









awk简介
awk是一种用于处理数据和生成报告的UNIX编程语言。处理的数据可以来自标准输入、一个会多个文件,也可以来自某个进程的输出。awk以逐行方式扫描文件(或输入),从第一行到最后一行,以查找匹配某个特定模式的文本行,并对这些文本执行(括在花括号中的)指定动作,如果只给出模式而未指定动作,则所有匹配该模式的行都显示在屏幕上;如果只指定动作而未定义模式,会对所有输入行执行指定动作。
awk格式
awk程序由awk命令、括在引号(或写在文件)中的程序指令以及输入文件的文件名几部分组成,若未指定输入文件,则输入来自标准输入,即键盘。
awk指令由模式、操作或者模式与操作组合组成,模式是由某种类型的表达式组成的语句,模式不能被括在大括号中,模式由括在两个正斜杠之间的正则表达式、一个或多个awk操作符组成的表达式组成;操作由括在大括号内的一条或多条语句组成,语句之间用分号隔开。
格式一
[root@db1 ~]# awk 'pattern' filename
[root@db1 ~]# awk '{action}' filename
[root@db1 ~]# awk 'pattern {action}' filename
示例1:打印包含Felix的行
[root@db1 shell_stu]# cat emp.txt
0001 Alen M 24
0002 Tiboo M 32
0003 Felix M 26
0004 Jack F 24
0005 Tim M 25
0006 Audi F 30
0007 Bobo F 32
0008 Geo M 21
0009 Andy F 19
00010 Peter M 28
[root@db1 shell_stu]# awk '/Felix/' emp.txt
0003 Felix M 26
[root@db1 shell_stu]#
示例2:打印第2列
[root@db1 shell_stu]# awk '{print $2}' emp.txt
Alen
Tiboo
Felix
Jack
Tim
Audi
Bobo
Geo
Andy
Peter
示例3:打印包含Alen行的第2和4字段
[root@db1 shell_stu]# awk '/Alen/{print $2,$4}' emp.txt
Alen 24
格式二
[root@db1 ~]# command | awk 'pattern'
[root@db1 ~]# command | awk '{action}'
[root@db1 ~]# command | awk 'pattern {action}'
示例1:打印磁盘可用空间大于等于2561100的行
[root@db1 ~]# df | awk '$4 >= 2561100'
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sda1 14317576 6664348 6902892 50% /
/dev/sda2 3997376 1210180 2561100 33% /u01
示例2:打印/etc/passwd文件中mysql行的第6列
[root@db1 ~]# cat /etc/passwd |awk -F : '/mysql/{print $6}'---F表示字段分隔符
/home/mysql
awk工作原理
测试数据为:
[root@db1 shell_stu]# cat emp.txt
0001 Alen M 24
0002 Tiboo M 32
0003 Felix M 26
0004 Jack F 24
0005 Tim M 25
0006 Audi F 30
0007 Bobo F 32
0008 Geo M 21
0009 Andy F 19
00010 Peter M 28
执行命令为:
[root@db1 shell_stu]# awk '{print $2,$4}' emp.txt
Alen 24
Tiboo 32
Felix 26
Jack 24
Tim 25
Audi 30
Bobo 32
Geo 21
Andy 19
Peter 28
1)awk使用一行作为输入,并将该行赋给内部变量$0,默认时每一行也称为一个记录,以换行符结束;
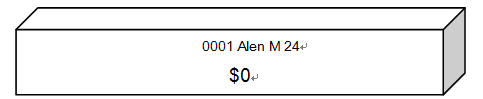
2)然后,行被分解成字段,每个字段存储在已编号的变量中,从$1开始;

3)awk通过内部变量FS来确定字段的分隔符,初始值FS为空格--包含制表符和空格符,如果需要使用其他字段分隔符,则需将FS设为新的字段分隔符;
4)awk打印字段时,将以{print $2,$4}方式使用print函数;
5)awk输出之后,将从文件中获取另一行,并将其存储到$0中,覆盖原来的内容,然后将新的字符串分割为字段并进行处理,直到整个文件所有行处理完毕。
格式化输出
print函数
awk命令的操作部分放在大括号内,若未指定操作,则匹配模式时,awk会采取默认形式,即在屏幕上打印。可以使用{print}形式显式调用print函数,print函数的参数可以是变量、数值或字符串常量。字符串必须用双引号括起来,参数之间用逗号分隔。
[root@db1 shell_stu]# date | awk '{print "Today is " $1 ,", Month is " $2, ", Year is "$6}'
Today is Mon , Month is Mar , Year is 2018
--使用转义\n表示换行
[root@db1 shell_stu]# date | awk '{print "Today is " $1 ,"\nMonth is " $2, "\nYear is "$6}'
Today is Mon
Month is Mar
Year is 2018
--利用制表符\t打印输出
[root@db1 shell_stu]# awk '/Alen/{print "\t\tHave a nice day ,"$2" !"}' emp.txt
Have a nice day ,Alen !
