







 本文对比了2010年Rafael Corezola Pereira提出的跨语言剽窃检测方法,该方法通过语言标准化、候选文档检索、特征选择与分类器训练等步骤,达到了86%的跨语言性能。同时,它与2011年何文垒的研究相比较,着重于使用语义哈希进行文本特征提取,尤其是基于词义密度的名词消歧。这两种方法都关注外在剽窃检测,但后者采用的基于WordNet的相似度计算方法缺乏创新性。
本文对比了2010年Rafael Corezola Pereira提出的跨语言剽窃检测方法,该方法通过语言标准化、候选文档检索、特征选择与分类器训练等步骤,达到了86%的跨语言性能。同时,它与2011年何文垒的研究相比较,着重于使用语义哈希进行文本特征提取,尤其是基于词义密度的名词消歧。这两种方法都关注外在剽窃检测,但后者采用的基于WordNet的相似度计算方法缺乏创新性。
对比文件1: 2010年的跨语言剽窃检测新方法
作者RaFael Corezola Pereira
instituion : UFRGS
摘要:
作者提出一个跨语言剽窃检测新方法,分为5个主要阶段: languange normalization、retrieval of candidate documents、classfier training、plagiarism analysis 、post processing
在摘要中作者还说明手动构建一个数据集,并且比较单语上的和跨语言的(跨语言上达到单语的baseline上的86%的perfomance),并且分析剽窃文本的长度是否会影响方法的性能。指出在长篇或者中篇上性能比较好;
1 Introduciton
跨语言剽窃: 词义的改写 、 词序;所以跨语言剽窃很难被检测到
cross-language plagiarism can also involve self-plagiarism
本文目的提出CLPA(cross-Language plagiarism Analysisi)
作者说他们的方法主要不同点就是用到一个分类算法,区别剽窃文本和非剽窃文本
tow areas:
- extrinsic plagiarism analysis: use a reference collection
- intrinsic plagiarism analysis without reference collection,这种方式经常考虑的是写作被怀疑的文档的写作风格
本文中,关注的是extrinsic plagiarism检测.
作者用到一个自动翻译工具,把suspicious 和 source documents翻译到一种公共语言,for analyze them in a uniform way
在normalization phase, 作者用一个分类算法构建一个模型,学习plagiarized和non-plagiarized text passage的区别。
作者使用信息检索系统检索那些suspicious documents
人工构建EClaPa数据集。 基于Euoparl Parallel Corpus
3 The Method
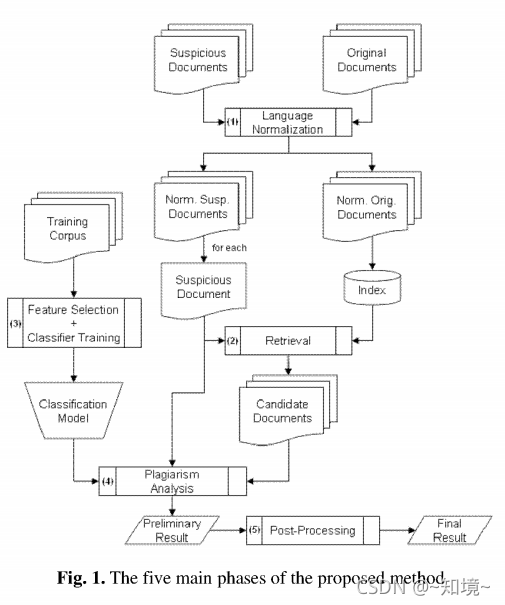
3.1 language Normalization
把seveal language document 转成一种common language. 默认用英语;因此用到翻译工具,before translating, the language in which each document was written is identified using a language guesser.
3.2 Retrieval of Candidate Documents
从信息检索系统捞出那些suspicous document;
作者说明在整个参考文件的collection中检索suspicious document是not feasible。只能检索其中a small subset of the collection
把original document切分几个subdocuments,然后索引化
split and indexed the reference collection。系统就能够查询检索candidate subdocuments. suspicious document也被分成几个部分,用来查询index.
