







目录
简介
Firebase 图像识别基于机器学习套件,用于识别图像中的文本,还可以定位出文本的坐标。
官方文档:https://firebase.google.com/docs/ml-kit/android/recognize-text?hl=zh-cn
接入
一、配置 Android 应用并下载 google-service.json 文件
配置步骤见本系列第一篇文章: Android Firebase接入(序)–Firebase简介以及Firebase官方Demo的使用中的 “配置Android应用并下载google-service.json文件”
二、添加依赖
- 项目级的 build.gradle 中,添加:
classpath 'com.google.gms:google-services:4.3.10'
- app 模块下的 build.gradle 中,添加:
plugins {
id 'com.google.gms.google-services'
}
dependencies {
...
implementation 'com.google.firebase:firebase-ml-vision:24.0.3'
}
三、开始图像识别
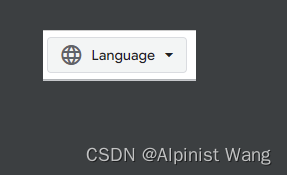
准备一张图片 image.png,放在 res/drawable/ 目录下(CSDN 的自动加水印功能着实不太友好,读者可以从下图中截个图,或者自备一张图):
MainActivity 中:
val image = FirebaseVisionImage.fromBitmap(BitmapFactory.decodeResource(resources, R.drawable.img))
val detector = FirebaseVision.getInstance().onDeviceTextRecognizer
detector.processImage(image)
.addOnSuccessListener { visionText ->
Log.d("~~~", "success: ${visionText.text}")
}.addOnFailureListener {
Log.d("~~~", "exception: ${it.message}")
}
首先,通过 FirebaseVisionImage.fromBitmap() 方法构建出 FirebaseVisionImage 对象,然后通过 FirebaseVision.getInstance().onDeviceTextRecognizer 获取到图像识别的检测器。
通过检测器的 processImage() 方法就能实现图像识别了。通过 addOnSuccessListener 方法添加识别成功回调,addOnFailureListener 方法添加识别失败回调。
成功的回调中,会包含一个 FirebaseVisionText 对象,这个对象中就有我们需要的信息。它的 text 属性就是识别出来的文字。
运行程序,可以看到 Logcat 控制台输出如下:
D/~~~: success: Language
这就是 Firebase 文字识别的一个最简单的例子。接下来我们看一下如何定位识别出的文字所在的坐标。
四、获取文字坐标
重新准备一张图片,将其放置到 res/drawable/ 文件夹下,命名为 img_1.png。这里以官方例子中的图片为例:

