




1.问题与解决内容
遇到的问题
-
LLM 部署的资源瓶颈:LLM(如 GPT-3)的内存占用高达 350G,计算需求庞大,边缘设备难以支持。
-
低比特量化的性能衰减:现有 PTQ 方法(如 GPTQ、AWQ)依赖手工设计量化参数(如缩放因子、迁移强度),在 W2A16、W4A4 等极低比特场景下,量化误差显著,模型困惑度(PPL)骤升(如 GPTQ 在 LLaMA-13B 的 W2A16 量化中 PPL 达 3832)。
-
QAT 与 PTQ 的效率矛盾:QAT 虽精度高,但需 100k 样本和数百 GPU 小时(如 LLM-QAT),而 PTQ 虽高效(如 GPTQ 量化 LLaMA-13B 仅需 1 小时),但低比特时性能不足。
解决内容
-
提出 OmniQuant 框架:通过可学习权重剪裁(LWC) 和可学习等价变换(LET),动态优化量化参数,无需微调原始模型,在保持 PTQ 效率的同时,实现低比特量化下的高精度。
-
LWC 自适应调节权重极值:通过可学习参数 γ 和 β 动态调整权重剪裁阈值,降低量化难度,例如在 LLaMA-7B 的 W4A4 量化中,将 PPL 从 14.49 降至 11.26。
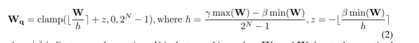
-
LET 转移激活量化挑战:通过通道缩放和偏移将激活异常值的量化难度转移到权重,结合块级误差最小化,在 W4A4 量化下使 LLaMA-7B 的零 - shot 任务平均准确率达 52.65%,超越 QAT 方法(LLM-QAT 为 46.43%)。
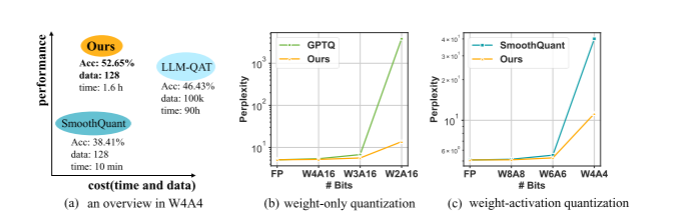 图b GPTQ(仅权重)在低比特表现不好 图c SmoothQuant(仅激活值)和OmniQuant
图b GPTQ(仅权重)在低比特表现不好 图c SmoothQuant(仅激活值)和OmniQuant
2. 背景
-
LLM 的重要性与挑战:LLM(如 GPT-4、LLaMA)在自然语言处理中表现卓越,但其数十亿至万亿参数量导致训练和推理需海量资源,阻碍实际应用。
-
量化技术的必要性:量化是压缩 LLM 的核心手段,分为 PTQ(无需训练,效率高)和 QAT
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 663
663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