3.3 feature selection and classifier training
分类器吃进一个suspicious passage和 one of the candidate subdocuments
(1)cosine similarity: 不考虑词序,
(2)similarity score: IR系统与candidate subdocument
(3)the rank about candidate subdocument
(4)the length of suspicious and the candidate subdocument
3.4 plagiarism analysis
根据第3.3的分类器,
3.5 post -processing 结果
为了实现连续检测,确实suspicious是抄袭基本部分还是一个整体,所以作者用到启发式方法。
二、关于对比文件2的思路梳理
作者:何文垒
2011年12月 上海交通大学
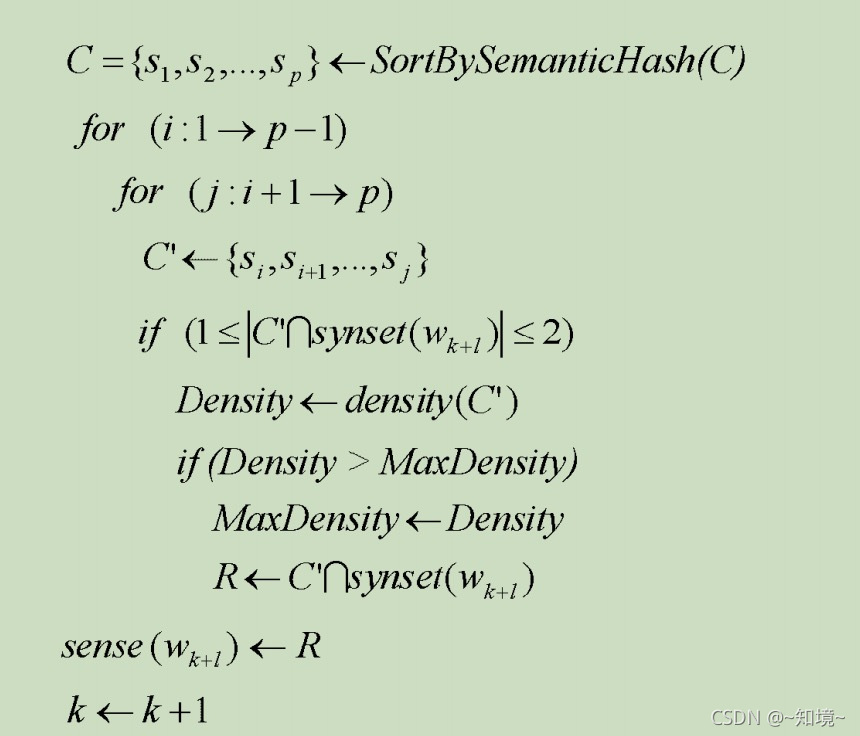
从所给的算法可以看出先对文本进行求语义hash
作者的消歧用语义哈希来做,基于wordnet语义密度的名词消岐
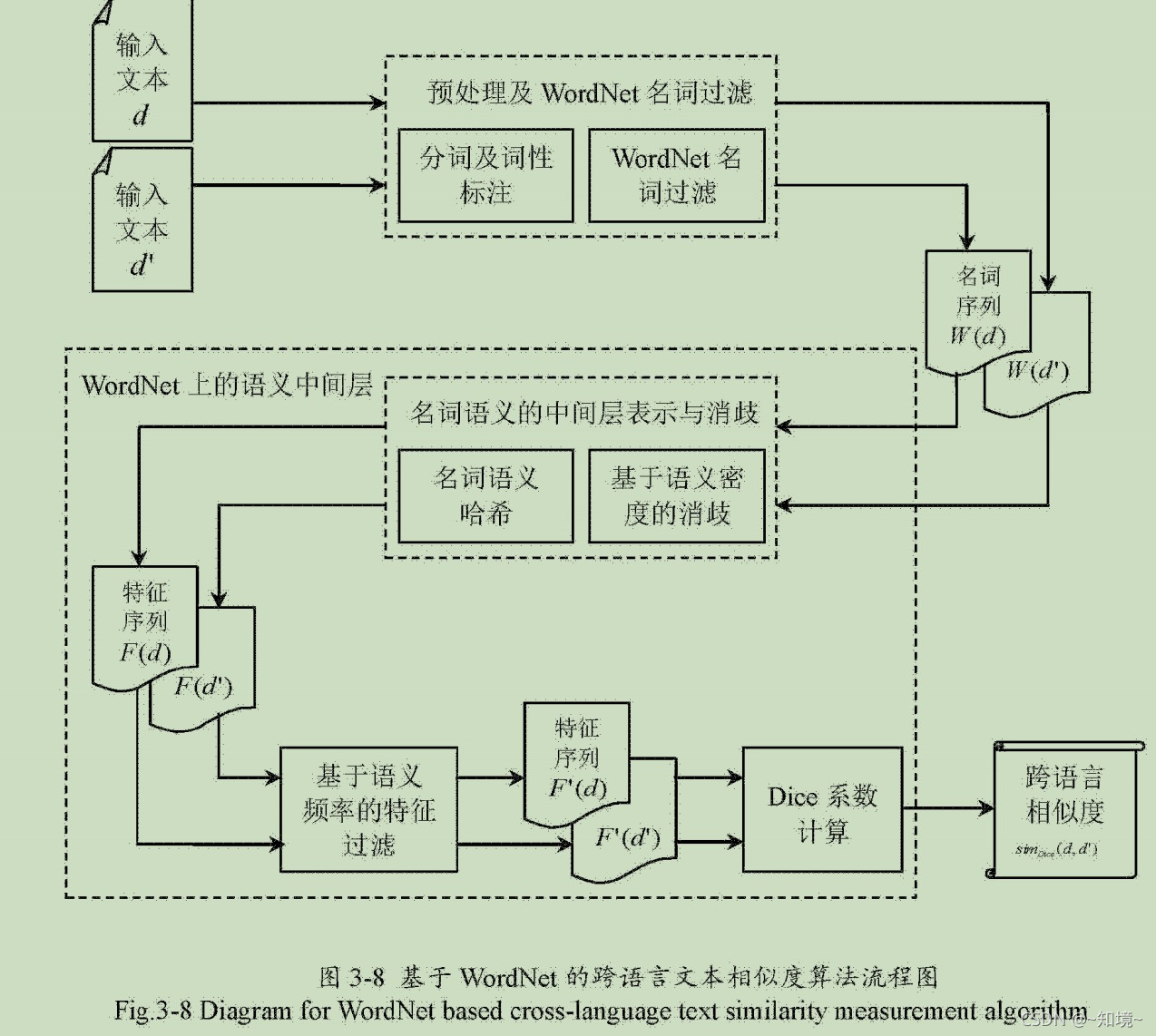
跨语言文本相似度计算:
提取特征部分:
