅在全球范围内识别出模式,因此它将查看它认为眼睛应该出现的位置。显然它没有在那里找到它们,因此很可能会确定这张图片不是猫。即使存在眼睛的图案,它只是在不同的位置。
由于卷积层从图像的不同区域学习和检测模式,因此它们与我们刚刚说明的示例没有问题。他们知道眼睛的样子,并通过分析图像的不同部分可以找到它的存在位置。
多个卷积层 Multiple Convolutional Layers
在卷积神经网络模型中,具有多个卷积层是很常见的。 即使我们将基本示例也将由 3 个卷积层组成。 这些层通过增加每个后续层的复杂性和抽象性来协同工作。 第一层可能负责拾取边缘和短线,而第二层将这些线作为输入并开始形成形状或多边形。 最后,最后一层可能会采用这些形状并确定哪些组合构成特定图像。
特征图 Feature Maps
您可能会看到我在本文章中使用术语特征图。 该术语仅代表具有两个空间轴(宽度和高度)和一个深度轴的 3D 张量。 我们的卷积层将特征图作为其输入,并返回一个新的特征图,该特征图表示来自先前特征图的特定过滤器的存在。 这些就是我们所说的响应图。
层的参数
卷积层有两个重要参数
Filters
过滤器是我们在图像中寻找的 m x n 像素模式。 卷积层中的过滤器数量表示每层正在寻找多少模式以及我们的响应图的深度是多少。 如果我们正在寻找 32 种不同的模式/过滤器,那么我们的输出特征图(也称为响应图)的深度将为 32。32 层深度中的每一层都将是一个具有一定大小的矩阵,其中包含指示过滤器是否为 是否出现在那个位置。
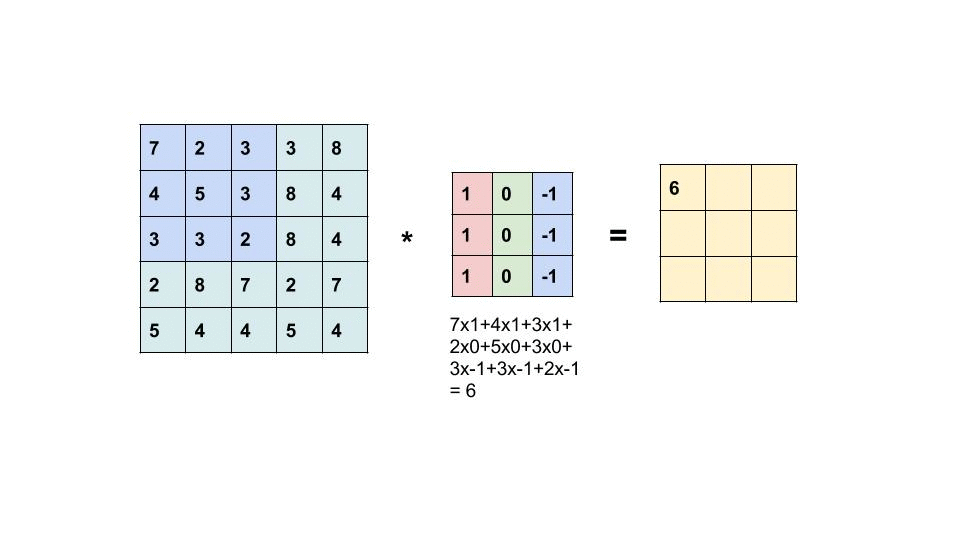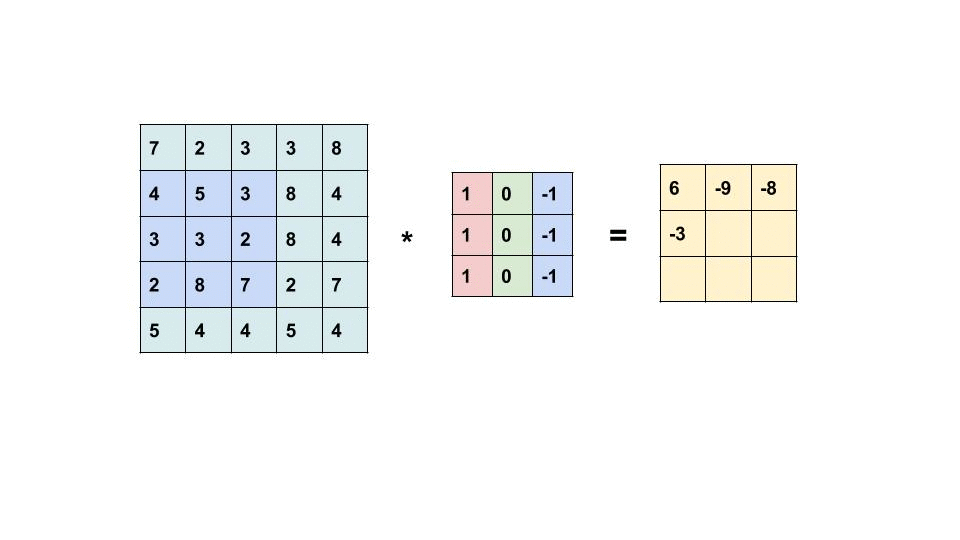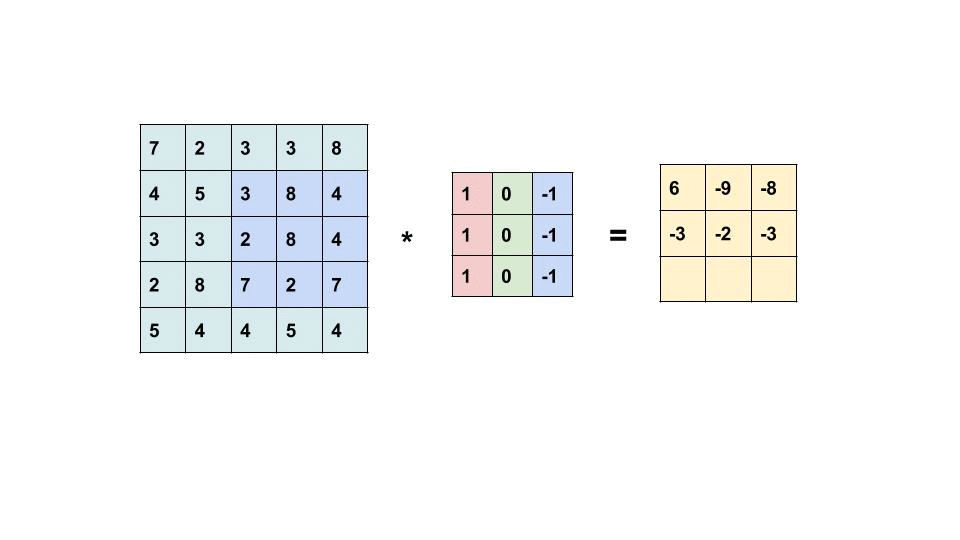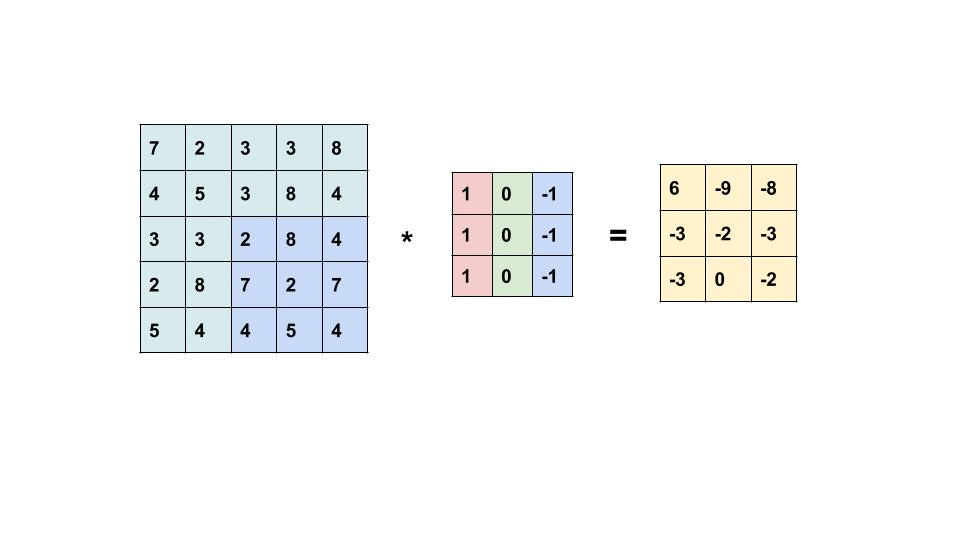
左边的矩阵是你的输入,中间的矩阵是我们的过滤器,右边的矩阵是我们的特征图
样本容量 Sample Size
每个卷积层将检查每个图像中的 n × m n\times m n×m 个像素块。 在上图中,我们使用 3x3 的样本容量。 这个大小将与我们过滤器的大小相同。 我们的层通过在图像中每个可能的位置上滑动这些 n × m n \times m n×
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2556
2556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