直接以上文的代码运行,Logcat 控制台输出如下:
D/~~~: success: NOTICE
SENSITIVE
WILDLIFE AREA
Please Stay on
Roads & Pathways
SHORELINE
A NEIY VIE
可以看到,准确率还是不错的,只有最后一行因为字有些模糊没有识别出来。FirebaseVisionText 对象的 text 属性中保存了识别出的所有文字。
读取 FirebaseVisionText 对象的其他属性:
val image = FirebaseVisionImage.fromBitmap(BitmapFactory.decodeResource(resources, R.drawable.img_1))
val detector = FirebaseVision.getInstance().onDeviceTextRecognizer
detector.processImage(image)
.addOnSuccessListener { visionText ->
Log.d("~~~", "success: ${visionText.text}")
visionText.textBlocks.forEach { block ->
Log.d("~~~", "block text: ${block.text}")
Log.d("~~~", "block frame: ${block.boundingBox}")
block.lines.forEach { line ->
Log.d("~~~", "line text: ${line.text}")
Log.d("~~~", "line frame: ${line.boundingBox}")
line.elements.forEach { element ->
Log.d("~~~", "element text: ${element.text}")
Log.d("~~~", "element frame: ${element.boundingBox}")
}
}
}
}.addOnFailureListener {
Log.d("~~~", "exception: ${it.message}")
}
FirebaseVisionText 的 textBlocks 属性中,按块保存了识别结果。每一块中,通过 lines 属性保存了每行的识别结果。每一行中,又通过 elements 属性保存了每个单词的识别结果。
block、line、element 都有 boundingBox 属性,它记录了识别出的对象所在的矩形位置。
运行程序,输出如下:
D/~~~: success: NOTICE
SENSITIVE
WILDLIFE AREA
Please Stay on
Roads & Pathways
SHORELINE
A NEIY VIE
D/~~~: block text: NOTICE
D/~~~: block frame: Rect(420, 823 - 985, 930)
D/~~~: line text: NOTICE
D/~~~: line frame: Rect(420, 822 - 984, 930)
D/~~~: element text: NOTICE
D/~~~: element frame: Rect(420, 822 - 984, 930)
D/~~~: block text: SENSITIVE
WILDLIFE AREA
Please Stay on
Roads & Pathways
D/~~~: block frame: Rect(322, 954 - 1069, 1250)
D/~~~: line text: SENSITIVE
D/~~~: line frame: Rect(434, 955 - 956, 1055)
D/~~~: element text: SENSITIVE
D/~~~: element frame: Rect(434, 955 - 956, 1055)
D/~~~: line text: WILDLIFE AREA
D/~~~: line frame: Rect(322, 1033 - 1066, 1119)
D/~~~: element text: WILDLIFE
D/~~~: element frame: Rect(322, 1042 - 788, 1119)
D/~~~: element text: AREA
D/~~~: element frame: Rect(818, 1033 - 1066, 1102)
D/~~~: line text: Please Stay on
D/~~~: line frame: Rect(496, 1122 - 909, 1189)
D/~~~: element text: Please
D/~~~: element frame: Rect(496, 1127 - 673, 1189)
D/~~~: element text: Stay
D/~~~: element frame: Rect(698, 1124 - 815, 1185)
D/~~~: element text: on
D/~~~: element frame: Rect(840, 1134 - 909, 1165)
D/~~~: line text: Roads & Pathways
D/~~~: line frame: Rect(426, 1173 - 981, 1249)
D/~~~: element text: Roads
D/~~~: element frame: Rect(426, 1184 - 605, 1238)
D/~~~: element text: &
D/~~~: element frame: Rect(635, 1183 - 666, 1242)
D/~~~: element text: Pathways
D/~~~: element frame: Rect(714, 1173 - 981, 1240)
D/~~~: block text: SHORELINE
A NEIY VIE
D/~~~: block frame: Rect(601, 1380 - 806, 1438)
D/~~~: line text: SHORELINE
D/~~~: line frame: Rect(601, 1379 - 804, 1414)
D/~~~: element text: SHORELINE
D/~~~: element frame: Rect(601, 1379 - 804, 1414)
D/~~~: line text: A NEIY VIE
D/~~~: line frame: Rect(604, 1409 - 782, 1438)
D/~~~: element text: A
D/~~~: element frame: Rect(604, 1415 - 622, 1431)
D/~~~: element text: NEIY
D/~~~: element frame: Rect(643, 1415 - 739, 1436)
D/~~~: element text: VIE
D/~~~: element frame: Rect(756, 1409 - 782, 1433)
其中,Rect 中的前两个数字代表文字所在的矩形框的左上角的坐标,后两个数字代表右下角的坐标。
查看 FirebaseVisionText 的源码可以发现,block、line、element 都继承自 TextBase 类:
static class TextBase {
private final String text;
private final Rect zzbrq;
private final Point[] cornerPoints;
private final Float confidence;
private final List<RecognizedLanguage> zzbsm;
...
}
所以它们三者的层级关系类似于文件夹和子文件夹、总公司和子公司的关系,这是一种组合模式的设计。
从源码中可以看到,三者不仅都有 text、zzbrq(也就是 boundingBox) 属性。还有 cornerPoints、confidence、zzbsm(也就是 recognizedLanguages) 三个属性。这三个属性的作用分别是:
- cornerPoints:文字所在矩形框的四个角的坐标集合,一共四个点。
- confidence:识别率
- zzbsm:识别出的文字中,包含的语言。
其中,cornerPoints 可以通过 boundingBox 计算出来,confidence 和 recognizedLanguages 笔者在测试时打印出来为空,由于这两个参数对我而言用处不大,所以我没有再去深究。
五、其他构造 FirebaseVisionImage 的方法
除了传入 Bitmap 之外,FirebaseVisionImage 还有一些构造方法。图片可以来自 Bitmap、media.Image、ByteBuffer、字节数组或文件。
- 传入通过相机拍摄的图片,及其旋转角度:
FirebaseVisionImage.fromMediaImage(mediaImage, rotation)
- 从图库中选择图片,传入 Uri:
FirebaseVisionImage.fromFilePath(context, uri)
- 从 ByteBuffer 或字节数组中创建 FirebaseVisionImage:
FirebaseVisionImageMetadata.Builder()
.setWidth(480) // 480x360 is typically sufficient for
.setHeight(360) // image recognition
.setFormat(FirebaseVisionImageMetadata.IMAGE_FORMAT_NV21)
.setRotation(rotation)
.build()
val image = FirebaseVisionImage.fromByteBuffer(buffer, metadata)
// Or: val image = FirebaseVisionImage.fromByteArray(byteArray, metadata)
- 通过 Bitmap 构建,本文中的例子就是用的这个方法:
val image = FirebaseVisionImage.fromBitmap(bitmap)
以上,就是 Firebase Vision Image 的基本使用。虽然讲得比较基础,但希望能起到一个引路的作用,具体使用建议参考官方文档。















 628
628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









