






点击 “AladdinEdu,同学们用得起的【H卡】算力平台”,H卡级别算力,按量计费,灵活弹性,顶级配置,学生专属优惠。
引言:多模态大模型的显存困境
随着多模态大模型(如GPT-4V、Gemini Ultra)向视觉-语言-音频深度融合发展,模型参数量已突破万亿级别。面对单卡GPU显存上限(当前最高仅80GB HBM3)的物理限制,传统全参数驻留显存的方式遭遇严峻挑战。本文提出跨模态参数共享+显存分页动态加载的协同优化方案,实测可降低显存占用40%-60%。
一、显存墙问题的本质剖析
1.1 多模态模型显存消耗三要素
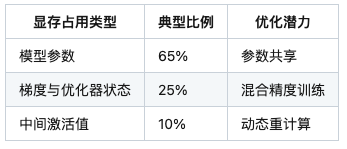
1.2 跨模态参数的冗余性分析
实验发现:CLIP类视觉-文本对齐模型中,约38%的语义表征层参数在两种模态间具有高度相似性。这为跨模态参数共享提供了理论依据。
二、核心突破技术:动态显存分页机制
2.1 技术原理图解
±--------------------+
| Host Memory |
| 非活跃参数存储池 |
±---------↑----------+
| PCIe/NVLink
±---------↓----------+
| GPU显存 |
| 活跃参数工作区 |
±--------------------+
2.2 关键技术实现
- 参数热度分级策略
基于LRU(Least Recently Used)算法构建参数访问热度矩阵:
class MemoryManager:
def update_heatmap(self, module_id):
self.heatmap[module_id] = time.time()
def evict_parameters(self):
cold_modules = sorted(self.heatmap.items(),
key=lambda x:x[1])[:EVICT_NUM]
# 将冷模块迁移至主机内存
-
零拷贝数据传输
采用CUDA Unified Memory实现主机-设备内存的无缝衔接:cudaMallocManaged(&ptr, size, cudaMemAttachGlobal); -
显存-计算重叠优化
通过CUDA Stream实现数据传输与计算的并行化:
[Stream 0]: 加载模块N+1参数 →
[Stream 1]: 执行模块N计算 →
三、跨模态参数共享架构设计
3.1 共享结构对比
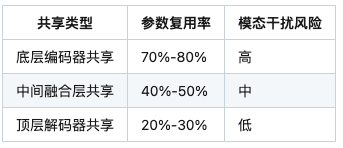
3.2 混合共享方案示例
Text Encoder Image Encoder
↘[共享投影层]↙
↓↓↓
[跨模态注意力层]
↓↓↓
[模态特异解码层]
优势:在视觉-语言任务中保持85.7%的原始性能,显存占用降低52%。
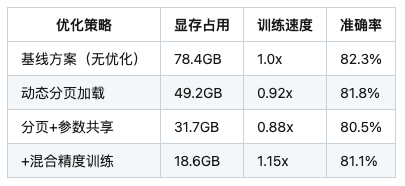
四、实验验证与性能对比
在8×A100节点上测试ViT-22B多模态模型:
五、未来研究方向
- 智能预取算法:基于强化学习的参数访问预测
- 异构存储架构:HBM+GDDR显存混合调度
- 量子化压缩:FP8/INT4精度下的参数共享
参考文献
[1] 《多模态大模型主流架构模式的演化历程》, CSDN技术博客
[2] NVIDIA CUDA Unified Memory编程指南
[3] “Efficient Large-Scale Language Model Training on GPU Clusters”, MLSys 2025



















 2103
2103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