1.作者简历语义中间层,将输入文本映射到语义中间层
基于语义频率的特征过滤方法
作者只提名词特征
作者对文本预处理,取出其中标点、html标记;
分词、词性标注,得到名次
在wordnet查找名词得到名词序列 W(d) = {1,2,3,… n}
how:
建立语义中间层
将输入的文本映射到语义中间层
提取输入文本的特征
对特征进行过滤
相似度计算
3.4.2 基于语义频率的特征过滤
向量空间模型计算monolingual文本相似度方法, tf-idf加权向量
作者说,文本的特征是以名词语义哈希序列的形式来表现
语义频率: 一个词在document出现多次,它的词义哈希必然也会出现多次,所以有tf类似的信息
3.4.3 相似度计算
A语言的输入样本d 哈希序列特征为:F(d)= {}
B语言输入样本d'. F(d')
用的是Dice系数

专家评审意见:
1. 特征的构建
专家意见说: 对比10年的论文,专家指出李的论文做法

并指出:李的做法是常用做法,没有创新性;
2.检测跨语言剽窃:
专家意见: wordnet做法与提交专利相同,不具备创新性
专家说与对比文件2 的基于WordNet的中英文跨语言文本相似度研究 何的论文
答复第1点
李光曦的论文要点

第3章 基于多特征的跨语言剽窃分类
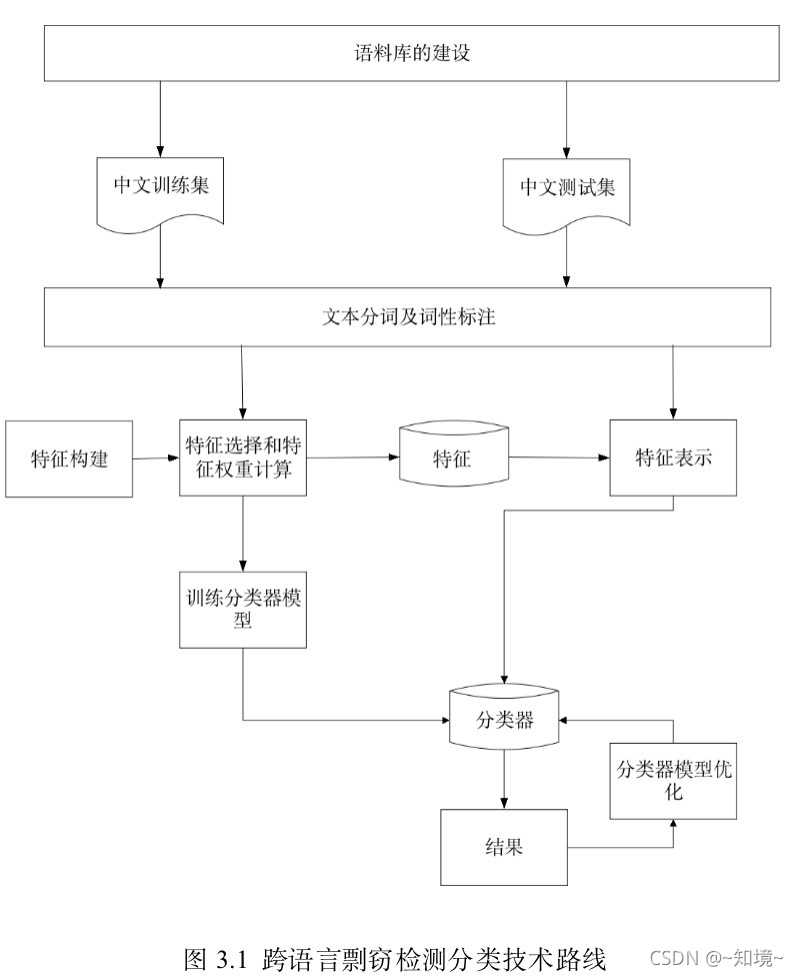
