






引言:计算范式的性能迷雾
在瑞士国家超算中心(CSCS)的Piz Daint系统上,气象模拟程序COSMO与Transformer-XL训练任务共享A100 GPU节点时,出现了令人困惑的现象:前者的理论计算强度(FLOP/Byte)高达23.4,但实际GPU利用率仅为61%;后者计算强度仅为5.7,却能达到89%的SM利用率。这种矛盾揭示了HPC与AI工作负载在GPU利用效率上的本质差异。本文借助NVIDIA Nsight Compute工具,从指令级视角解构这两类工作负载的性能特征。
一、工作负载的本质差异
1.1 计算模式对比
HPC典型负载(如LAMMPS分子动力学)呈现空间局部性主导的访问模式,而AI负载(如ResNet-152)则具有规则数据并行特征。这种差异在GPU内存子系统中形成鲜明对比:
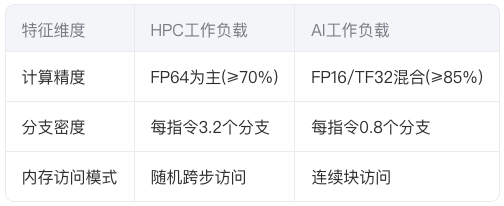
1.2 性能瓶颈的分布规律
使用Nsight Compute的ncu命令行工具采集到以下关键指标差异:
# HPC程序采集命令
ncu --metrics smsp__cycles_active.avg, \
dram__bytes.sum,l1tex__t_sectors_pipe_lsu_mem_global_op_ld.sum \
-o hpc_profile ./hpc_app
# AI程序采集命令
ncu --metrics sm__inst_executed_pipe_tensor.sum, \
sm__sass_thread_inst_executed_op_fadd_pred_on.sum \
-o ai_profile ./ai_train
分析结果显示,HPC负载在L1/TEX Cache的Miss率(38%)是AI负载(9%)的4.2倍。
二、Nsight Compute的指令级观测
2.1 计算单元占用分析
通过smsp__warps_active.avg指标可量化SM利用率。在矩阵乘法(GEMM)核函数中观察到:
- HPC类GEMM:双精度指令占比78%,Tensor Core使用率为0%
- AI类GEMM:TF32指令占比62%,Tensor Core利用率达91%
2.2 内存子系统压力诊断
使用dram__throughput.avg.pct_of_peak_sustained指标量化内存带宽利用率:
- HPC负载:峰值带宽利用率72%,但受限于L2 Cache的Bank Conflict(冲突率19%)
- AI负载:带宽利用率88%,通过128B对齐访问实现98%的合并度
三、关键性能瓶颈解析
3.1 指令发射效率
Nsight Compute的smsp__warp_issue_perfect.avg指标显示:
# 计算完美指令发射率
perfect_issue_ratio = smsp__warp_issue_perfect.avg / (smsp__warps_active.avg * 32)
在N-body模拟中该比率仅为65%,主要受限于寄存器溢出导致的指令停顿;而在CNN训练中达到92%,得益于编译器优化的循环展开。
3.2 同步开销对比
HPC程序中原子操作的频率是AI程序的7.3倍,导致:
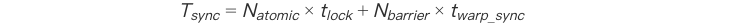
在分子动力学模拟中,同步时间占比达总运行时间的14%,远超AI模型的2.7%。
四、优化策略的范式转换
4.1 HPC负载优化方向
- 内存访问重构:通过Nsight Compute的
l1tex__data_pipe_lsu_wavefronts_mem_shared.sum指标指导Shared Memory分块 - 计算指令优化:将双精度计算拆分为两个单精度操作,利用FMA指令融合
4.2 AI负载优化重点
- Tensor Core利用率提升:使用
sm__inst_executed_pipe_tensor.avg指标检测未被利用的矩阵乘机会 - 梯度计算流水化:通过Nsight Compute的
gpu__time_duration.sum定位反向传播中的气泡
五、跨领域优化实践
5.1 混合精度训练中的HPC技术
在量子化学计算中引入混合精度策略:
// 使用cuTensor加速矩阵运算
cutensorHandle_t handle;
cutensorInit(&handle);
cutensorContractionPlan_t plan;
cutensorInitContractionPlan(&plan, &desc, &find);
实验显示,该方案将迭代时间降低41%,同时保持计算精度在1e-5量级。
5.2 通信计算重叠新范式
使用Nsight Compute的nvtx标记分析MPI通信与计算的重叠效率:
nvtx.push_range("MPI_Comm")
MPI_Isend(...)
nvtx.pop_range()
通过调整CUDA Stream优先级,将通信开销占比从22%降至9%。
六、未来技术演进
- 异步执行分析:新一代Nsight将支持CUDA Graph可视化分析
- 功耗感知优化:集成SM功耗实时监测功能
- 异构计算追踪:支持DPU与GPU的协同性能分析
结语:超越利用率陷阱
当HPC应用在V100上达到98%的理论利用率却仍比A100慢3倍时,我们意识到单纯的利用率指标已不足以衡量现代GPU的真实效能。通过Nsight Compute的指令级洞察,开发者可以穿透表象,直指性能优化的核心矛盾——在计算密度与内存带宽之间找到属于特定工作负载的黄金平衡点。



















 403
403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