printf函数
--%表示让printf做好准备,-表示左对齐,s表示字符串
[root@db1 shell_stu]# awk '/Alen/,/Felix/{printf "The ID is %-5s , Name is %-10s\n",$1,$2 }' emp.txt
The ID is 0001 , Name is Alen
The ID is 0002 , Name is Tiboo
The ID is 0003 , Name is Felix
文件中awk命令
若awk命令写在文件里,需用-f指定awk的文件名,后再加上所要处理的输入文件的文件名。
示例:若匹配到Felix,则打印Hello Felix,其他的打印第1,2,3列
[root@db1 shell_stu]# cat script.txt
/Felix/{print "Hello "$2}
{print $1,$2,$3}
[root@db1 shell_stu]# awk -f script.txt emp.txt
0001 Alen M
0002 Tiboo M
Hello Felix
0003 Felix M
0004 Jack F
0005 Tim M
0006 Audi F
0007 Bobo F
0008 Geo M
0009 Andy F
00010 Peter M
awk命令示例
测试数据
[root@db1 shell_stu]# cat emp.txt
0001 AleN M 24
0002 Tiboo M 32
0003 Felix M 26
0004 JacK F 24
0005 Tim M 25
0006 Audi F 30
0007 Bobo F 32
0008 Geo M 21
0009 Andy F 19
00010 Peter M 28
00011 Allen M 26
1、匹配整行
--显示以0001开始的行
[root@db1 shell_stu]# awk '/^0001/' emp.txt
0001 Alen M 24
00010 Peter M 28
00011 Allen M 26
--显示第二列中以大写字母开始,后跟一个或多个小写字母,最后一个字母为大写的行
[root@db1 shell_stu]# awk '$2~/^[A-Z][a-z]+[A-Z]/' emp.txt
0001 AleN M 24
0004 JacK F 24
2、匹配操作符~
--~用于匹配第2列以Al开头的行
[root@db1 shell_stu]# awk '$2~/^Al/' emp.txt
0001 AleN M 24
00011 Allen M 26
--匹配第2列以o结尾的行
[root@db1 shell_stu]# awk '$2~/o$/' emp.txt
0002 Tiboo M 32
0007 Bobo F 32
0008 Geo M 21
--匹配第2列不以o结尾的行
[root@db1 shell_stu]# awk '$2!~/o$/' emp.txt
0001 AleN M 24
0003 Felix M 26
0004 JacK F 24
0005 Tim M 25
0006 Audi F 30
0009 Andy F 19
00010 Peter M 28
00011 Allen M 26
3、打印第2,3列
[root@db1 shell_stu]# awk '{print $2,$3}' emp.txt
AleN M
Tiboo M
Felix M
JacK F
Tim M
Audi F
Bobo F
Geo M
Andy F
Peter M
Allen M
4、打印所有记录
[root@db1 shell_stu]# awk '{print $0}' emp.txt
0001 AleN M 24
0002 Tiboo M 32
0003 Felix M 26
0004 JacK F 24
0005 Tim M 25
0006 Audi F 30
0007 Bobo F 32
0008 Geo M 21
0009 Andy F 19
00010 Peter M 28
00011 Allen M 26
5、使用NF来保存记录的字段数
[root@db1 shell_stu]# awk '{print $0,"Number of fields is "NF}' emp.txt
0001 AleN M 24 Number of fields is 4
0002 Tiboo M 32 Number of fields is 4
0003 Felix M 26 Number of fields is 4
0004 JacK F 24 Number of fields is 4
0005 Tim M 25 Number of fields is 4
0006 Audi F 30 Number of fields is 4
0007 Bobo F 32 Number of fields is 4
0008 Geo M 21 Number of fields is 4
0009 Andy F 19 Number of fields is 4
00010 Peter M 28 Number of fields is 4
00011 Allen M 26 Number of fields is 4
6、模式与操作组合
--打印0001开头的第2、3列
[root@db1 shell_stu]# awk '/^0001/{print $2,$3}' emp.txt
AleN M
Peter M
Allen M
--第2列以T或F开头,打印第1、2、4列
[root@db1 shell_stu]# awk '$2~/^[TF]/{print $1,$2,$4}' emp.txt
0002 Tiboo 32
0003 Felix 26
0005 Tim 25
--若第4个字段大于25,则打印1、2、4列
[root@db1 shell_stu]# awk '$4>25{print $1,$2,$4}' emp.txt
0002 Tiboo 32
0003 Felix 26
0006 Audi 30
0007 Bobo 32
00010 Peter 28
00011 Allen 26