3.1 语料库的建设与文本预处理
1.翻译得到语料集
2.原创性中文文章
中文的文本---- 分词与pos---- 处理后的文本集合
分词用的是NLPIR2016 处理 pos
翻译欧化的问题:-----》 构建特征
3.2 特征构建与选择(这一块是重点,要向专家汇报不同,特别注意,反复思考,专家说这一个与提供的两篇对比论文相同,不具备创新性,所以要解释清楚)
特征构建方面,作者针对七种
特征选择:
卡方检测没考虑词频,较低的且在类别中不稳定的特征
1) 改进卡方检测
1.计算tf, 每个特征项在每篇文档中的频数tf1、tf2…tfm
3.3 SVM(分类模型构建,可以看做是对比文件)
第4章 基于特征对应的跨语言剽窃检测
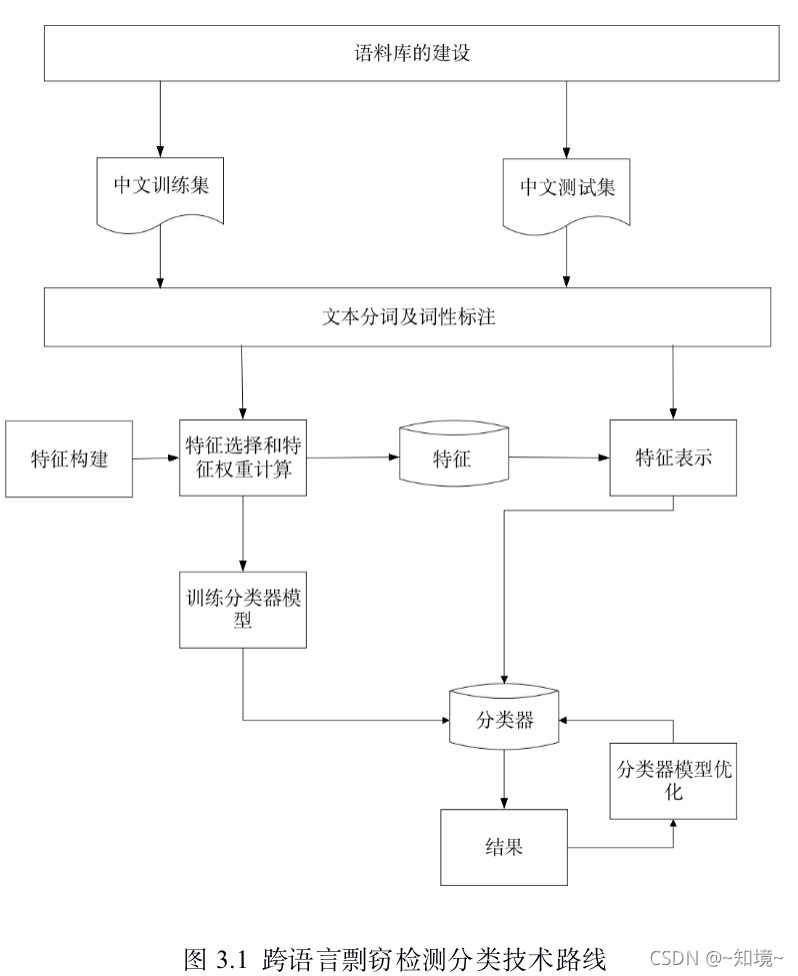
4.1 段落的自动划分与英文词性标注
pdf转成xml格式,切分成段落进行分析,多线程进行文档的批处理
师兄提出算法:基于标签的***过滤与段落合并算法
针对专家说的预处理方法,把pdf转成xml格式进行辩述
4.2 基于译文特征对应的剽窃结果第1次过滤译文
翻译欧化问题:
根据中英文特征出现的位置,选择37个有效特征,
中文与en可能有1:n的情况,因此
5 段落之间的距离计算方法:
段落 是由句子组成,然后看确定的特征在每个句子有多少
先确定37个特征在句子中的存在情况
得到句子表示
然后计算段落距离
-基于4.2 得到了中英文段落之间的距离,因此会得到一个集合 中文剽窃英文, 英文是目标 中文是源, 第三章是构建特征 4.2根据上述译文特征 表示句子 由此可得到段落的表示,最后计算cn-en之间段落的距离,然后根据cn的一个段落, en可能有多个段落与之距离比较小,这样就得到一个en集合
4…3 基于结构特征对应的剽窃结果第2次过滤
结构特征: 句子的长度,句子中noun的长度、句子中动词的长度、形容词的长度、副词的长度
4.4 wordnet的对剽窃结果确认
引入Wordnet的跨语言文本相似度计算方法对4.2 和4.3的结果在确认,
本文基于中英文wordnet词典,通过名词语义hash建立中间指纹编码,将两种语言共同映射到同一种数值空间上,进行相似度比较
1) 先进行编码,对wordnet名词同义词进行中间指纹编码-- 把名词同义词集映射到同一个数值空间
2)消歧 基于语义密度,
3) 指纹选取与相似度计算
取出分辨率较大的指纹进行相似度计算 tf-idf算法算去指纹
多次出现的名词 tf大 保留
idf

















 2560
2560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