--如果第2列以oo结尾,则打印Hello,Tiboo
[root@db1 shell_stu]# awk '$2~/oo$/{print "Hello ,"$2}' emp.txt
Hello ,Tiboo
7、字段分隔符-F
--默认字段分隔符是空格,NF表示字段数
[root@db1 shell_stu]# cat /etc/passwd |grep tss| awk '{print NF}'
11
--指定字段分隔符为:
[root@db1 shell_stu]# cat /etc/passwd |grep tss| awk -F: '{print NF}'
--打印长度为3的行
[root@db1 shell_stu]# awk '$2~/^.{3}$/' emp.txt
0005 Tim M 25
0008 Geo M 21
8、范围匹配
[root@db1 shell_stu]# awk '/Felix/,/Audi/' emp.txt
0003 Felix M 26
0004 JacK F 24
0005 Tim M 25
0006 Audi F 30
--或者用NR指示行数
[root@strong shell_stu]# awk 'NR==3,NR==6' emp.txt
0003 Felix M 26
0004 JacK F 24
0005 Tim M 25
0006 Audi F 30
9、表达式运算
--第2列等于Audi并且4列大于25时打印该行,逻辑与操作
[root@db1 shell_stu]# awk '$2=="Audi"&&$4>25' emp.txt
0006 Audi F 30
--打印第4列小于等于25的行,逻辑非操作
[root@db1 shell_stu]# awk '!($4>25)' emp.txt
0001 AleN M 24
0004 JacK F 24
0005 Tim M 25
0008 Geo M 21
0009 Andy F 19
10、算术运算
[root@db1 shell_stu]# awk '/Felix/{print $2,$4+5}' emp.txt
Felix 31
11、条件运算符
[root@db1 shell_stu]# awk 'NR>=2&&NR<=4{print ($4>30?"High "$4:"Low "$4)}' emp.txt
High 32
Low 26
Low 24
12、赋值运算符
[root@db1 shell_stu]# awk 'NR==1{$2="Alen";print $2}' emp.txt
Alen
[root@db1 shell_stu]# awk 'NR==1{$2="Alen";print}' emp.txt
0001 Alen M 24
13、自定义变量
[root@db1 shell_stu]# awk '/Tim/{age=$4+5;print $0,age }' emp.txt
0005 Tim M 25 30
[root@db1 shell_stu]# awk '/Tim/{$5=$4+10;print}' emp.txt
0005 Tim M 25 35
14、内置变量
--NR表示行号,$NF表示最后一个字段
[root@strong shell_stu]# awk '$2=="Tim"{print NR,$1,$2,$NF}' emp.txt
5 0005 Tim 25
--忽略大小写{IGNORECASE=1}
[root@strong shell_stu]# awk '{IGNORECASE=1};$2=="alen"{print $0}' emp.txt
0001 AleN M 24
--RS表示换行符,print默认一个换行符,又加一个
[root@strong shell_stu]# awk 'NR==1,NR==3{print NR,$1,$2,$NF,RS}' emp.txt
1 0001 AleN 24
2 0002 Tiboo 32
3 0003 Felix 26
15、BEGIN和END模式
[root@strong shell_stu]# awk 'BEGIN{print "This is executed firstly "}/Tim/{print}' emp.txt
This is executed firstly
0005 Tim M 25
[root@strong shell_stu]# awk 'BEGIN{print "\t\t------------------------Employees-------------------\n"}\
NR==2,NR==4{print $0}' emp.txt
------------------------Employees-------------------
0002 Tiboo M 32
0003 Felix M 26
0004 JacK F 24
[root@strong shell_stu]# awk 'END{print "Number of fields is "NR}/Tiboo/,/Bobo/{print}' emp.txt
0002 Tiboo M 32
0003 Felix M 26
0004 JacK F 24
0005 Tim M 25
0006 Audi F 30
0007 Bobo F 32
Number of fields is 11
16、输出重定向
--文件名必须用双引号括起来
[root@strong shell_stu]# awk '/Tim/,/Bobo/{print $1,$2 > "res.txt"}' emp.txt
[root@strong shell_stu]# ll
total 8
-rw-r--r--. 1 root root 209 Mar 26 18:33 emp.txt
-rw-r--r--. 1 root root 29 Mar 26 19:10 res.txt
[root@strong shell_stu]# cat res.txt
0005 Tim
0006 Audi
0007 Bobo














 503
503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









